Array Reads
This section covers all the internal mechanics behind TileDB reads.
Basics
TileDB supports fast and parallel subarray reads, with the option to time travel (that is, to read the array selecting over the past writes based on time ranges). The read algorithm is architected to abstract all the complexity behind the writes and the storage format (for example, the fragments, indexing, and so on), efficiently and completely transparently from the user. To read an array, TileDB first “opens” the array and brings some lightweight fragment metadata in main memory. Using this metadata, TileDB knows which fragments to ignore and which to focus on (for example, based on whether their non-empty domain overlaps with the query subarray, or whether the fragment was created at or before the time of interest). Moreover, in case consolidation has occurred, TileDB is smart enough to ignore fragments that have been consolidated, by considering only the merged fragment that encompasses them.
When reading an array, the user provides:
- A single- or multi-range subarray (the default is the entire array).
- The attributes to slice on (it can be any subset of the attributes, including the coordinates in sparse arrays, the default is all attributes if none is specified).
- A time range for time traveling (optional, the entire time range is the default).
- An aggregate condition (optional, no condition is the default).
- A query condition on attributes (optional, no condition is the default).
- The layout with respect to the subarray to return the result cells in (supported in some of the TileDB APIs, such as C++).
At a very high level, the read algorithm proceeds as follows:
- It first lists all the commits, and determines which fragments to focus on based on their timestamps and whether they have been consolidated into another fragment.
- It fetches the metadata from the selected fragments, and determines if any of the fragments can be skipped altogether (e.g., using their non-empty domain).
- From the fragment metadata (which contain tile indexing information), it determines which tiles are relevant to the query slice (e.g., if their boundaries overlap with the query).
- It fetches the relevant tiles from storage in parallel, efficiently decompresses these tiles, then filters the cells and assemble the final result (all using multi-threading).
TileDB’s lock-free multiple writer/multiple reader model supports concurrent reads.
The next two subsections delve into some more details for reading dense and sparse arrays, respectively. The last section covers a special feature called incomplete queries, which helps with the handling of larger than memory results.
Dense array reads
The figure below shows how to read the values of a single attribute from a dense array. The ideas extend to multi-attribute arrays and slicing on any subset of the attributes, including even retrieving the explicit coordinates of the results. The figure shows retrieving the results in 3 different layouts, all with respect to the subarray query. This means that you can ask TileDB to return the results in an order that is different than the actual physical order (which, if you recall, is always the global order), depending on the needs of your application (this is applicable to some TileDB APIs).
![Illustration of a 4x4 dense fragment with a slice bounded by [1,2], [2,4]. To the right are the results of different cell orders on the array.](dense-read-figure-light.png)
![Illustration of a 4x4 dense fragment with a slice bounded by [1,2], [2,4]. To the right are the results of different cell orders on the array.](dense-read-figure-dark.png)
You can also submit multi-range subarrays, as shows in the figure below. The supported orders (for some TileDB APIs) here are row-major, column-major and unordered. The third case gives no guarantees about the order; TileDB will attempt to process the query in the fastest possible way and return the results in an arbitrary order. It is recommended to use this layout if you target at performance and you do not care about the order of the results. Also, you can ask TileDB to return the explicit coordinates of the returned values if you wish to know which value corresponds to which cell.
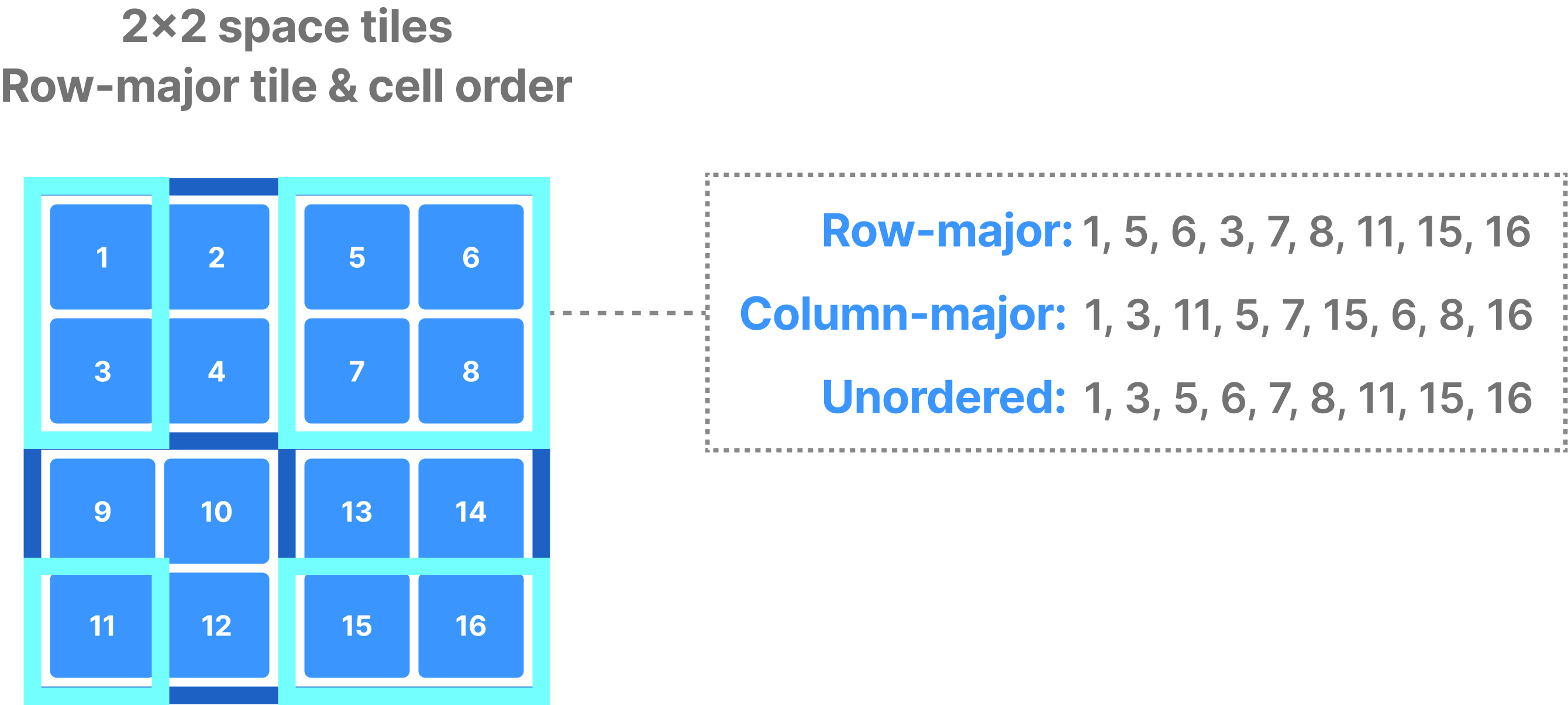
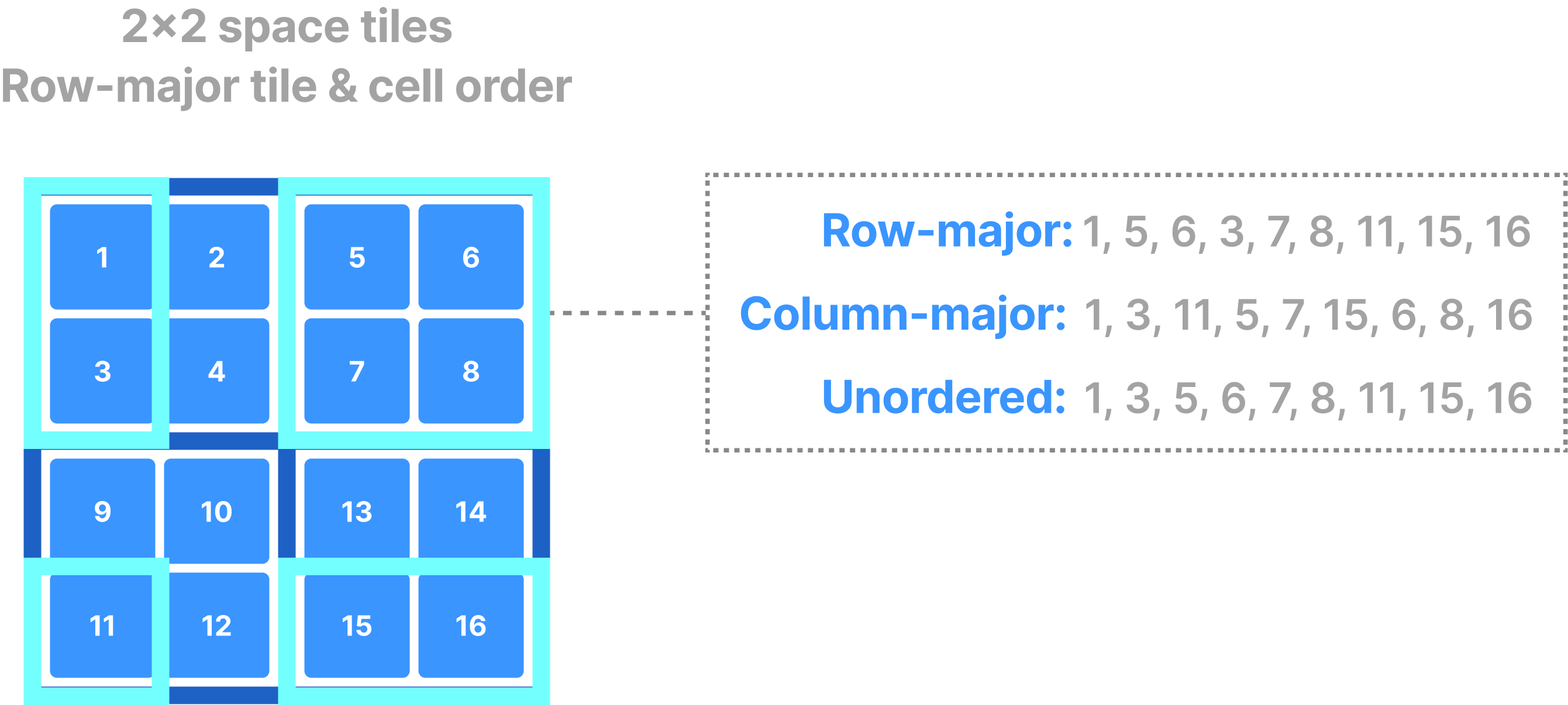
Note that reading dense arrays always returns dense results. This means that, if your subarray overlaps with empty (non-materialized) cells in the dense array, TileDB will return default or user-defined fill values for those cells. The figure below shows an example.
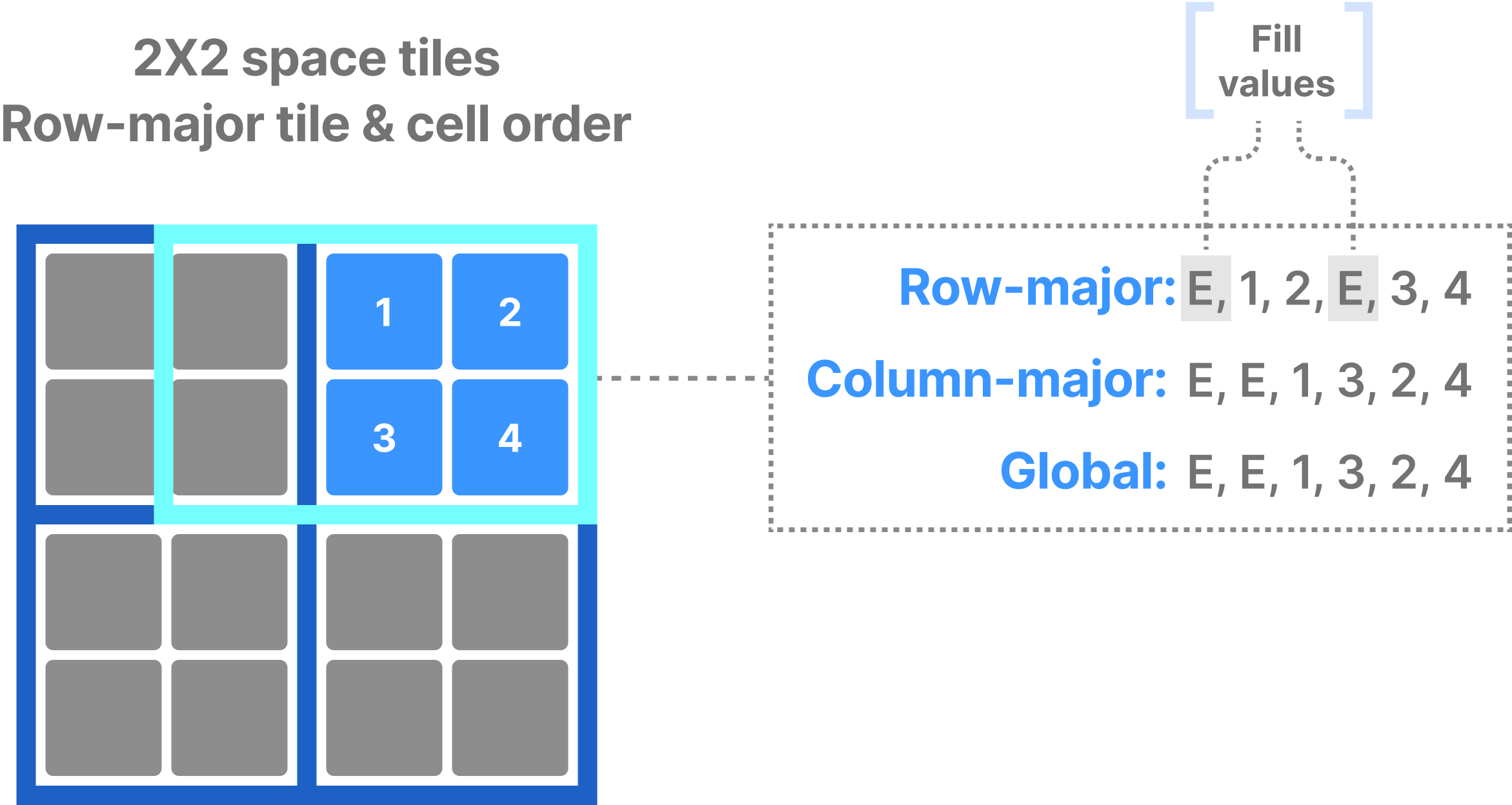
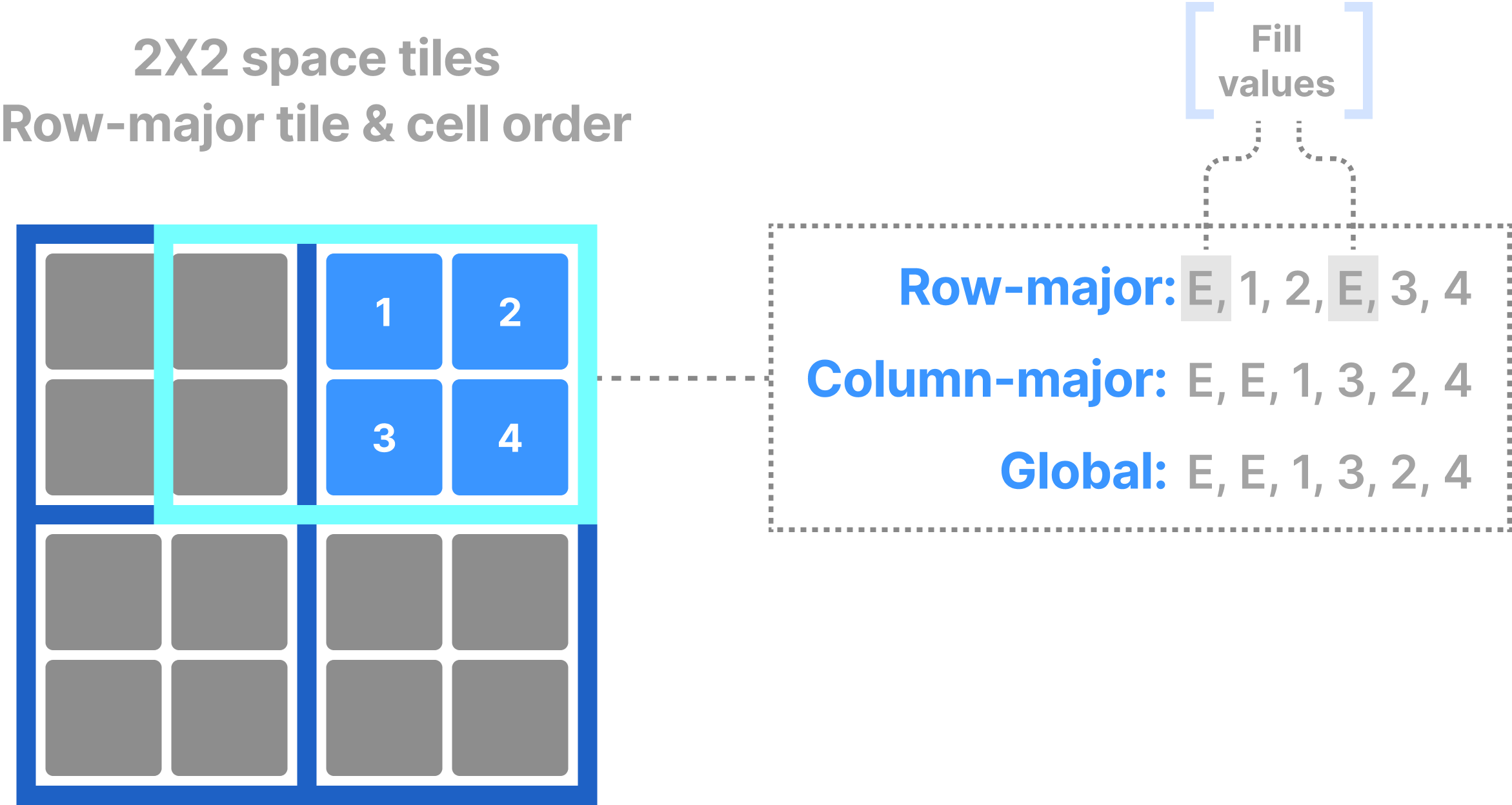
All cells in a dense fragment must have a value, which TileDB materializes on disk. This characteristic of dense fragments is important as it considerably simplifies spatial indexing, which becomes almost implicit. Consider the example in the figure below. Knowing the space tile extent along each dimension and the tile order, TileDB can identify which space tiles intersect with a subarray query without maintaining any complicated index. Then, using lightweight bookkeeping (such as offsets of data tiles on storage, compressed data tile size, etc.), TileDB can fetch the tiles containing results from storage to main memory. Finally, knowing the cell order, it can locate each slab of contiguous cell results in constant time (again without extra indexing) and minimize the number of memory copy operations.
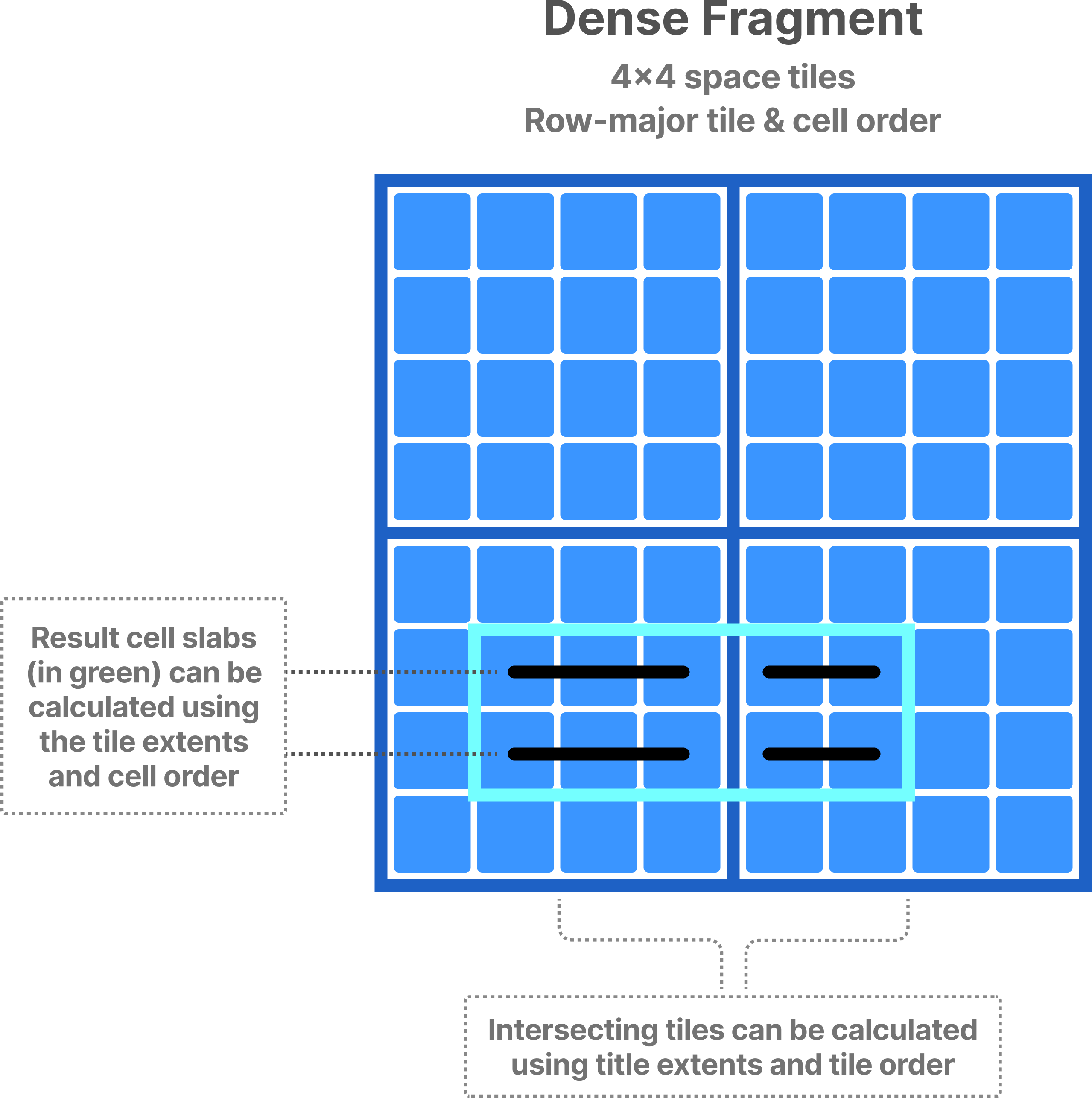
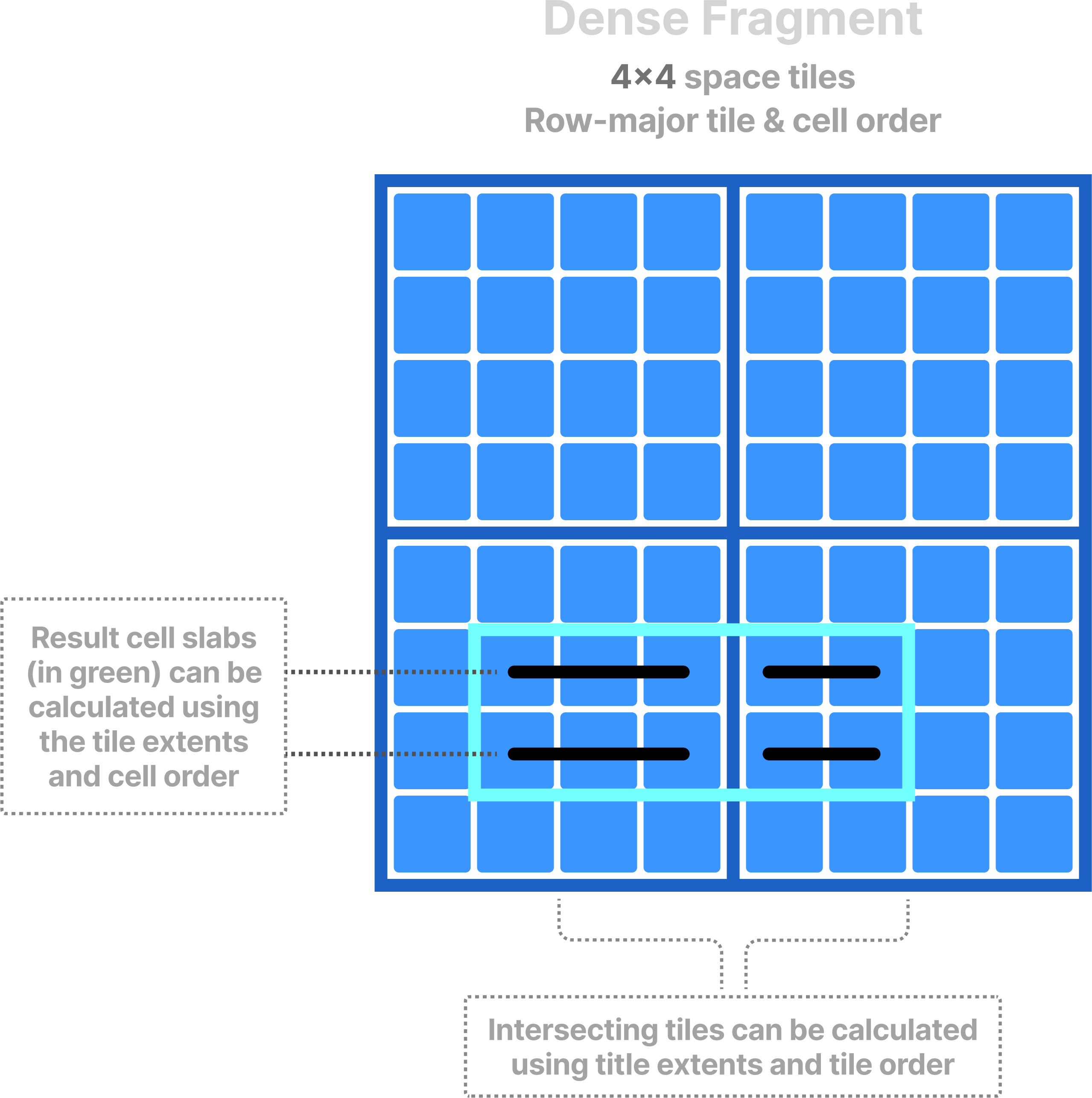
The above ideas apply also to dense fragments that populate only a subset of the array domain; knowing the non-empty domain, TileDB can use similar arithmetic calculations to locate the overlapping tiles and cell results.
Sparse array reads
The figure below shows an example subarray query on a sparse array with a single attribute, where the query also requests the coordinates of the result cells. Similar to the case of dense arrays, the user can request (in some TileDB APIs) the results in layouts that may be different from the physical layout of the cells in the array (global order).
![An illustration of a 4x4 sparse fragment with 2x2 space tiles and row-major tile and cell order. The range bounded by [1,2], [2,4] is highlighted.](sparse-read-figure-light.png)
![An illustration of a 4x4 sparse fragment with 2x2 space tiles and row-major tile and cell order. The range bounded by [1,2], [2,4] is highlighted.](sparse-read-figure-dark.png)
Sparse arrays accept multi-range subarray queries as well. Similar to the dense case, global order is not applicable here, but instead an unordered layout is supported that returns the results in an arbitrary order (again, TileDB will try its best to return the results as fast as possible in this read mode).
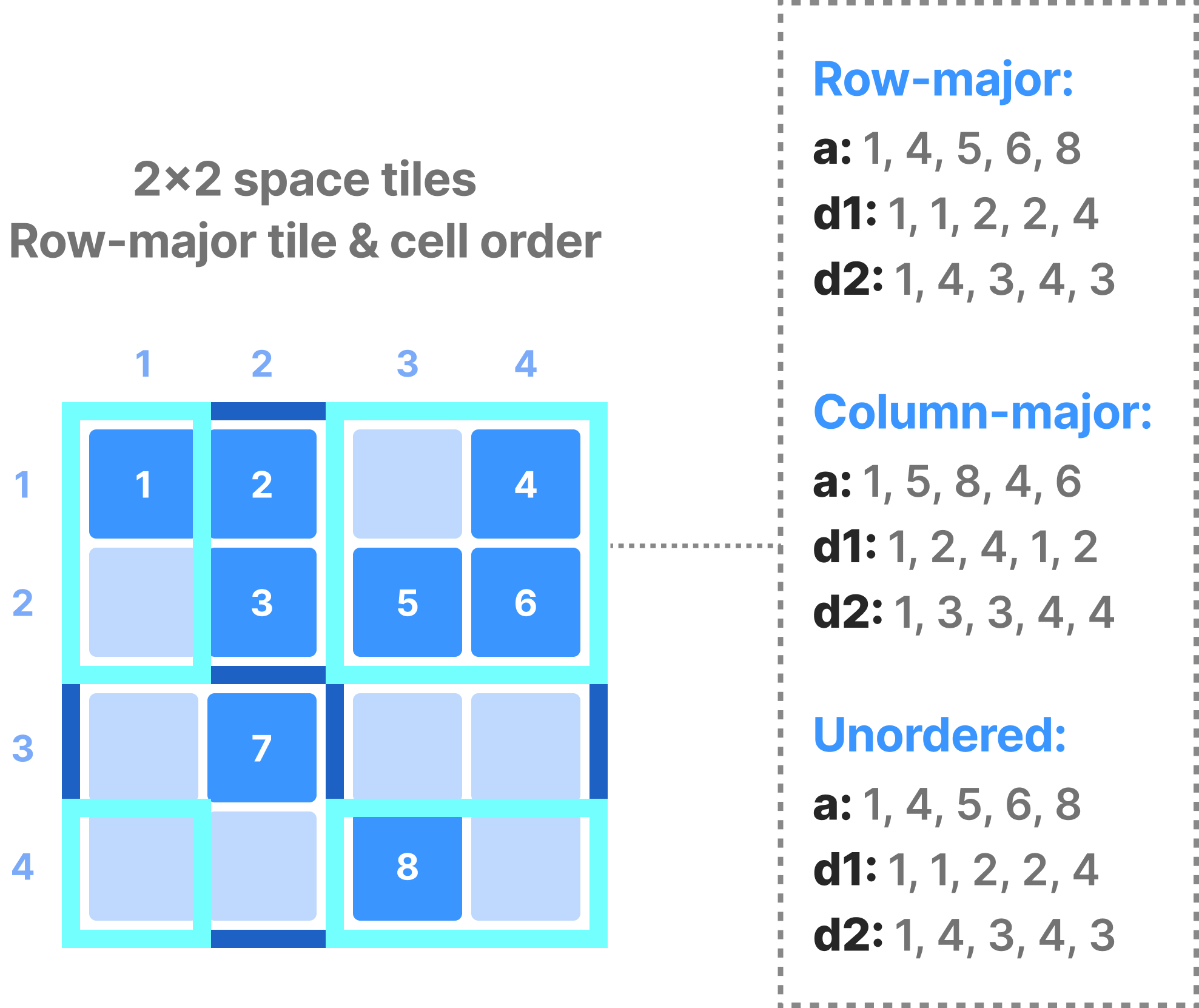
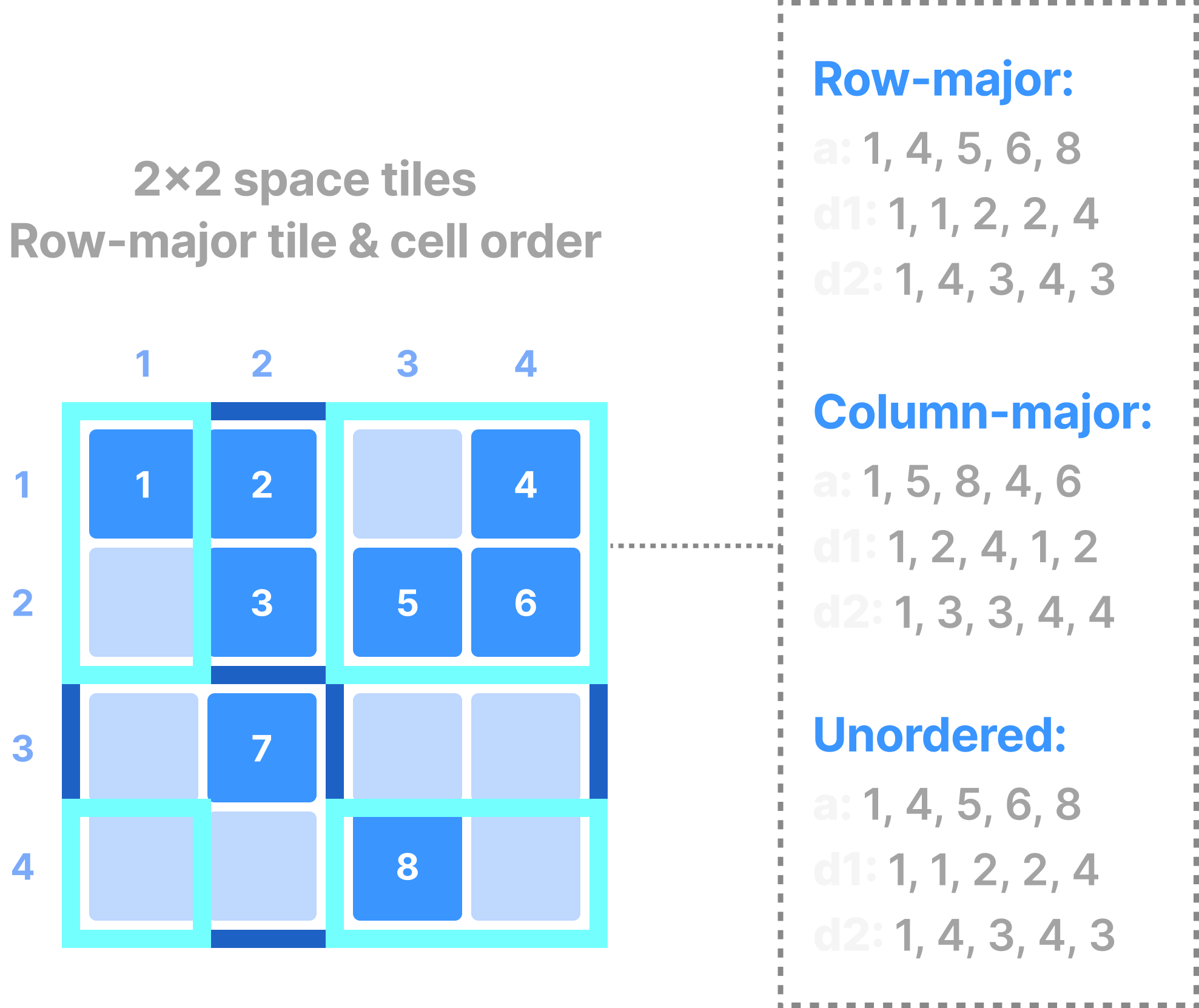
A sparse fragment differs from a dense fragment in the following aspects:
- A sparse fragment stores only non-empty cells that might appear in any position in the domain (i.e., they may not be concentrated in dense hyper-rectangles).
- In sparse fragments, space tiles have no one-to-one correspondence to data tiles. TileDB first creates the data tiles by sorting the cells on the global order, and then grouping adjacent cell values based on the tile capacity.
- In dense fragments, you have no way of knowing from the start the position of the non-empty cells, unless TileDB maintains extra indexing information.
- A sparse fragment materializes the coordinates of the non-empty cells in data tiles.
TileDB indexes sparse, non-empty cells with R-Trees. Specifically, for every coordinate data tile, it constructs the minimum bounding rectangle (MBR) using the coordinates in the tile. Then, it uses the MBRs of the data tiles as leaves and constructs an R-Tree bottom-up by recursively grouping MBRs into larger MBRs using a fan-out parameter. The figure below shows an example of a sparse fragment and its corresponding R-Tree.
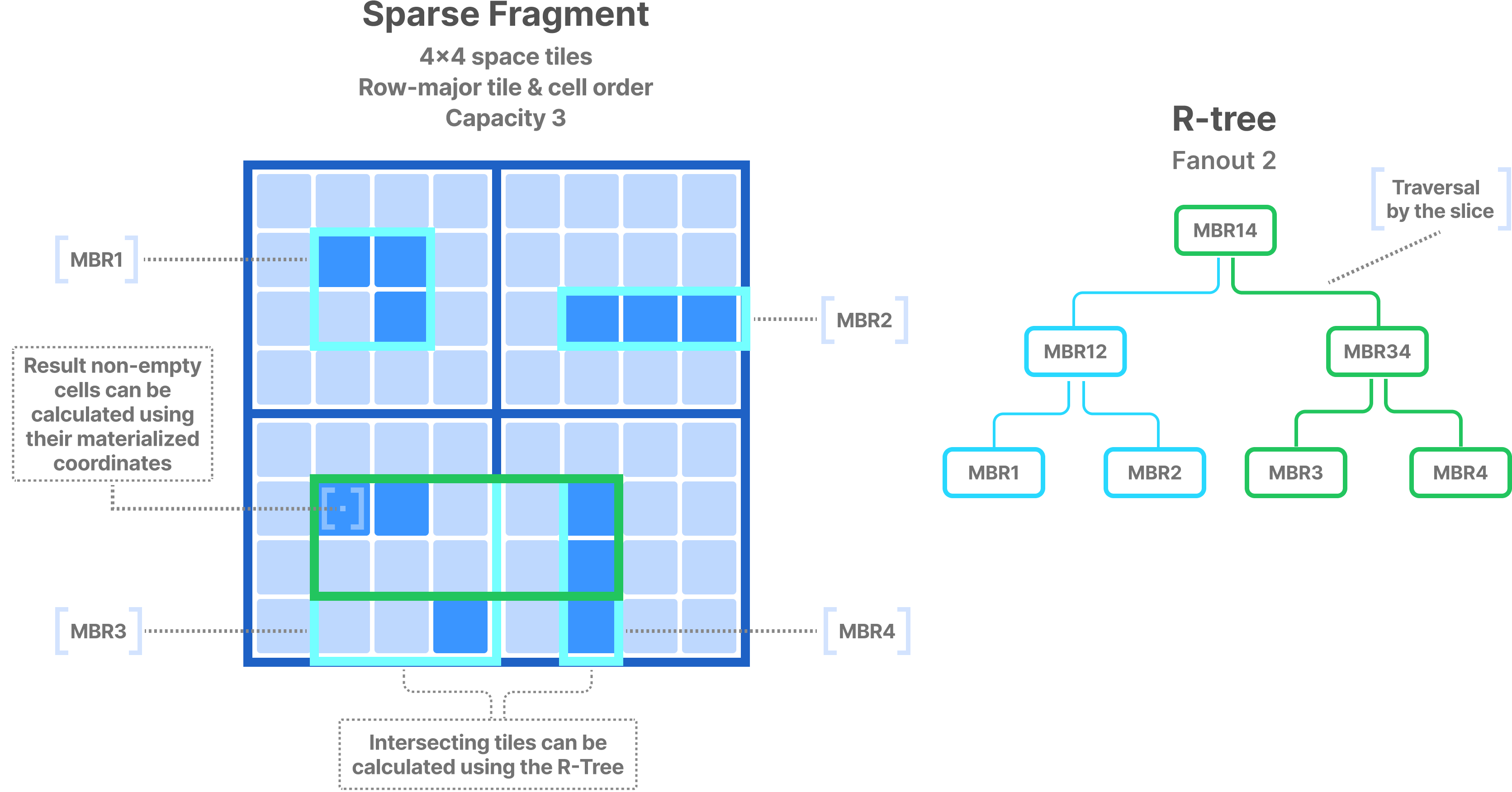
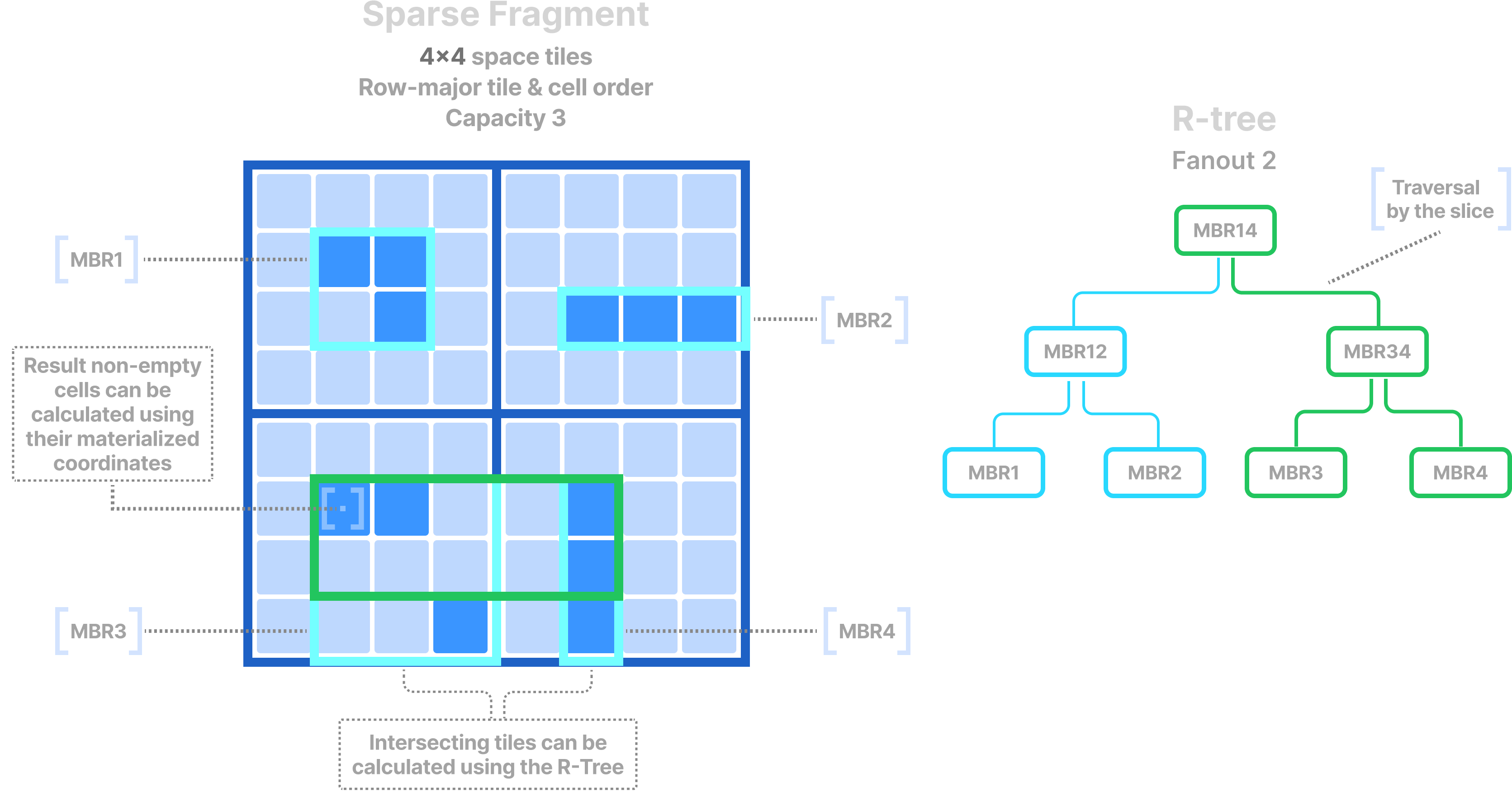
Given a subarray query, the R-Tree (which is small enough to fit in main memory) is used to identify the intersecting data tile MBRs. Then, the qualifying coordinate data tiles are fetched and the materialized coordinates therein are used to determine the actual results.
Result estimation
Result estimation in TileDB is a fast method to get an estimated size of the result when reading from sparse arrays or variable-length attributes. TileDB is able to calculate this estimate without executing the query. While result estimation can help you decide on a good buffer size for your query, it’s only an estimate, which may lead to incomplete queries.
You should perform any necessary adjustments, such as ceiling operations, and always check the query status, even when buffers are allocated based on the estimated result size.
Incomplete queries
Sometimes, the memory allotted by the user to hold the result set is insufficient for a given query. Instead of erroring out, TileDB (in certain language APIs, such as C++) gracefully handles these cases by trying to serve part of the query and report back with an “incomplete” query status. The user should then consume the returned result and resubmit the query, until the query returns a “complete” status. TileDB keeps all the necessary information about the query’s internal state inside the query object.
But what portion of the query is served in each iteration? TileDB implements the incomplete query functionality via result estimation and subarray partitioning. Specifically, if TileDB assesses (via estimation heuristics) that the query subarray leads to a larger result size than the allocated buffers, it splits (that is, partitions) it appropriately, such that TileDB can serve a smaller subarray (single- or multi-range). The challenge is in partitioning the subarray in a way that the result cell order (defined by the user) is respected across the incomplete query iterations. TileDB efficiently and correctly performs this partitioning process transparently from the user.