import os
import tiledb
# You should set the appropriate environment variables with your keys.
# Get the keys from the environment variables.
tiledb_account = os.environ["TILEDB_ACCOUNT"]
tiledb_token = os.environ["TILEDB_REST_TOKEN"]
# or use your username and password (not recommended)
# tiledb_username = os.environ["TILEDB_USERNAME"]
# tiledb_password = os.environ["TILEDB_PASSWORD"]
# Get the bucket and region from environment variables
s3_bucket = os.environ["S3_BUCKET"]
# Set the AWS keys and region to the config of the default context
# This context initialization can be performed only once.
cfg = tiledb.Config(
{
"rest.token": tiledb_token,
# or use your username and password (not recommended)
# "rest.username": tiledb_username,
# "rest.password": tiledb_password,
}
)
ctx = tiledb.Ctx(cfg)Population Genomics: Scalable Queries
life sciences
genomics (vcf)
tutorials
queries
Learn about using TileDB task graphs to perform distributed queries on TileDB-VCF datasets.
How to run this tutorial
You can run this tutorial only on TileDB Cloud. However, TileDB Cloud has a free tier. We strongly recommend that you sign up and run everything there, as that requires no installations or deployment.
You can take advantage of TileDB Cloud’s distributed computing capabilities to perform scalable queries in two ways:
- Building your own custom distributed algorithms using UDFs and task graphs.
- Leveraging the built-in distributed read capabilities of TileDB-VCF on TileDB Cloud.
This tutorial covers the second way. Namely, it shows you how you can query a large dataset with a single TileDB-VCF command on TileDB Cloud, which is automatically executed in a distributed manner across multiple cloud workers, completely serverlessly. For more information of TileDB Cloud’s scalability, visit the Key Concepts: Distributed Compute section.
First, set up your TileDB Cloud credentials, similar to Tutorials: Basic TileDB Cloud.
Next, import the necessary libraries.
Choose a dataset to read. In this tutorial, you are using the preloaded and publicly accessible 1000 genome dataset. Retrieve all the samples (which are over 3,000), and define the attributes to retrieve and genomic ranges. Finally, issue the read query.
Behind the scenes, this single command generates and deploys a task graph on TileDB Cloud, which executes the query in parallel across multiple machines. You can find the task graph detailed logs under Monitor -> Logs -> Task Graphs and choosing the corresponding task graph entry. This looks as follows.
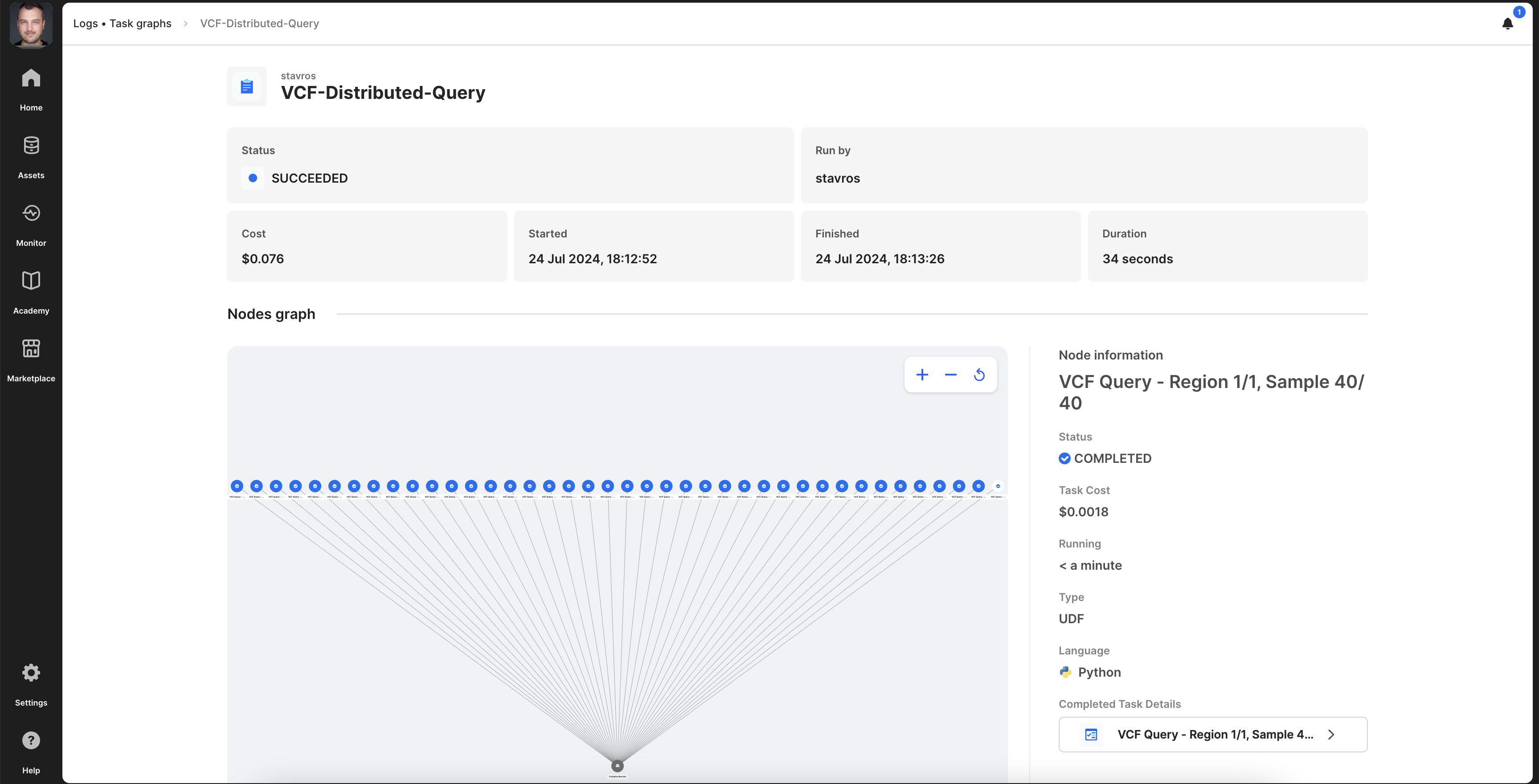
That’s it! All the serverless, distributed computing magic is built into a single TileDB-VCF command run on TileDB Cloud.T