Consolidation
A large number of writes and deletions may generate numerous fragments, which may in turn impact the TileDB read performance. This is because many fragments would lead to fragment metadata being loaded to main memory from numerous different files in storage during a read operation. Moreover, the locality of the result cells of a slicing/subarray query may be destroyed in case those cells appear in multiple different fragment files, instead of concentrated byte regions within the same fragment files.
To mitigate this problem, TileDB has a consolidation feature, which allows you to:
- Merge a subset of fragments into a single fragment or into multiple fragments with enhanced cell spatially locality within each new fragment.
- Merge (write and deletion) commit files into a single file.
- Merge fragment metadata files into a single one.
- Merge a subset of array metadata files into a single one.
- Merge a subset of group metadata files into a single one.
Consolidation is thread-/process-safe and can be done in the background while you continue reading from the array without being blocked. Moreover, consolidation does not hinder the ability to do time traveling at a fine granularity, as it does not delete fragments that participated in consolidation (and, therefore, they are still queryable).
Consolidation, in combination with vacuuming, can significantly boost read performance, but may affect the granularity of time traveling. Visit the Key Concepts: Time Traveling section to learn more about time traveling and how it is affected by consolidation and vacuuming.
Dense consolidation
This section covers consolidation in dense arrays. It first explains some basic theory behind dense consolidation, and then describes how TileDB selects the fragments to consolidate, providing a lot of flexibility to the user to fine-tune the consolidation process for maximum performance.
Basic concepts
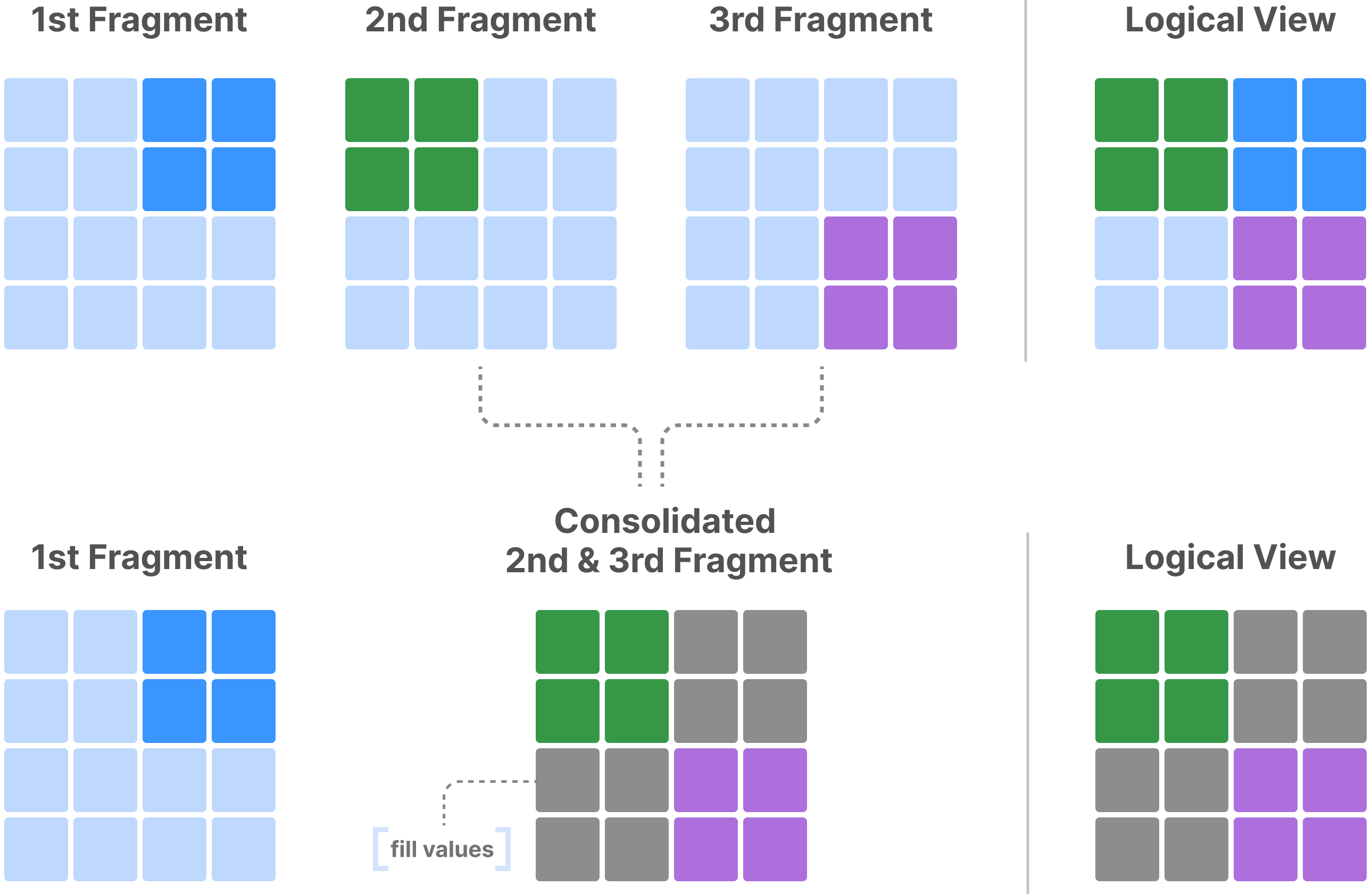
The figure below shows consolidation of two dense fragments. The array in the figure has a 2x2 space tiling. Each dense fragment consists of a dense hyper-rectangle that stores only integral tiles. In those two fragments, each hyper-rectangle is equivalent to the non-empty domain of the corresponding fragment. The consolidated fragment will consist of the tightest hyper-rectangle that contains the non-empty domain of both fragments under consolidation. In the new fragment of the example, this hyper-rectangle happens to cover the entire array domain, and is the non-empty domain of this new fragment. Observe that one tile (lower left) is partially written, whereas another tile (lower right) is completely empty but inside the non-empty domain. TileDB populates both these tiles with special fill values.
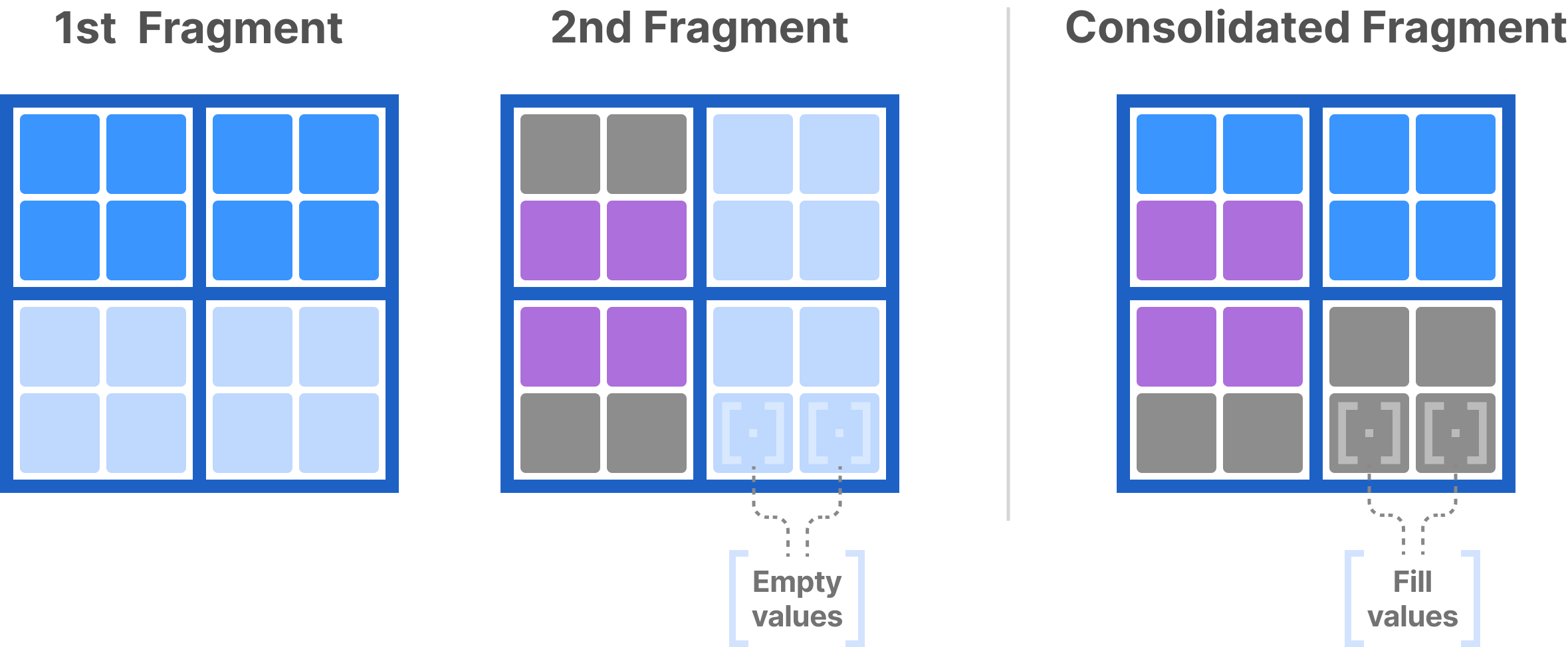
Each fragment is associated with its creation timestamp upon writing. A consolidated fragment instead is associated with the timestamp range that includes the timestamps of the fragments that produced it. This is particularly important for time traveling: opening an array at a timestamp will consider all the consolidated fragments whose end timestamp is at or before the query timestamp. In other words, although consolidation generally leads to better performance, it affects the granularity of time traveling.
Selecting fragments to consolidate
The consolidation algorithm requires to choose which fragments to consolidate, as well as in how many steps (since consolidating a huge number of fragments in a single step might be prohibitive from a memory consumption perspective). The two sections below explain the selection process; in the automatic mode, the user sets certain configuration parameters and TileDB takes care of the selection. In the manual mode, the user provides a set of specific fragments to consolidate.
Automatic fragment selection
Preprocessing
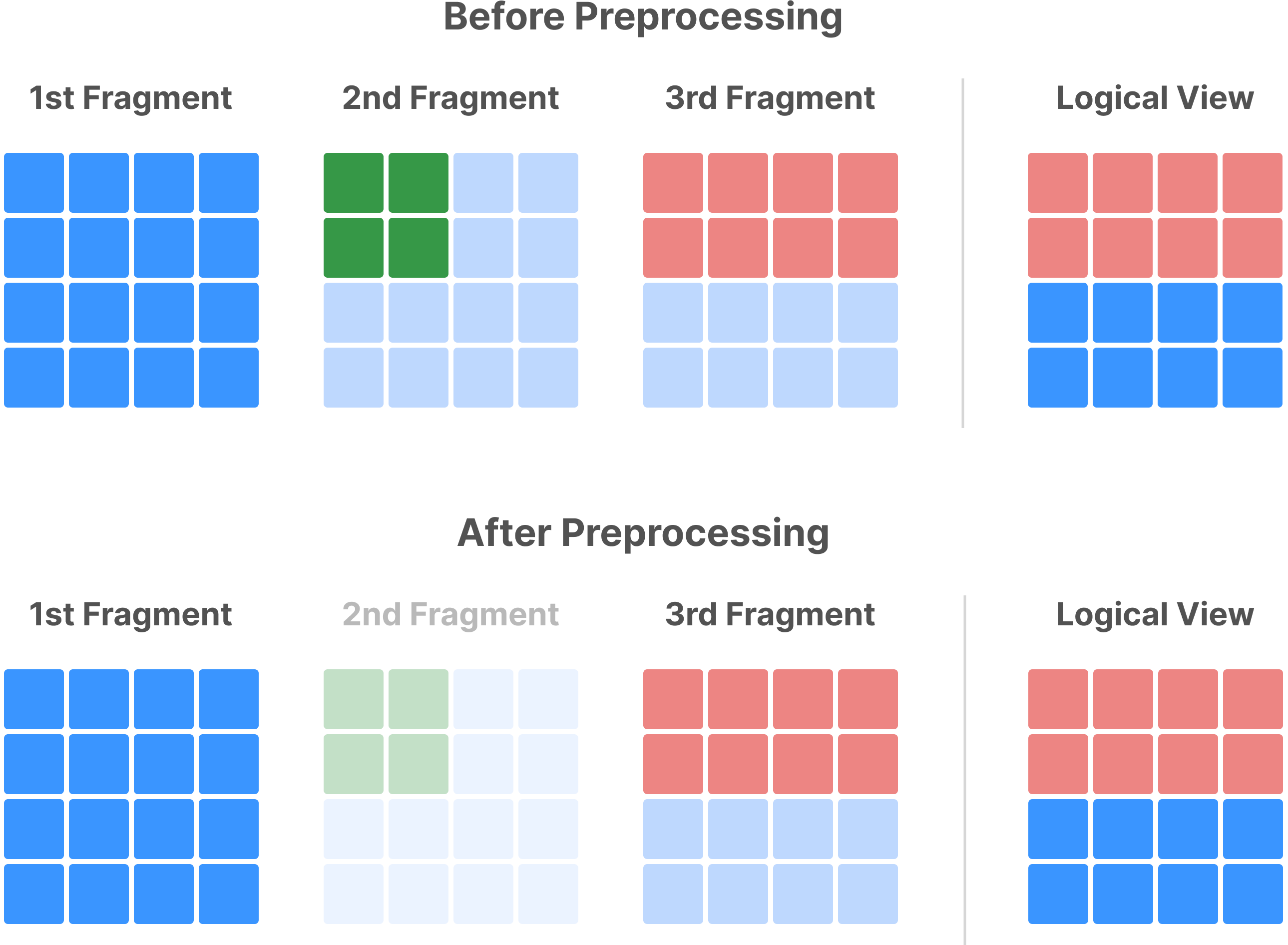
Before the consolidation algorithm begins, TileDB applies a simple optimization in a pre-processing step, which may lead to great performance benefits depending on the “shape” of the existing fragments. Specifically, TileDB identifies fragments whose non-empty domain completely covers older adjacent fragments, and does not further consider them for consolidation. Instead, it adds them to a special vacuum file so that they can be deleted in the vacuuming process after the consolidation takes place.
This clean-up process is illustrated with an example in the figure below. Suppose the first fragment is dense and covers the entire array (i.e., [1,4], [1,4], the second covers [1,2], [1,2], and the third one is covering [1,2], [1,4]). Observe that, if those three fragments were to be consolidated, the cells of the second fragment would be completely overwritten by the cells of the third fragment. Therefore, the existence of this fragment would make no difference to the consolidation result. Disregarding the second fragment altogether before the consolidation algorithm commences will result in boosting the algorithm performance (since fewer cells will be read and checked for overwrites).
Algorithm
The consolidation algorithm is performed in steps. In each step, a subset of adjacent (in the timeline) fragments is selected for consolidation. The algorithm proceeds until a determined number of steps were executed, or until the algorithm specifies that no further fragments are to be consolidated. The choice of the next fragment subset for consolidation is based on certain rules and user-defined parameters, explained below. The number of steps is also configurable, controlled by sm.consolidation.steps.
Let us focus on a single step, during which the algorithm must select and consolidate a subset of fragments based on certain criteria:
- The first criterion is if a subset of fragments is “consolidatable” (i.e., eligible for consolidation in a way that does not violate correctness). If the union of the non-empty domains of the fragments (which is equal to the non-empty domain of the resulting consolidated fragment) overlaps with any fragment created prior to this subset, then the subset is marked as non-consolidatable. This is because empty regions in the non-emtpy domain of the consolidated fragment will be filled with special values. Those values may erroneously overwrite older valid cell values. Such a scenario is illustrated in the figure below. The second and third fragments are not consolidatable, since their non-empty domain contains empty regions that overlap with the first (older) fragment. Consequently, consolidating the second and third fragment results in a logical view that is not identical to the one before consolidation, violating correctness. This criterion detects and prevents such cases.
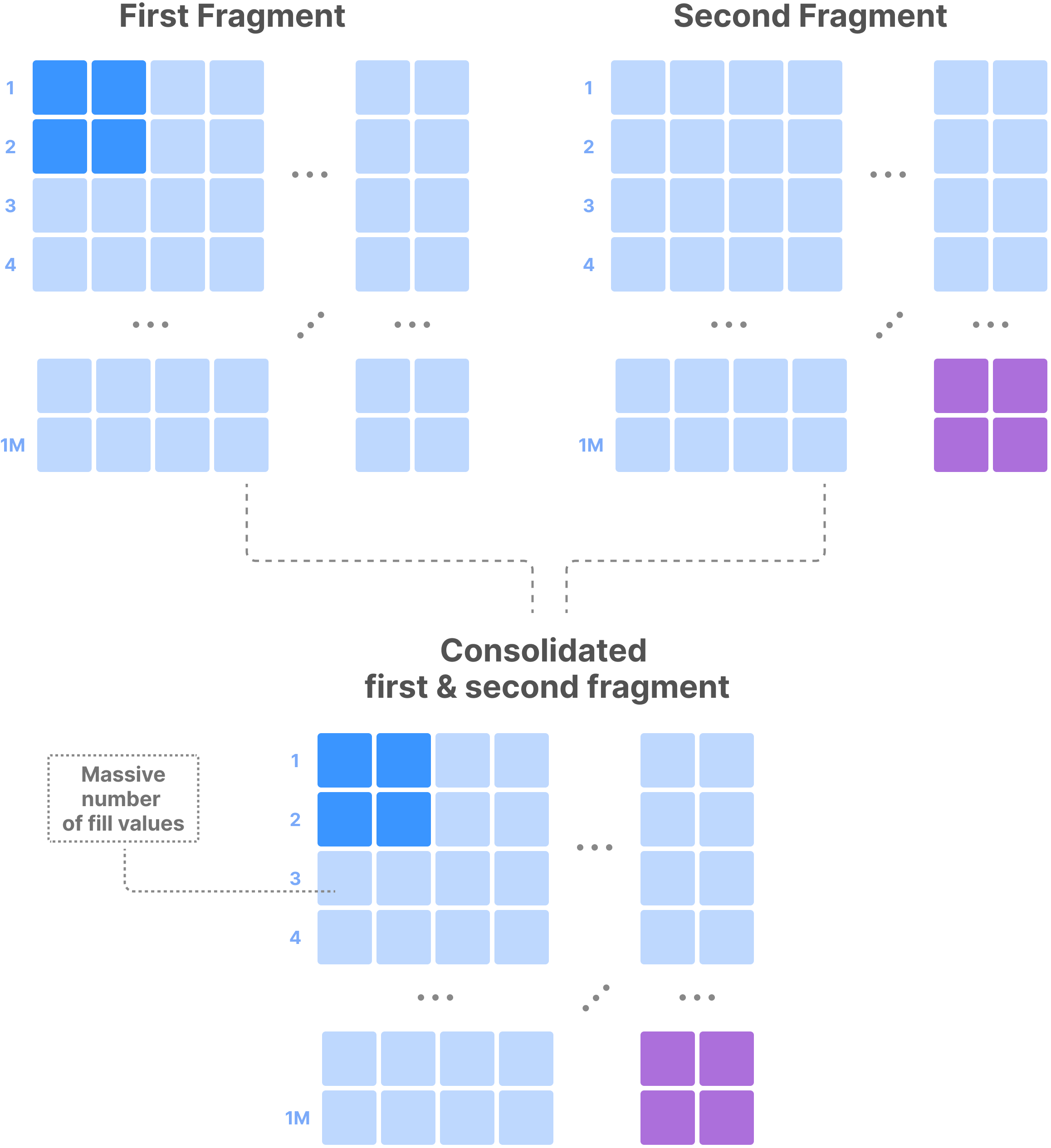
The second criterion is the comparative fragment size. Ideally, we must consolidate fragments of approximately equal size. Otherwise, we may end up in a situation where, for example, a 100GB fragment gets consolidated with a 1MB one, which would unnecessarily waste consolidation time. This is controlled by parameter
sm.consolidation.step_size_ratio; if the size ratio of two adjacent fragments is smaller than this parameter, then no fragment subset that contains those two fragments will be considered for consolidation.The third criterion is the fragment amplification factor. If the non-empty domain of the resulting fragment has too many empty cells, its size may become considerably larger than the sum of sizes of the original fragments to be consolidated. This is because the consolidated fragment inserts special fill values for all empty cells in its non-empty domain (refer to the following figure). The amplification factor is the ratio between the consolidated fragment size and the sum of sizes of the original fragments. TileDB controls the amplification factor by
"sm.consolidation.amplification". Subsets of fragments are only eligible for consolidation if they don’t exceed the amplification factor. The default value1.0means that the fragments will be consolidated if the size of the resulting consolidated fragment is smaller than or equal to the sum of sizes of the original fragments. As an example, this happens when the non-empty domain of the consolidated fragment doesn’t have any empty cells.

The fourth criterion is the collective fragment size. Among all eligible fragment subsets for consolidation, we must first select to consolidate the ones that have the smallest sum of fragment sizes. This will quickly reduce the number of fragments (hence boosting read performance), without resorting to costly consolidation of larger fragments.
The fifth criterion is the number of fragments to consolidate in each step. This is controlled by
sm.consolidation.step_min_fragsandsm.consolidation.step_max_frags; the algorithm will select the subset of fragments (complying with all the above criteria) that has the maximum cardinality smaller than or equal tosm.consolidation.step_max_fragsand larger than or equal tosm.consolidation.step_min_frags. If no fragment subset is eligible with cardinality at leastsm.consolidation.step_min_frags, then the consolidation algorithm terminates.
The algorithm is based on dynamic programming and runs in time O(max_frags * total_frags), where total_frags is the total number of fragments considered in a given step, and max_frags is equal to the sm.consolidation.step_max_frags config parameter.
When computing the union of the non-empty domains of the fragments to be consolidated, the union is always expanded to coincide with the space tile extents. This affects criterion 1 (since the expanded domain union may now overlap with some older fragments) and 2 (since the expanded union may amplify resulting consolidated fragment size).
Manual fragment selection
TileDB allows the user to specify a list of fragments to be consolidated.
Although this offers immense flexibility, this should be used with care, since TileDB will not perform any checks on the fragments (e.g., check if they are consolidatable) and, therefore, this may lead to undesirable results.
Sparse consolidation
This section covers consolidation in sparse arrays. It first explains some basic theory behind sparse consolidation, and then describes how TileDB selects the fragments to consolidate, providing a lot of flexibility to the user to fine-tune the consolidation process for maximum performance.
Basic concepts
The figure below demonstrates a basic sparse consolidation example. Similar to dense array consolidation, in sparse array consolidation, a consolidated fragment carries the range of timestamps of the fragments it consolidates in its name, and its non-empty domain is the union of the non-empty domains of the fragments it consolidates.
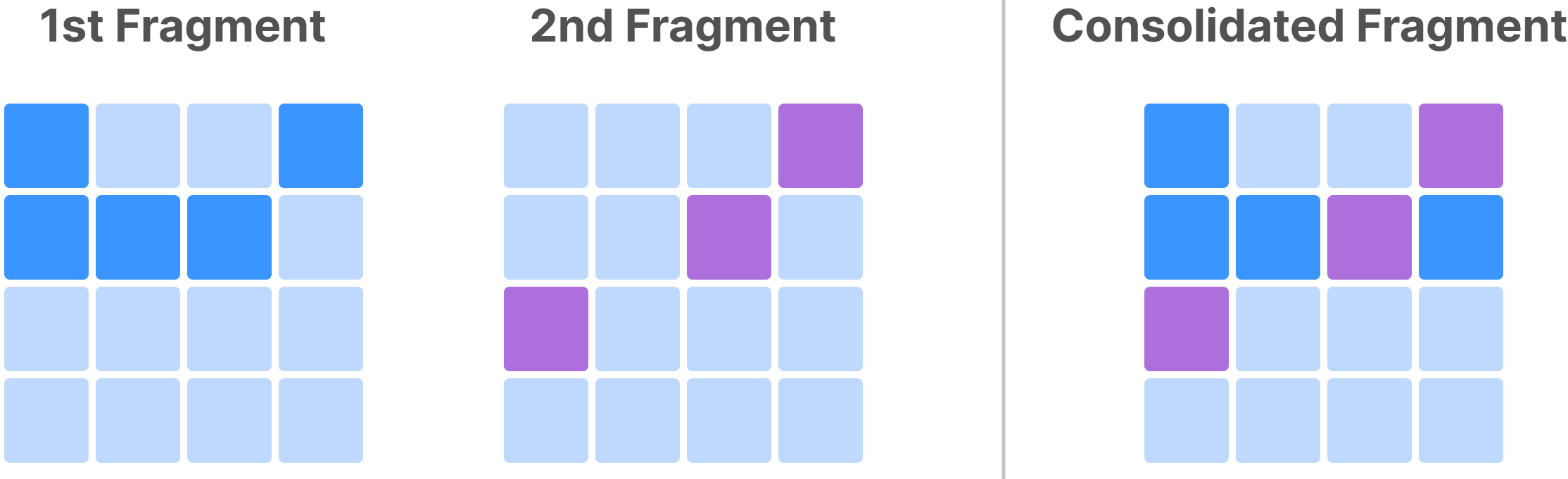
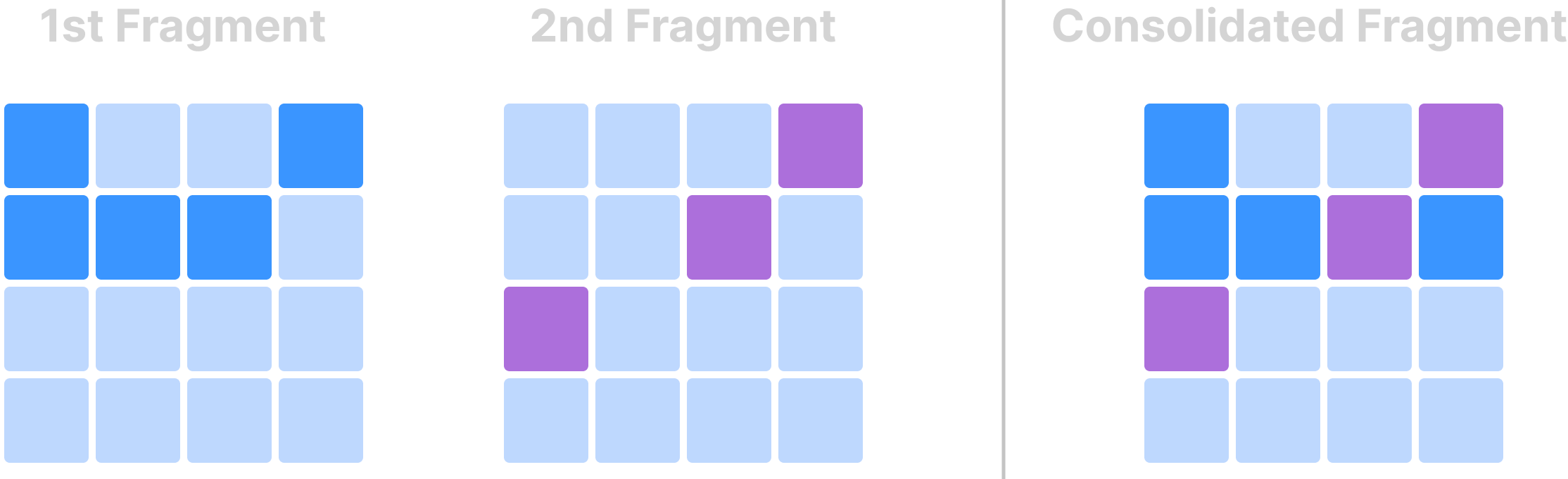
The consolidated fragment of a sparse array is always sparse and, thus, has no fill values for empty cells. TileDB never materializes empty cells. If the array schema doesn’t allow cell duplicates, a non-empty cell in a fragment with a later timestamp overwrites a non-empty cell with the same coordinates in a fragment with an earlier timestamp. If the array schema does allow cell duplicates, then non-empty cells with the same coordinates all appear in the result (cells never overwrite each other).
Selecting fragments to consolidate
TileDB selects fragments to consolidate in three ways: automatically, manually, or using a feature called “consolidation plan” (which is useful for distributed consolidation).
Automatic fragment selection
The algorithm in sparse array consolidation is similar to the dense case, and configuration parameters sm.consolidation.steps, sm.consolidation.step_size_ratio, sm.consolidation.step_min_frags, and sm.consolidation.step_max_frags are used in the same manner.
However, contrary to dense array consolidation, in sparse array consolidation:
- All fragments are consolidatable.
- TileDB ignores the amplification factor, since sparse arrays don’t materialize empty cells.
- Sparse arrays support deletions, which consolidation either purges them (if
sm.consolidation.purge_deleted_cellsistrue), or keeps them in the new consolidated fragment otherwise. In the latter case, TileDB stores both the creation timestamp of each cell (including the deleted cells), as well as the time of deletion if a cell is deleted. That allows for very fine-grained time traveling, even if you vacuum the fragments that were consolidated. The deletion condition for all materialized deleted cells is copied to the fragment metadata of the consolidated fragment, so that TileDB does not process it for this fragment upon reads (it will just process the materialized entries based on the deletion timestamp). - If
sm.consolidation.max_fragment_sizeis set, then consolidation may produce more than one consolidated fragment, each of roughly the size specified in this parameter. Capping the maximum fragment size (e.g., to something reasonable like 500MB to a few GBs) is particularly beneficial for future consolidation, since humongous fragments may lead to very slow consolidation that does not allow itself to be parallelized across multiple machines. It may also boost the performance of reads, due to faster fetching of fragment metadata that can be used for more effective pruning of entire fragments.
Manual fragment selection
TileDB allows you to explicitly select the fragments to consolidated. This is recommended only for power users that require immense flexibility to build their own consolidation algorithms.
Consolidation plan
TileDB allows you to generate a consolidation plan, without running the consolidation process. This is beneficial if you would like to run consolidation in parallel across multiple machines to significantly shrink the completion time (especially for very large arrays).
The consolidation plan returns a list of fragment lists, each containing a set a fragments that need to be consolidated together in a single consolidation process (which could potentially be dispatched separately on a separate compute node). The consolidation process for each of these lists should be run as a separate call that manually consolidates the fragments explicitly providing the fragment list.
The plan takes in the value of configuration parameter sm.consolidation.max_fragment_size (that is, the desired maximum fragment size that results from consolidation) and returns the fragments to be consolidated together in three steps:
- In the first step, it uses the minimum bounding rectangles (MBRs) to see which fragments overlap, and puts overlapping fragments together.
- In the second step, it looks at fragments that are less than half of the desired size and try to merge them together. The resulting fragment needs to have no overlap with any other fragments.
- In the third step, it takes fragments that are over 1.5 times of the desired fragment size and creates a unary list for each of them. The consolidation operation will rewrite the fragment, after splitting it up, producing multiple fragments.
Commit consolidation
TileDB allows you to consolidate the commit files as well. This is important in the presence of numerous fragments, as reading an array requires listing all these files, which can be an expensive operation on object stores when the number of files is huge. Commit consolidation always consolidates all the commit files, producing a single commit file that contains:
- The file names of the commits resulting from write operations that are being consolidated.
- The deletion conditions if a deletion condition file is being consolidated.
The consolidated commit file contains all the information TileDB needs to carry out the subsequent reads without losing any data and while being able to perform time traveling if requested.
Fragment metadata consolidation
Each fragment metadata file (located in a fragment folder) contains some lightweight information in its footer. This is mostly the non-empty domain and offsets for other metadata included in other parts of the file. If an array has many fragments, reading the array may be slow on cloud object stores due to the numerous REST requests to fetch the fragment metadata footers. TileDB offers a consolidation process (with mode fragment_meta), which merges the fragment metadata footers of a subset of fragments into a single file that has suffix .meta, stored in the array folder. This file is named similarly to fragments (that is, it carries a timestamp range that helps with time traveling). It also contains all the URIs of the fragments whose metadata footers are consolidated in that file. Upon reading an array, only this file can be efficiently fetched from the backend, since it is typically very small in size (even for hundreds of thousands of fragments).
Array and group metadata consolidation
Similar to array fragments, array metadata and group metadata can also be consolidated (with mode array_meta). Since the array and group metadata are typically small and can fit in main memory, TileDB reads all the array metadata (from all the existing array and group metadata files) in main memory, creates an up-to-date view of the metadata, and then flushes them to a new array or group metadata file that carries in its name the timestamp range determined by the first timestamp of the first array metadata and the second timestamp of the last array metadata files that got consolidated.
Contrary to the case of fragments, array and group metadata consolidation always purges the deleted metadata, which may impact time traveling after vacuuming. This is because the deleted values will no longer be found in the files where they were written (since those are vacuumed), whereas the consolidated file does not include them either (since they are always purged upon consolidation).
Consolidation in a time range
TileDB allows you to specify a time range within which the consolidation will take place. This is controlled by configuration parameters sm.consolidation.timestamp_start and sm.consolidation.timestamp_end. This functionality is supported for consolidation of:
- fragments
- array metadata
- group metadata
Consolidation configuration
You can find the TileDB configuration parameters for consolidation and the way to set them in the Configuration: Consolidation and Vacuuming section.
Vacuuming
Consolidation may produce numerous files that become unused and, therefore, unnecessarily take up storage. TileDB supports a vacuuming process, which cleans up all redundant files generated by consolidation. Visit the Key Concepts: Vacuuming section for more details on vacuuming.