import os
import shutil
import cv2
import matplotlib.pylab as pylab
import tiledb
from tiledb.bioimg.converters.ome_tiff import OMETiffConverter
root_dir = os.path.expanduser("~/tiledb-bioimg-tiledb-py")
if os.path.exists(root_dir):
shutil.rmtree(root_dir)
os.makedirs(root_dir)Read Biomedical Images with TileDB-Py
life sciences
biomedical imaging
tutorials
reads
python
Learn how to read a biomedical image with TileDB-Py API.
Slicing and reading your data in TileDB is essential step to access your data. For this reason, you have two options on how you can read your data into TileDB. In this tutorial, you will learn how to and slice your biomedical imaging data by using the native TileDB-Py API. This API is the main interface for interacting with TileDB in Python.
Note
To use the TileDB-Py API with biomedical images effectively, you should first have a good understanding of the TileDB-BioImaging underlying data model.
Setup
Start by importing the necessary libraries needed for this tutorial.
Image Properties
TileDB, after ingesting an image, stores the whole image as a TileDB group.
Querying the properties of the image is the same as querying the metadata of the TileDB group.
Each resolution layer is now a TileDB array and member of the image TileDB group. To get a more granular access to each level’s properties you need to access the metadata of the members of the group. The members are TileDB arrays representing each resolution level.
Read a resolution level
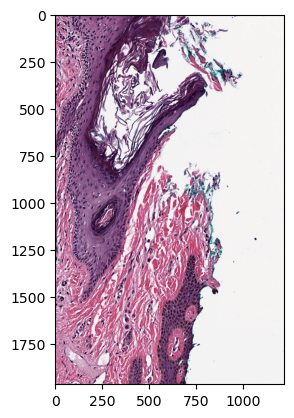
You can read a whole resolution level by accessing the corresponding member of the group and slicing the whole domain.
Note
The attribute name of all the pixel cells stored in a TileDB array is defined as intensity.
and visualize it as following:
transposed_img = img.transpose(1, 2, 0)
norm_img3d = cv2.normalize(
src=transposed_img,
dst=None,
alpha=0,
beta=255,
norm_type=cv2.NORM_MINMAX,
dtype=cv2.CV_8U,
)
pylab.imshow(norm_img3d)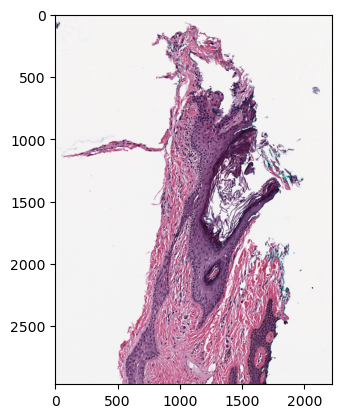
Warning
The TileDB-Py API is built for general purpose use and doesn’t assume anything about the data you’re working with (like the fact that it’s an image). This means that when you select parts of an image by using slicing, you may need to transpose the data afterwards. Transposing essentially reorders the data so that it’s in the correct format for other image processing libraries to understand.
Slice a resolution level
You can slice image data of a specific level with the read_region by defining the upper left coordinates and the size of your slice.
transposed_img = img.transpose(1, 2, 0)
norm_img3d = cv2.normalize(
src=transposed_img,
dst=None,
alpha=0,
beta=255,
norm_type=cv2.NORM_MINMAX,
dtype=cv2.CV_8U,
)
pylab.imshow(norm_img3d)