Fragments
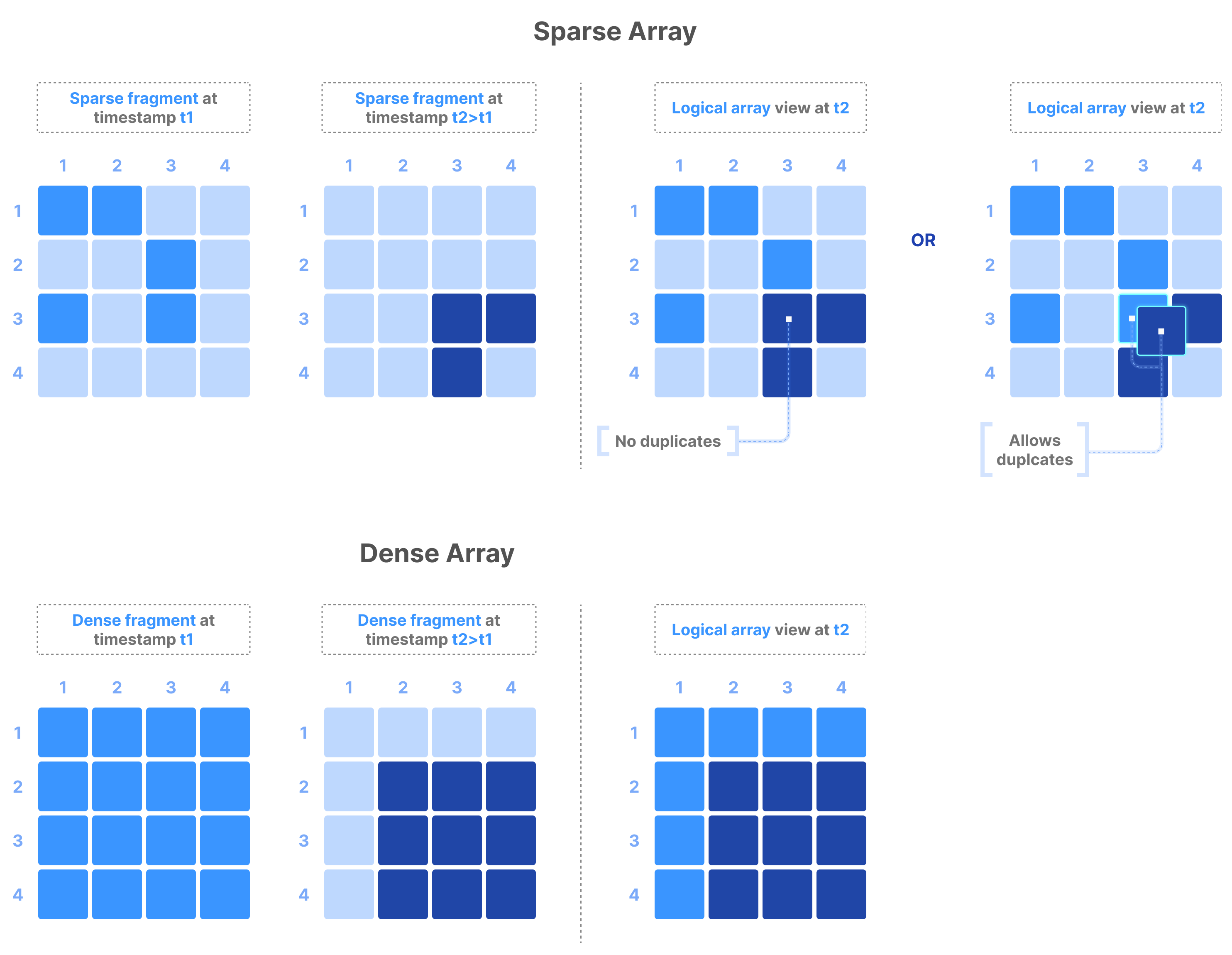
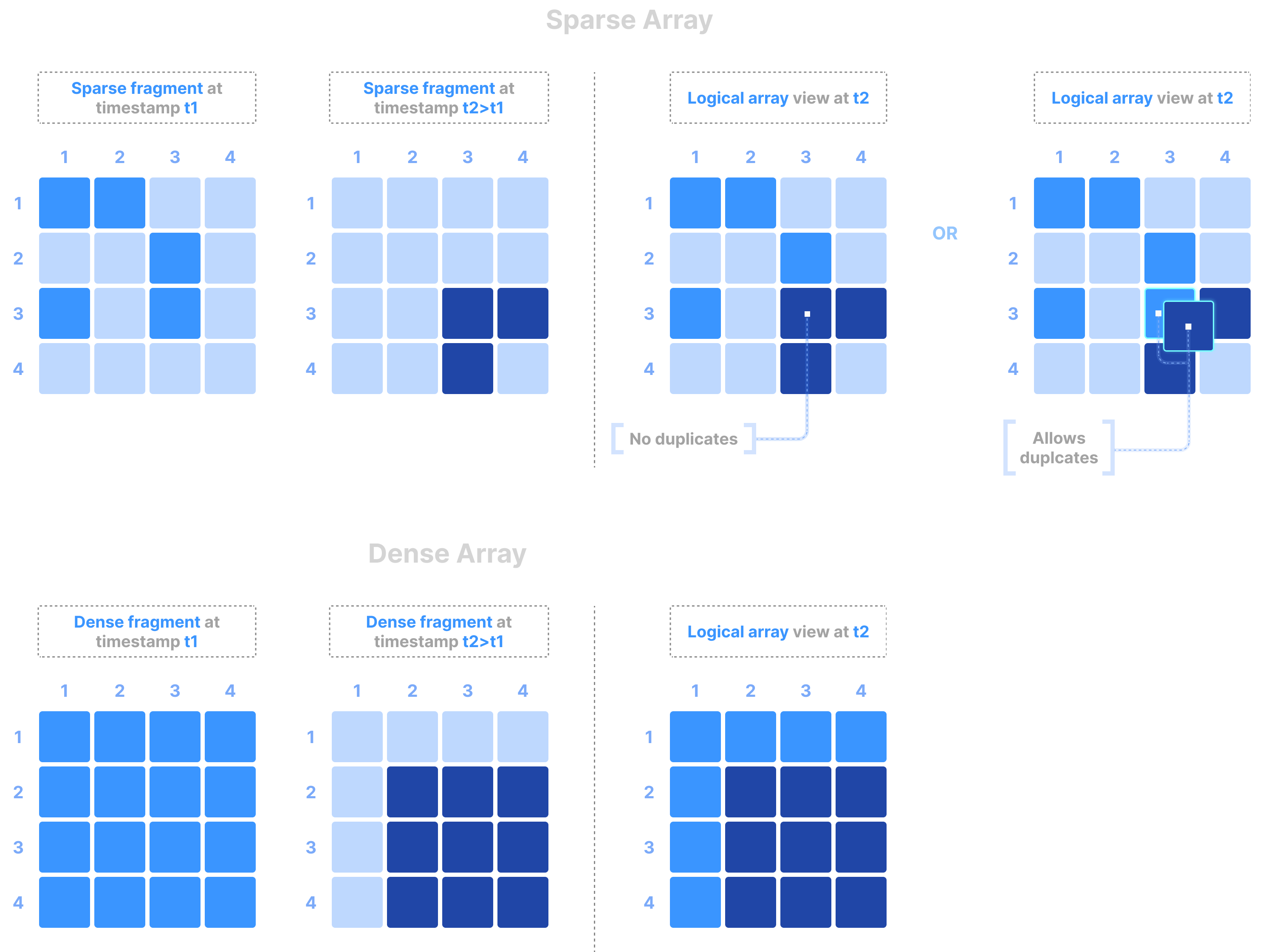
A fragment represents a timestamped write to a TileDB array. The figure below shows writes performed in a dense and a sparse array at two different timestamps, t1 and t2 > t1. The logical array view when the user reads the array at any timestamp t3 >= t2 contains all the cells written in the array before t3, with the more recent cells overwriting the older cells. In the special case of sparse arrays that accepts duplicates (which can be specified in the array schema), if a cell was written more than one time, all cell replicas are maintained and returned to the user upon reading.
Each fragment is a timestamped subfolder inside the array folder (under subfolder __fragments). It contains all the separate files for each written attribute (and coordinates in the case of sparse arrays). It also stores a special file for the fragment metadata, which makes each fragment self-contained (i.e., it includes all the necessary information for TileDB to perform efficient reads on fragments). Visit the Storage Format Spec section for more details on how TileDB implements fragments on storage.
TileDB is architected specifically so that writing fragments is atomic and consistent, supporting multiple concurrent readers and writers. This is possible via the concept of commit files, which effectively allow TileDB to consider a fragment in a read operation only if the corresponding write operation is guaranteed to have successfully finished.
Fragments enable TileDB to implement an LSM tree-like approach to writing, where all generated files are immutable. This is critical for performance, especially on object stores, where all files/objects are immutable as well. However, numerous write operations may lead to a large number of fragments, which may adversely impact the read performance. To mitigate this, TileDB implements an efficient consolidation mechanism, which compacts multiple fragments into fewer fragments.