ACID
Atomicity, Consistency, Isolation, and Durability (ACID) are properties used to define databases and the guarantees that they offer. Traditionally, they’re associated with transactions, but transactions aren’t required for achieving ACID guarantees. For a complete overview of ACID components, check out Wikipedia’s article on ACID. We designed TileDB from the beginning to ensure ACID guarantees.
Atomicity
TileDB offers atomicity through how it handles writes by using commits. A commit ensures that any read operations can’t see write operations until TileDB writes a commit corresponding to a particular write operation. In TileDB, reads, writes, consolidation, and vacuuming are all atomic and will never lead to array corruption.
Reads
A read operation involves creating a query object and submitting the query (potentially many times for incomplete queries) until the query finishes. Each such read operation is atomic and can never corrupt the state of an array.
Visit Arrays Key Concepts: Reads for more information on reading data in TileDB.
Writes
A write operation involves the following steps:
- Creating a write query object.
- Submitting the query, potentially multiple times in the case of global writes.
- Finalizing the query object (important only in global writes).
Each such write operation is atomic, since TileDB’s design includes a set of functions that each thread treats atomically. Rather than having multiple threads submit the query for the same query object, TileDB creates separate query objects for the same array—even sharing the same context or array object—and prepares and submits them in parallel with each thread.
Two possible outcomes exist with writes:
- The write operation succeeds and creates a fragment that is visible to future reads.
- The write operation fails, and TileDB ignores any folders and files relevant to the failed fragment by default.
TileDB considers a fragment creation to be successful if a file <fragment_name>.ok appears in the array folder for the created fragment <fragment_name>. It is impossible for the reader to access a partially written fragment.
The user just needs to eventually delete the partially written folder to save space (that is, a fragment folder without an associated .ok file). Furthermore, each fragment is immutable, so it’s impossible for a write operation to corrupt another fragment created by another operation.
Consolidation
Consolidation entails a read and a write. Thus, it is atomic in the same way as reads and writes are atomic. It’s impossible for consolidation to lead to a corrupted array state.
Vacuuming
Vacuuming deletes consolidated fragment folders and array and fragment metadata files. Vacuuming always deletes the .ok files before erasing the corresponding folders. It is atomic in the sense that it cannot lead to array corruption. If the vacuuming process is interrupted, you can restart it without issues.
Consistency
TileDB’s consistency guarantees depend on the underlying storage system. TileDB handles eventually consistent systems by design, like some object stores. With read-after-write systems such as Amazon S3’s original design, TileDB handles consistency by ensuring that you can access only the writes with a corresponding commit. This ensures that every query, read or write, has a consistent view of the data, based on what TileDB finds when you open an array.
The concept of eventual consistency applies to both dense and sparse arrays. Suppose you perform two writes in parallel (by different threads or processes), producing two separate fragments. Assume also that a third thread or process performs a read query at some point in time, possibly in parallel with the writes. Five possible scenarios exist regarding the logical view at the time of the read (that is, five different possible read query results):
- The read query completes before either of the writes have completed.
- The read query completes after the first write completed but before the second write completed.
- The read query completes after the second write completed but before the first write completed.
- The read query completes after both writes, and the first write completes before the second write.
- The read query completes after both writes, but the second write completes before the first write.
The following figure illustrates each of these possible scenarios:
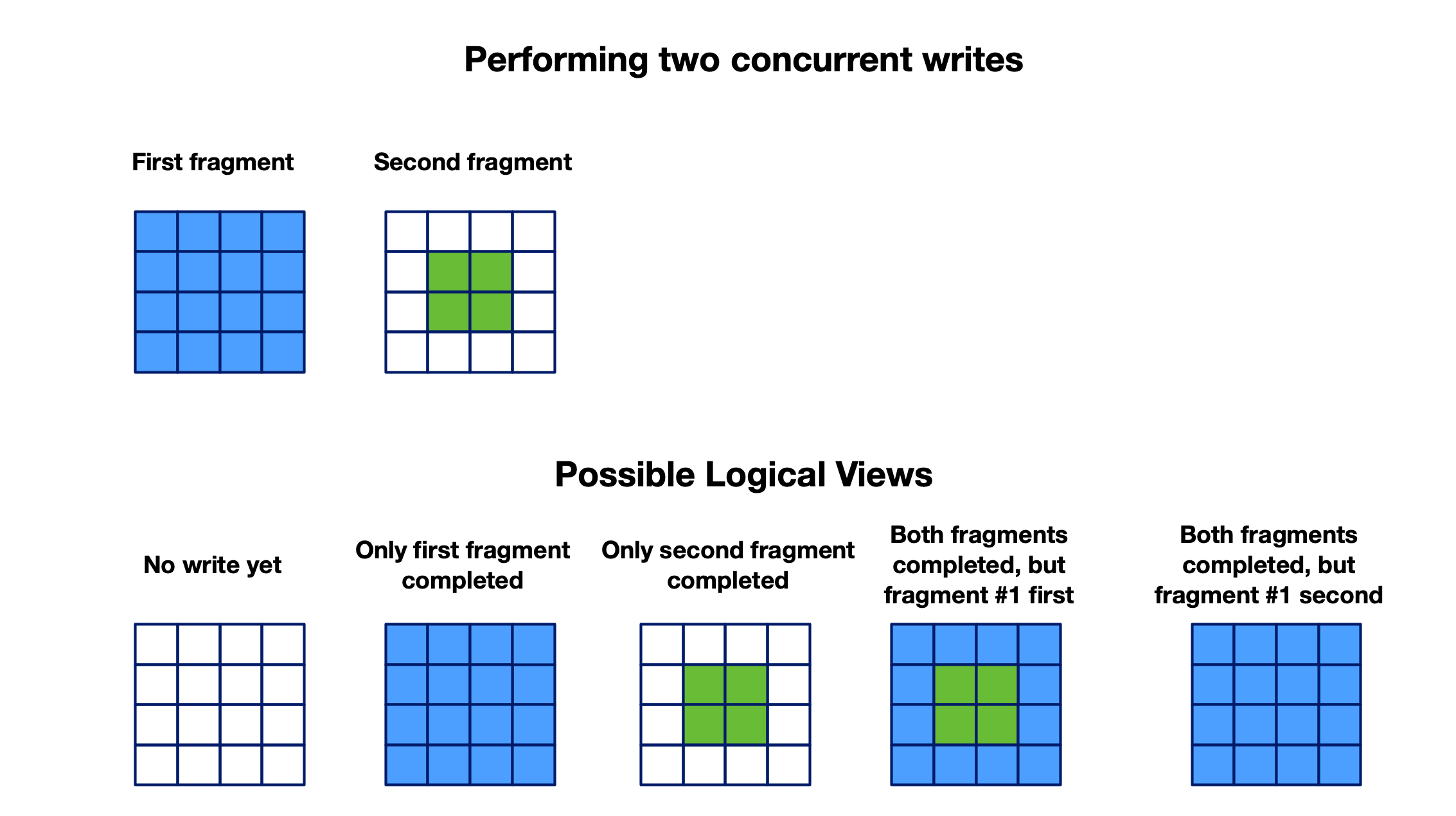
The concept of eventual consistency tells you that, eventually (that is, after all writes complete), every read query will show the latest collective global view of the array (that is, the view incorporating all writes). The order of the fragment creation will determine which cells overwrite others, which greatly affects the final logical view of the array.
Eventual consistency allows high availability and concurrency. Cloud object stores follow this model. Thus, TileDB is ideal for integrating with such distributed storage backends. If you require strict consistency for some application (for example, similar to that in transactional databases), then you must build an extra layer on top of TileDB to enforce additional synchronization.
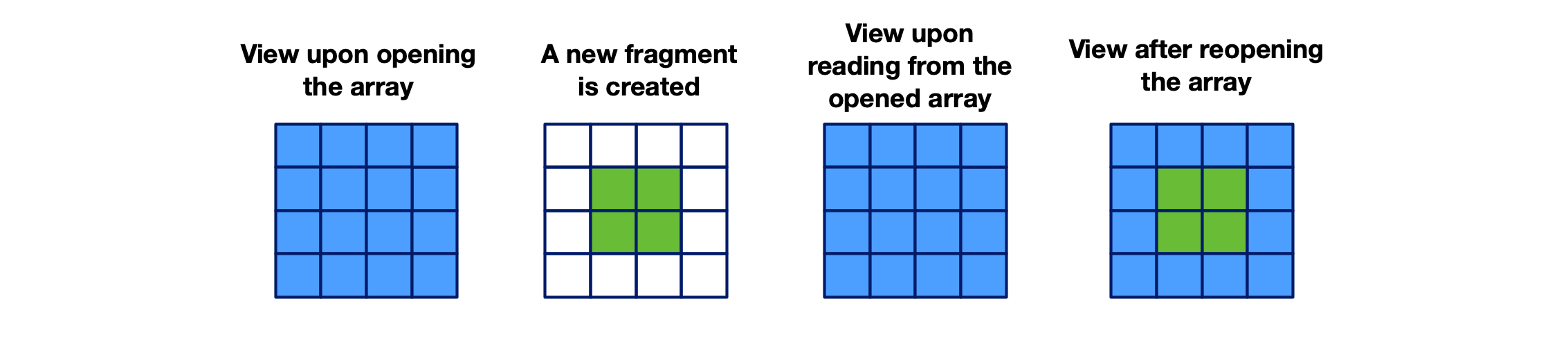
But how does TileDB deal internally with consistency? The answer to this question involves when you open the array (either at the current time or at a time in the past). Upon opening an array, TileDB takes a snapshot of the already completed fragments. This is the view of the array for all queries that use the opened array object. If writes occur (or complete) after you opened the array, any read queries that use the opened array will not see the new fragments. If you wish to see the new fragments, you’ll need to either open a new array object and use that one for new queries, or reopen the array, which bypasses the closing step, allowing some performance optimizations.
The following figure illustrates this. The first view of the figure depicts the logical view when opening the array. Next, suppose a write occurs after you open the array that creates a new fragment, depicted by the second view. If you attempt to read from the opened array, even after TileDB creates the new fragment, you won’t see the updates that occurred between opening and reading from the array. You would see something similar to the first view, which the third view also depicts. After closing and reopening the array, you’ll see the most up-to-date array view, depicted by the fourth view.
When you write to a TileDB array with more than one process, make sure that the machine clocks are synchronized, if your application is synchronizing the writes across machines. This is because TileDB sorts the fragments based on the timestamp in their names, which is calculated based on the machine clock.
The following steps show how TileDB reads achieve eventual consistency on cloud object stores:
- Upon opening the array, list the fragments in the array folder.
- Consider only the fragments that have an associated
.okfile. The ones that do not have one are either in progress or not visible due to the cloud object store’s eventual consistency. - TileDB
PUTs the fragment data and metadata files in the fragment folder. - If the previous step succeeded, TileDB then
PUTs the.okfile in the fragment folder. - TileDB performs any access inside the fragment folder with a byte range
GETrequest, never withLIST.
Amazon S3, for example, has a strong read-after-write consistency guarantee, meaning those GET requests are guaranteed to succeed.
Thus, a read operation will always succeed and never be corrupted (that is, it will never have results from partially written fragments). That being said, it will only consider the fragments that your cloud object store makes visible in their entirety at the timestamp of opening the array.
Isolation
TileDB uses multiversion concurrency control to ensure isolation between operations in a lock-free manner. As described in Arrays Foundation: Writes, every write is immutable. This ensures that one write operation doesn’t affect any ongoing read operations. Additionally, TileDB’s use of fragments provides an LSM-tree-like structure, which is a well-known pattern for ensuring isolation without the need for locking.
Durability
Durability guarantees come from the atomic writes in TileDB with its use of commits. A commit is the last step in a write operation, and TileDB performs commits in an atomic manner, based on the underlying storage system. TileDB guarantees that once data is committed, it will endure. TileDB’s use of multiversion concurrency control and fragments offers durability by ensuring that it never updates or appends data to an existing file. TileDB writes any file stored inside it exactly once.