Vector Indexing Algorithms
TileDB currently supports three algorithm implementations: FLAT, IVF_FLAT, and VAMANA.
FLAT
FLAT is a straightforward implementation used to provide exact vector similarity search by computing the distance of the query vector and all the dataset vectors.
Ingesting data using the FLAT algorithm stores all the vectors in a 2D TileDB array without any ordering or indexing.
To search for the nearest neighbors of a given query, TileDB loads all dataset vectors in memory and computes the distance of the query and the dataset vectors maintaining a set of the nearest neighbors.
IVF_FLAT
IVF_FLAT is based on \(k\)-means clustering. Effectively, TileDB computes \(k\) separate clusters (as well as their centroids) of the dataset vectors, shuffling them in a way such that vectors in the same cluster appear adjacent on storage (to minimize IO when retrieving those vectors). The number of clusters created is specified during ingestion with partitions. Tuning this to fit your data is important for optimal performance.
To search for the nearest neighbors of a given query, the search focuses only on a small number of clusters, based on the query’s proximity to their centroids. This is specified with a parameter called nprobe—the higher this value, the more expensive the search but the better the recall (i.e., the accuracy).
The figure below shows the arrays that comprise the “vector search asset”, which is represented in TileDB with a “group” (think of this as a virtual folder). The figure also shows the IVF_FLAT query process at a high level.
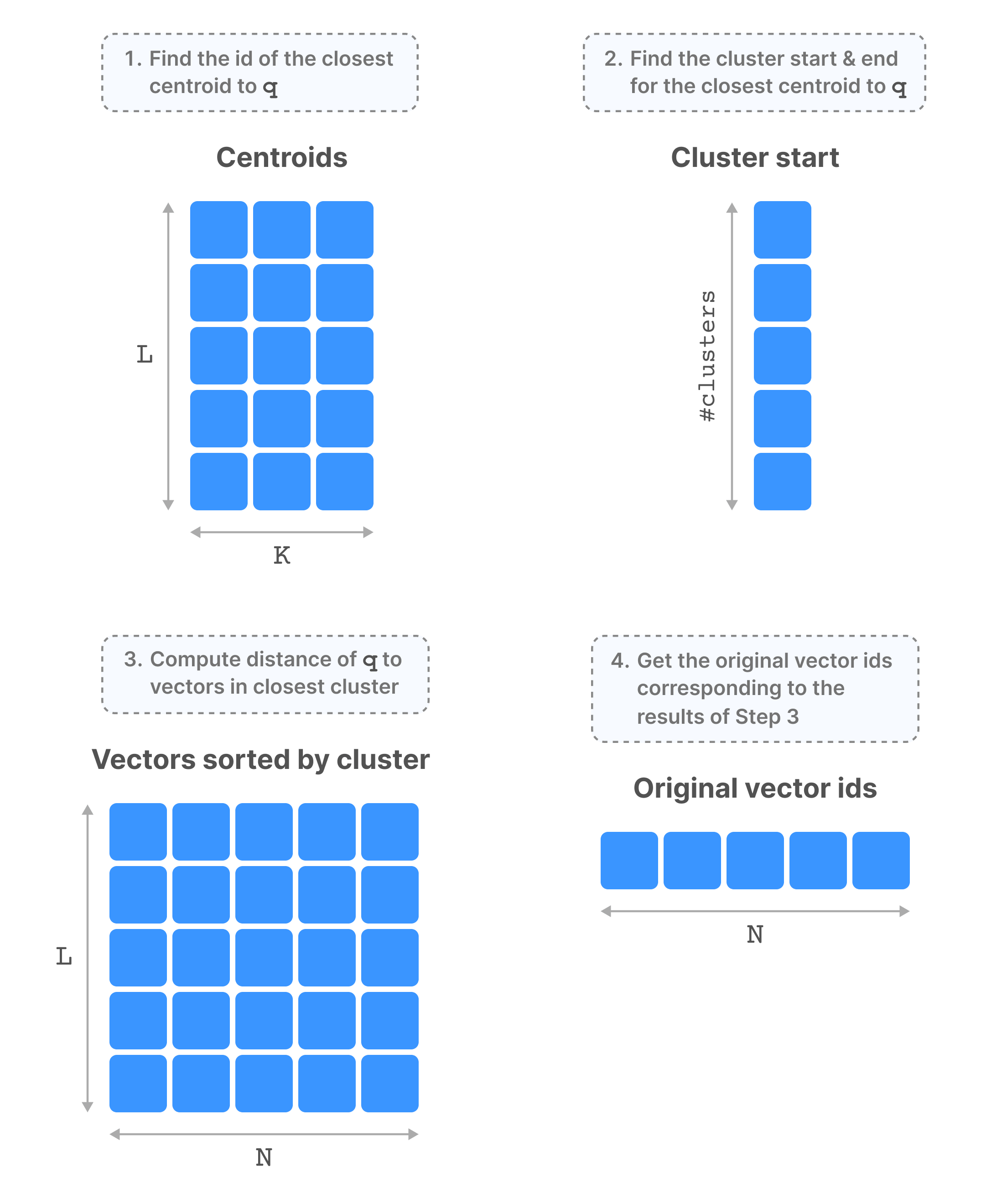
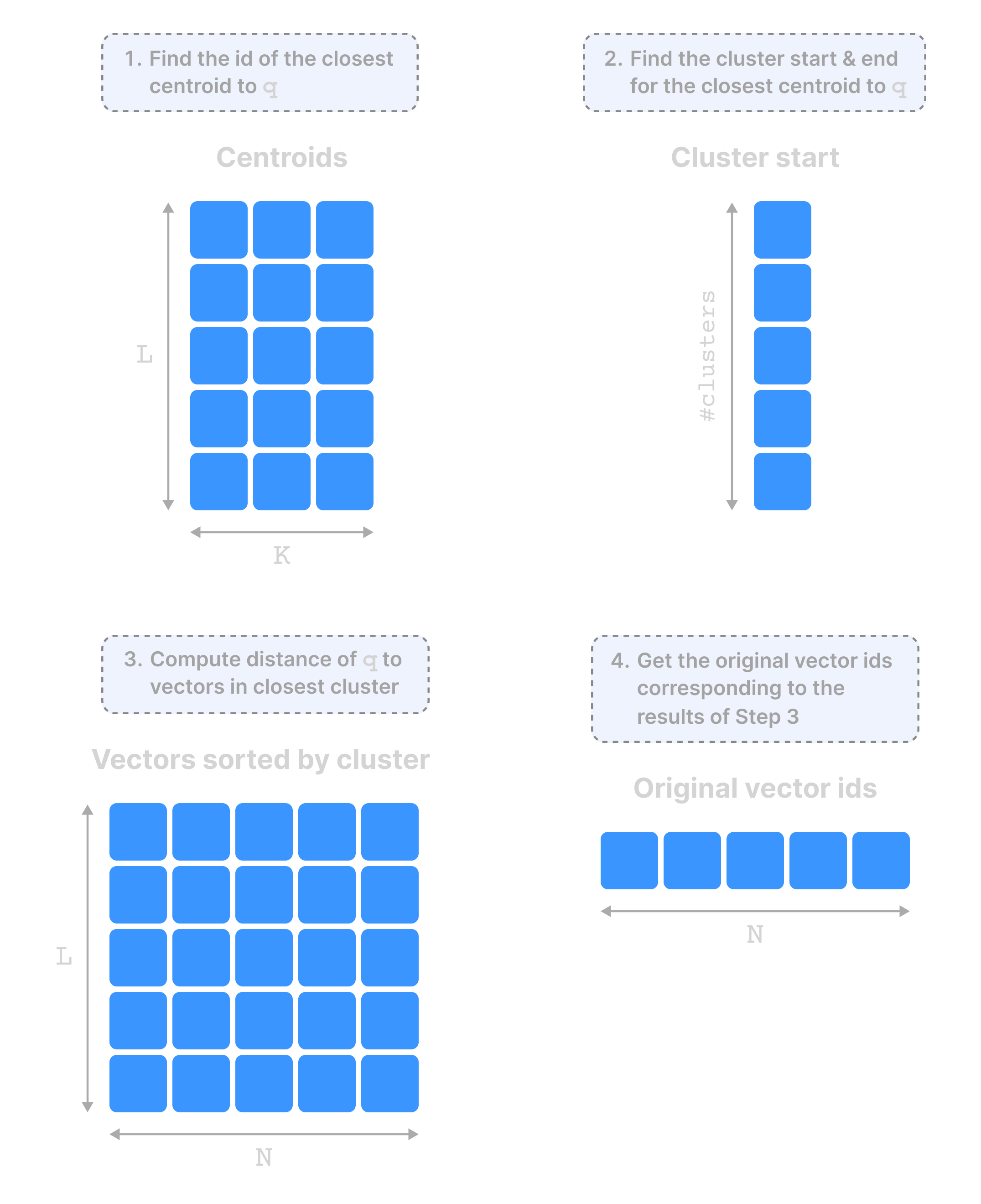
VAMANA
VAMANA is based on Microsoft’s DiskANN vector search library, as described in these papers:
- Subramanya, Suhas Jayaram et al. “DiskANN : Fast Accurate Billion-point Nearest Neighbor Search on a Single Node.” NeurIPS (2019).
- Singh, Aditi et al. “FreshDiskANN: A Fast and Accurate Graph-Based ANN Index for Streaming Similarity Search.” ArXiv abs/2105.09613 (2021).
- Gollapudi, Siddharth et al. “Filtered-DiskANN: Graph Algorithms for Approximate Nearest Neighbor Search with Filters.” Proceedings of the ACM Web Conference 2023 (2023).
VAMANA uses a graph-based indexing scheme where nodes in the graph represent the vectors to be searched. During data ingestion, a small world graph is created where each vector is a node connected to its approximate nearest neighbors. The graph is constructed to have bounded vertex degree and small network diameter.
To search for the nearest neighbors of a given query, VAMANA uses a bounded best-first (greedy) search. A frontier with a given number (l_search) of nodes is advanced by exploring the unvisited neighbors of the node closest to the query. Nodes are added to the frontier if they are closer to the query vector than the furthest node in the frontier. When no nodes remain that are closer than the nodes in the frontier, the algorithm stops.