Single-Cell (SOMA)
TileDB is an ideal solution for managing single-cell data. It introduces a novel data model called SOMA, which allows it to structure single-cell data for unprecedented performance and interoperability with popular tools. Read the Structure: Single-cell section for more details on SOMA, TileDB’s programmatic features, and tool integrations. This section focuses mostly on TileDB’s catalog features on the UI console.
Add SOMA
You can programmatically ingest various different single-cell file formats into the TileDB SOMA model for single-cell, which is covered in detail in section Structure: Single-cell. Similar to arrays, you can create a single-cell dataset first, and register it in a second step, either from the UI or programmatically.
From the UI, you can register an existing single-cell dataset as follows:
- Navigate to the
Assetstab from the right menu. - Select the
Add assetbutton. - From the pop-up window, select
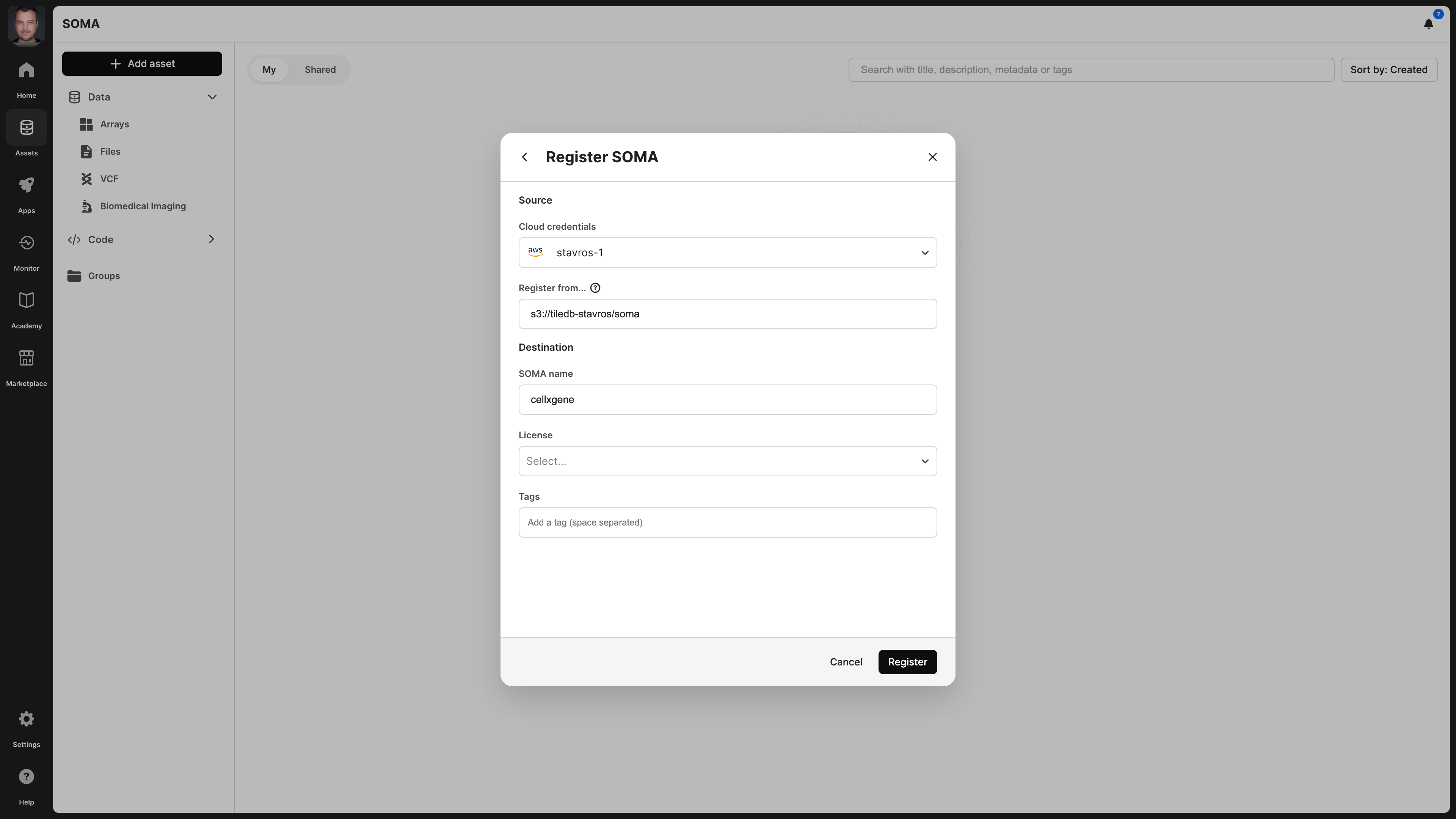
Data, expand theLife Scienceschoice, selectSOMA, and thenRegister SOMA group. - From the new window, select your Cloud credentials that can access the physical location where the SOMA dataset is stored (you must have already set these up in your account
Settings), input the physical location of your SOMA dataset in the Register from… field, add a SOMA name for this dataset, and optionally select a License and add Tags that facilitate catalog search. - Select Register.
You can programmatically register a SOMA dataset as follows:
tiledb.cloud.asset.register(
storage_uri="s3://<bucket>/<soma_name>",
namespace="<account>", # Optional, you may register it under your username, or one of your organizations
name="<soma_name>", # Could be different from the physical SOMA dataset name
description=None, # Optional, this will appear under Overview
credentials_name="<credentials>", # Required, which AWS credentials from your account can access the SOMA dataset.
# You must have already added your AWS credentials in your account settings
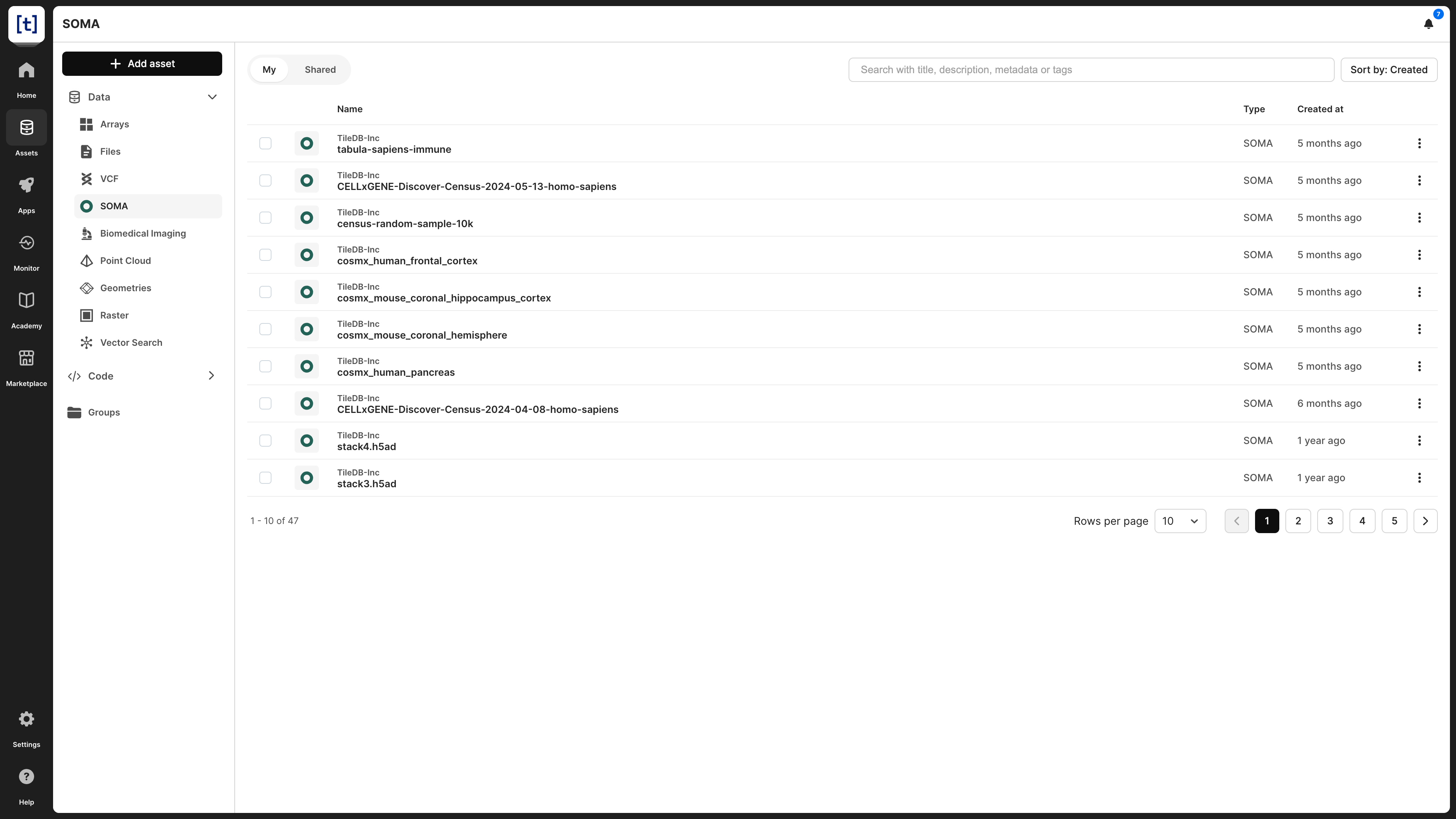
)A registered SOMA dataset will appear under Assets -> Data -> SOMA in the TileDB catalog.
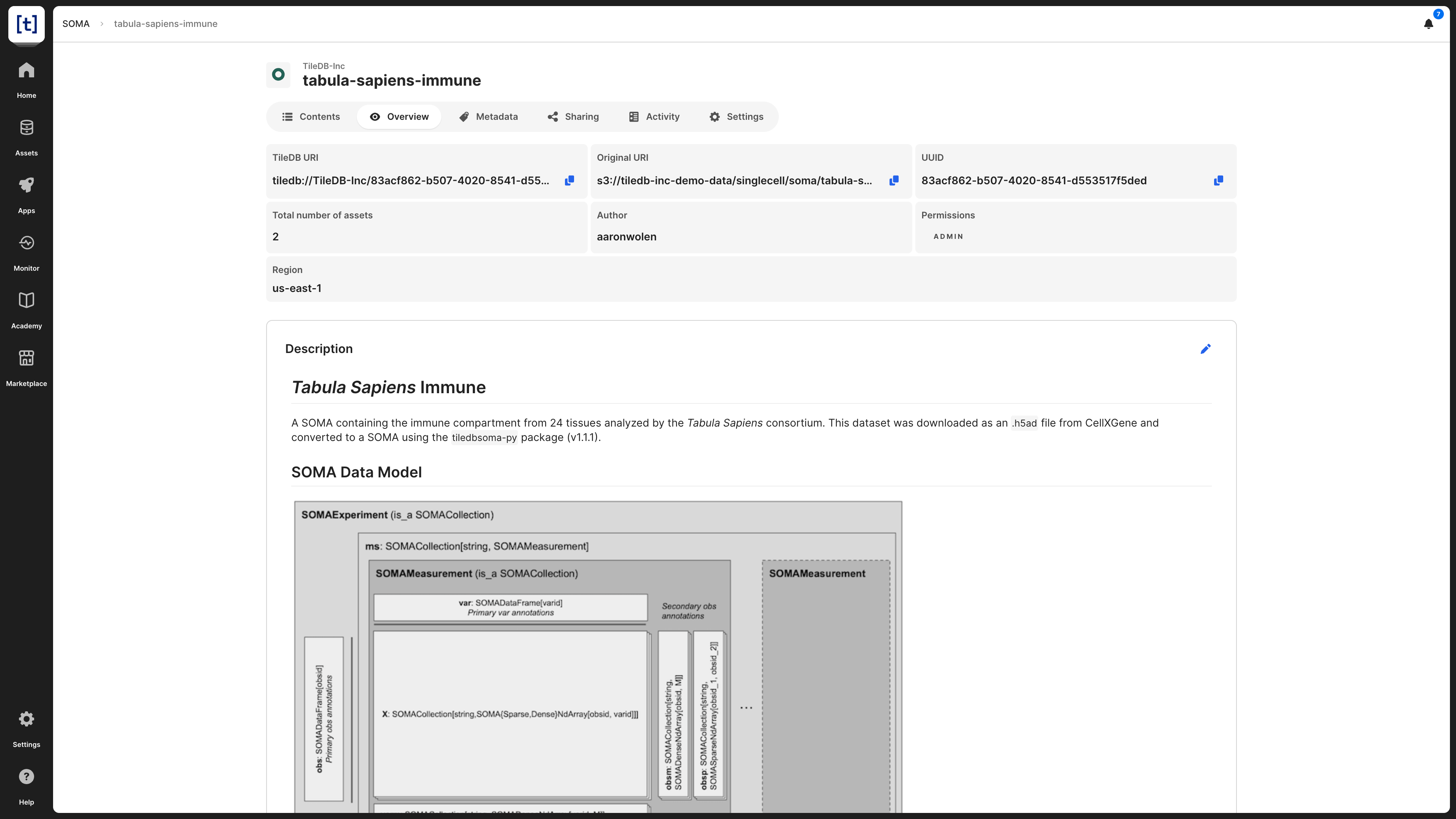
Overview
In this screen, you can find basic information about the SOMA dataset:
SOMA name - This appears at the very top of the screen, and consists of the account name and the name you provided to the SOMA dataset when registering it.
Description - If you provided a description to the SOMA dataset (programmatically or in
Settings), it is visible here. The description is indexed and searchable in the catalog. Therefore, it’s recommended to add a meaningful description for all your assets.License - The type of license for the SOMA dataset, especially if you are making this publicly available.
Tags - These can be used for efficient search in the catalog.
UUID - The unique identifier for the SOMA dataset.
Original URI - The location on cloud storage where the SOMA dataset is physically stored.
TileDB URI - The unique resource identifier for TileDB, based on which you can call the SOMA dataset when coding. It comprises the namespace identifier and the UUID of the SOMA dataset.
Author - Which account registered the SOMA dataset.
Permissions - What rights the current user has on this SOMA dataset. Possible values are
READandADMIN.Number of assets - TileDB models the SOMA dataset as a TileDB group, which may contain other TileDB groups and TileDB arrays.
It is important to understand how to refer to your SOMA dataset programmatically. You can do it in two ways:
- Using the TileDB URI format
tiledb://<account>/<soma_name>. This is the most user-friendly way, but TileDB allows duplicated SOMA dataset names, and if you have a SOMA dataset with a non-unique name, this will throw an error. - Using the TileDB URI from the asset’s Overview tab (that is, the URI with format
tiledb://<account>/<UUID>). TileDB URIs referencing the asset’s UUID are unique. Thus, this method will always work.
You can programmatically get overview information about the SOMA dataset with the following command:
# The following will return a JSON file with various info about the SOMA dataset.
tiledb.cloud.asset.info("tiledb://<account>/<soma_name>")Contents
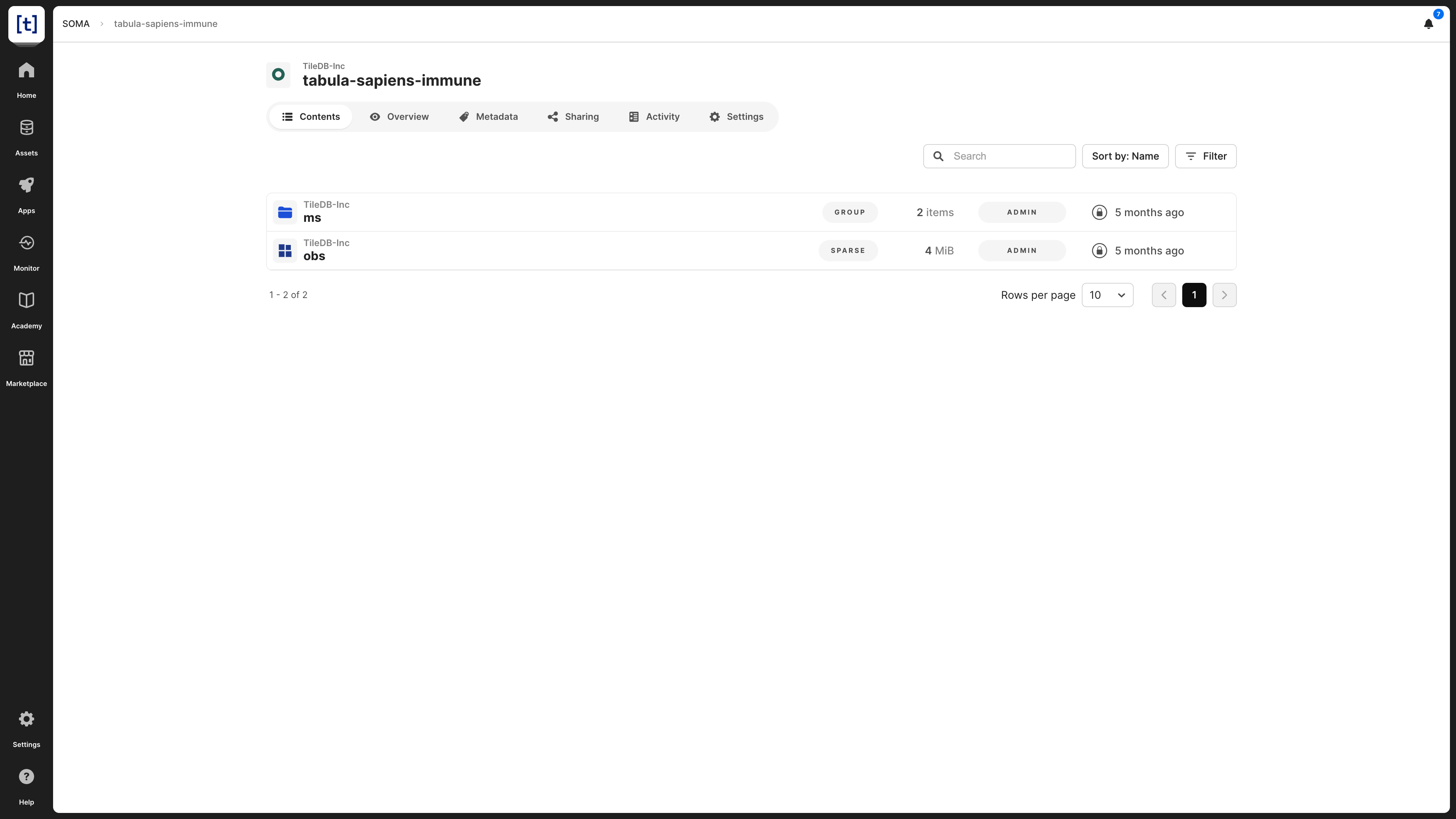
TileDB models SOMA datasets as TileDB groups, which may contain TileDB arrays and other TileDB groups. The contents of a SOMA dataset are visible in the Contents tab, where you can browse them and see their details.
Metadata
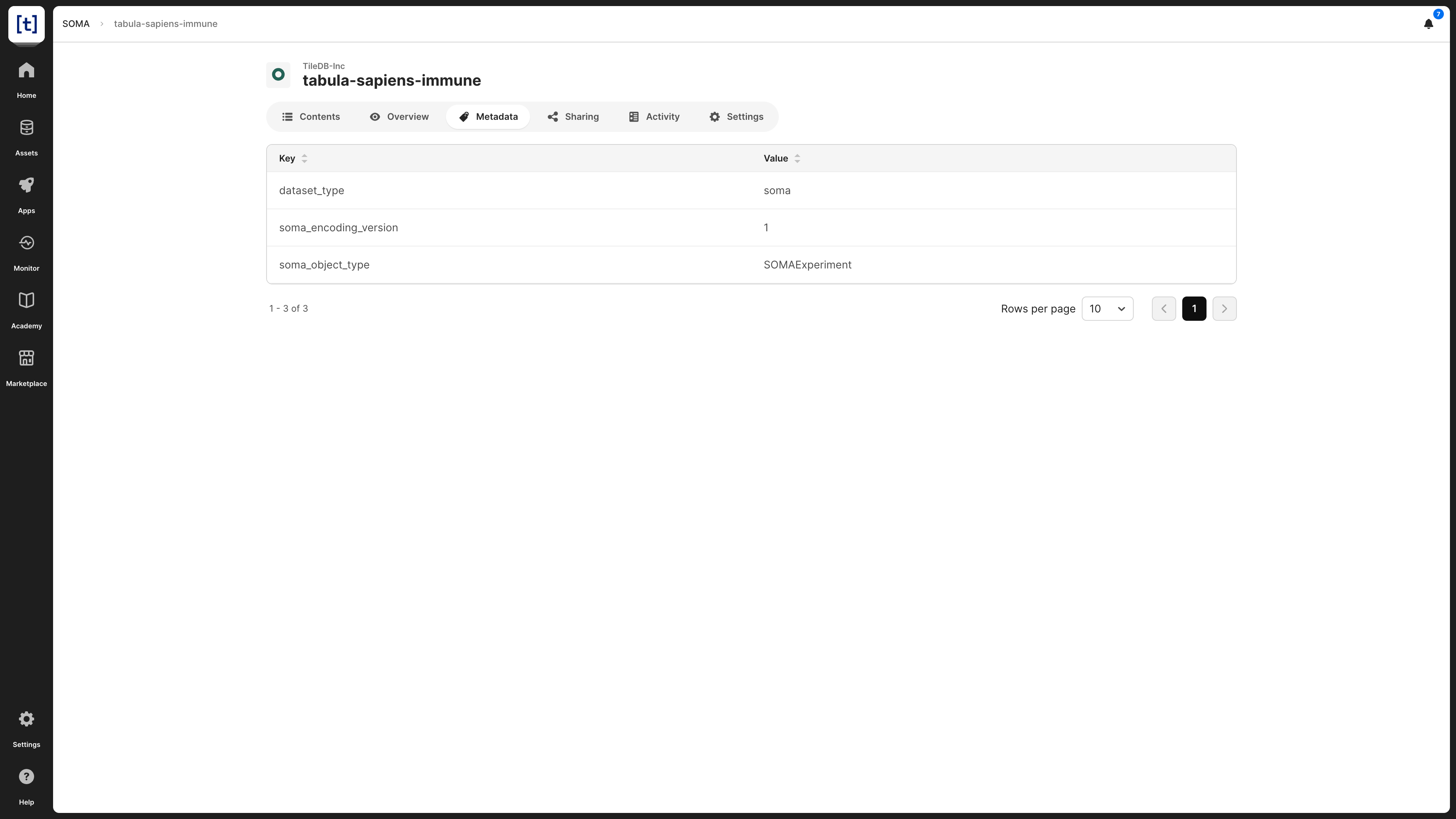
SOMA datasets may be associated with metadata in the form of key-value pairs, which is visible in the Metadata tab.
Settings
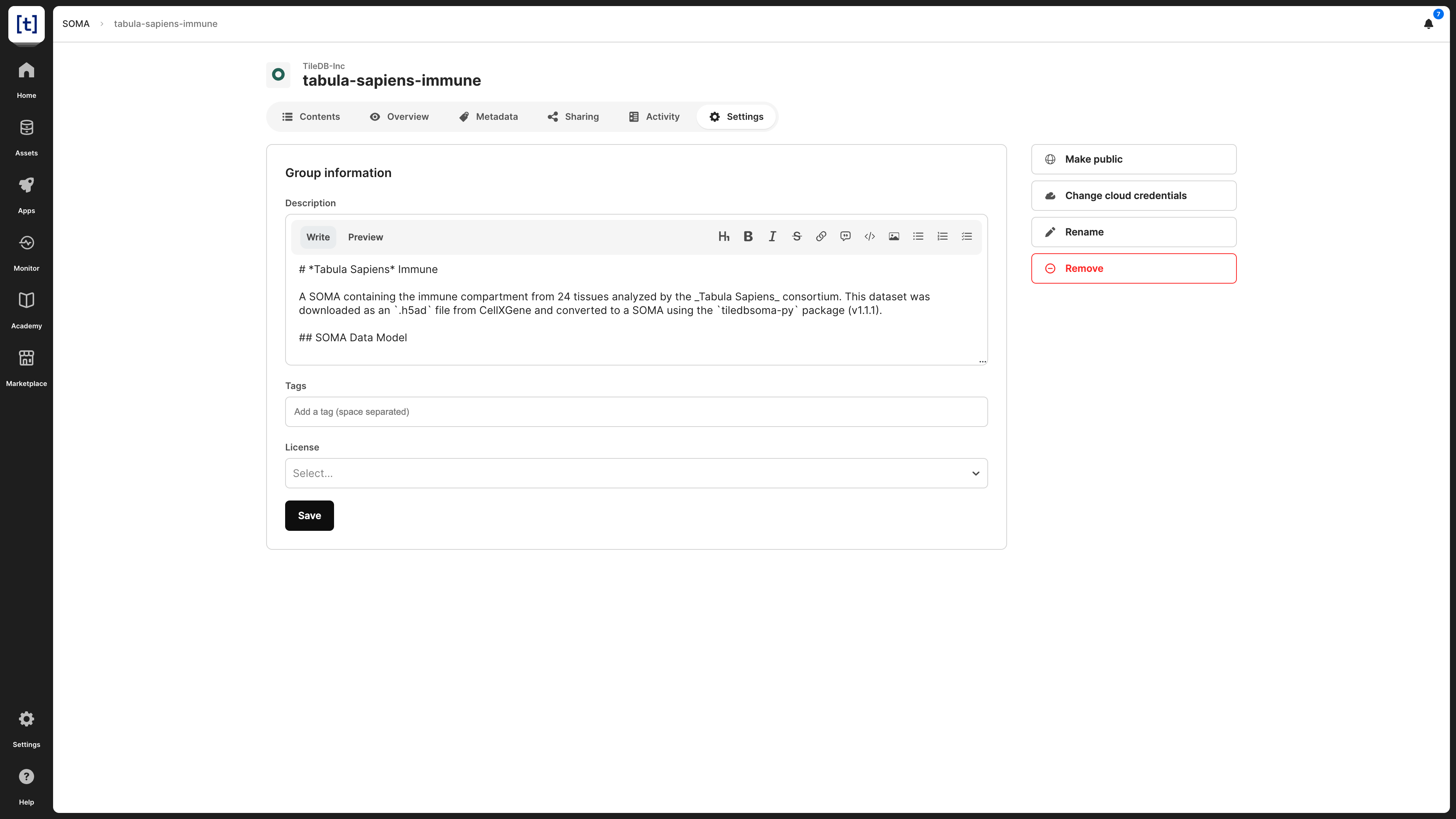
In the SOMA dataset settings, you can modify the following:
- Description - Note that this is indexed and, thus, searchable in the TileDB catalog.
- Tags - These can be used for efficient search in the catalog.
- License - The type of license for the SOMA dataset, especially if you are making this publicly available.
- Make public - If you wish to share the SOMA dataset with all the TileDB users. This will appear in the
Marketplacetab in the left navigation menu. If you make a SOMA dataset public, you can easily change it back to private in the same manner. - Change cloud credentials - Credentials should be provided so that TileDB can securely access the SOMA dataset on the cloud store where it is physically stored.
- Rename SOMA - Read the Rename SOMA subsection below.
- Delete SOMA - Read the Delete SOMA subsection below.
You can programmatically update some SOMA dataset settings with the following command:
tiledb.cloud.asset.update_info(
uri="tiledb://<account>/<soma_name>",
description=None, # Optional - A new description
name=None, # Optional - A new name for the SOMA dataset
tags=None, # Optional - SOMA dataset tags that will be searchable in the catalog
access_credentials_name=None, # Optional - The cloud credentials that access the SOMA dataset (should already exist in your account settings)
)To make a SOMA dataset public programmatically, run the following:
tiledb.cloud.asset.share(
"tiledb://<account>/<soma_name>", namespace="public", permissions="read"
)Rename SOMA
A useful property of the TileDB catalog and the way it registers SOMA datasets is that you can easily rename a SOMA dataset, without physically moving it, thus avoiding the very expensive copying operations entailed in object stores when physically renaming/moving file objects. You can rename a SOMA dataset from the Settings tab.
You can programmatically rename a SOMA dataset as follows:
tiledb.cloud.asset.update_info(
"`tiledb://<account>/<previous_name>`", name="<new_name>"
)Take caution when renaming SOMA datasets, as any URIs including the previous SOMA dataset name will no longer work.
Delete SOMA
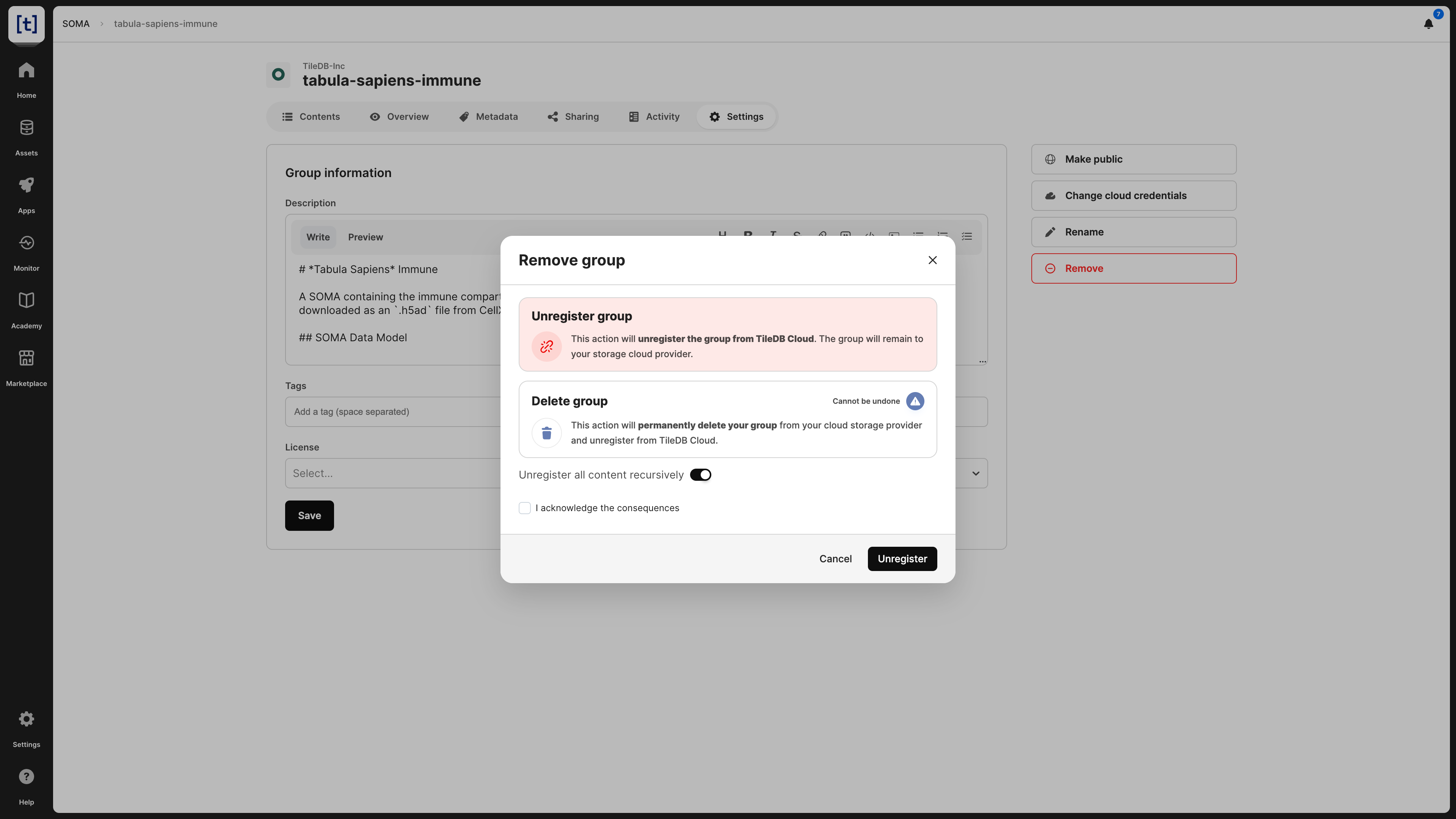
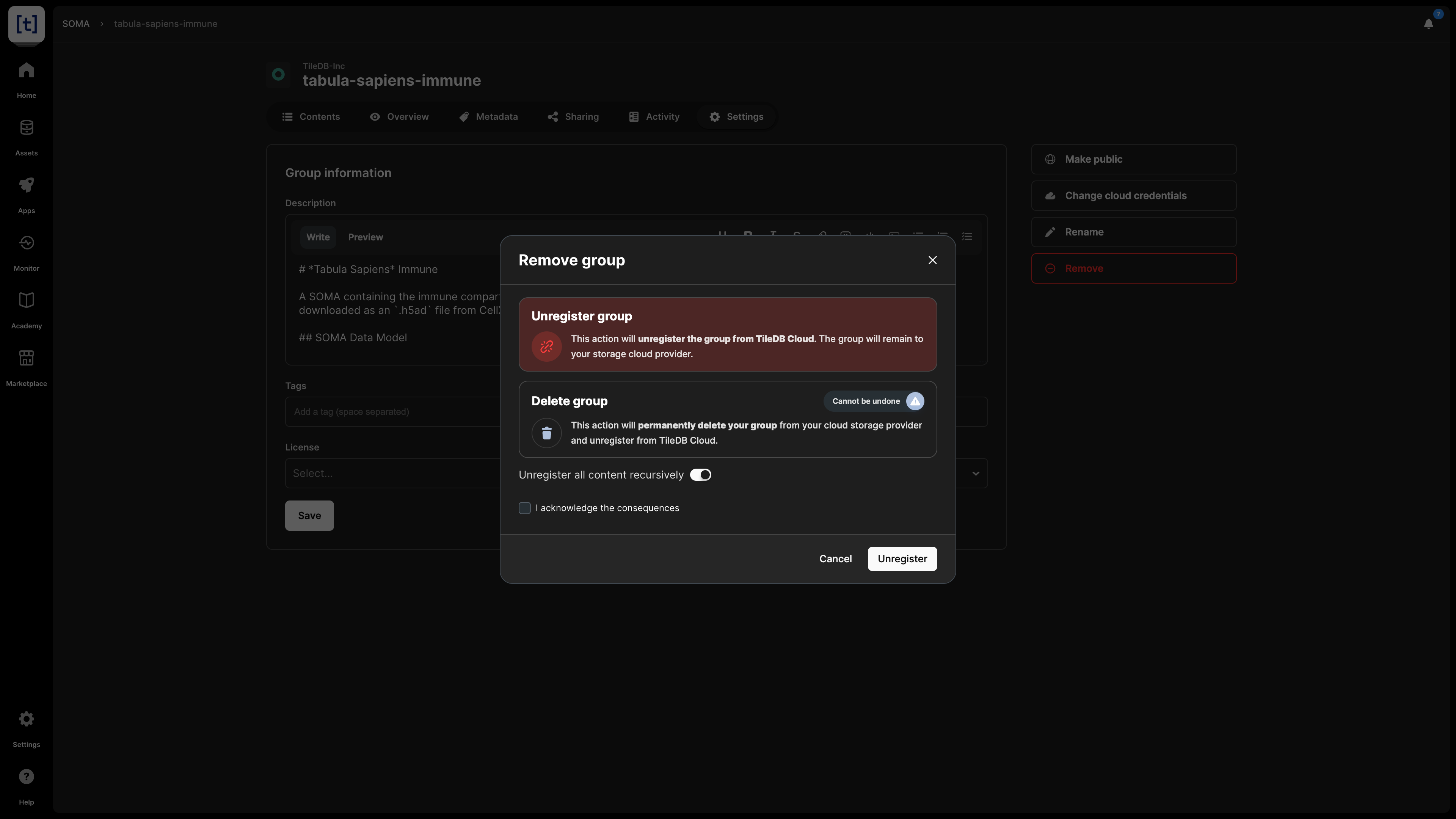
When deleting a SOMA dataset, you have two options:
- Unregister: This operation removes the SOMA dataset from the TileDB catalog, but it does not physically remove it from the object store. Since the SOMA dataset will persist on storage, you can register it again in the TileDB catalog in the future.
- Delete: This operation both unregisters and physically removes the SOMA dataset from storage. Note that this operation cannot be undone.
You can delete the SOMA dataset from the Settings tab, which will prompt you to choose among the two operations above.
You can also programmatically delete or unregister the SOMA dataset as follows:
# Unregister a SOMA dataset
tiledb.cloud.asset.deregister(uri="tiledb://<account>/<soma_name>")
# Delete a SOMA dataset
tiledb.cloud.asset.delete(uri="tiledb://<account>/<soma_name>")