Tables Data Model
We recommend reading the Array Data Model section before proceeding, since TileDB models tables after multi-dimensional arrays.
TileDB represents tabular datasets as arrays. TileDB tables have two main array representation variations, which mainly affect performance, not functionality:
- Tables as dense arrays
- Tables as sparse arrays
The following figure gives some examples.
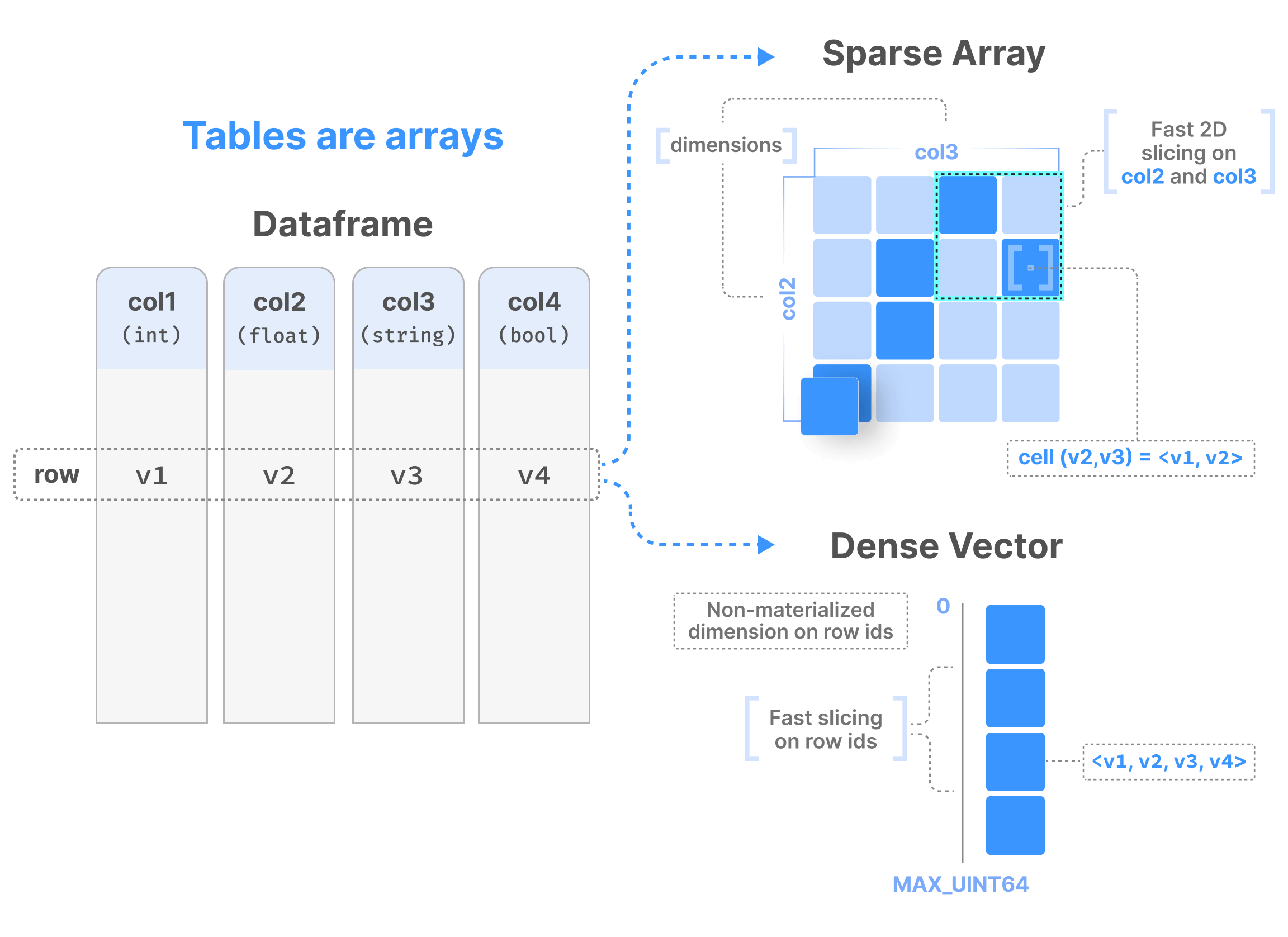
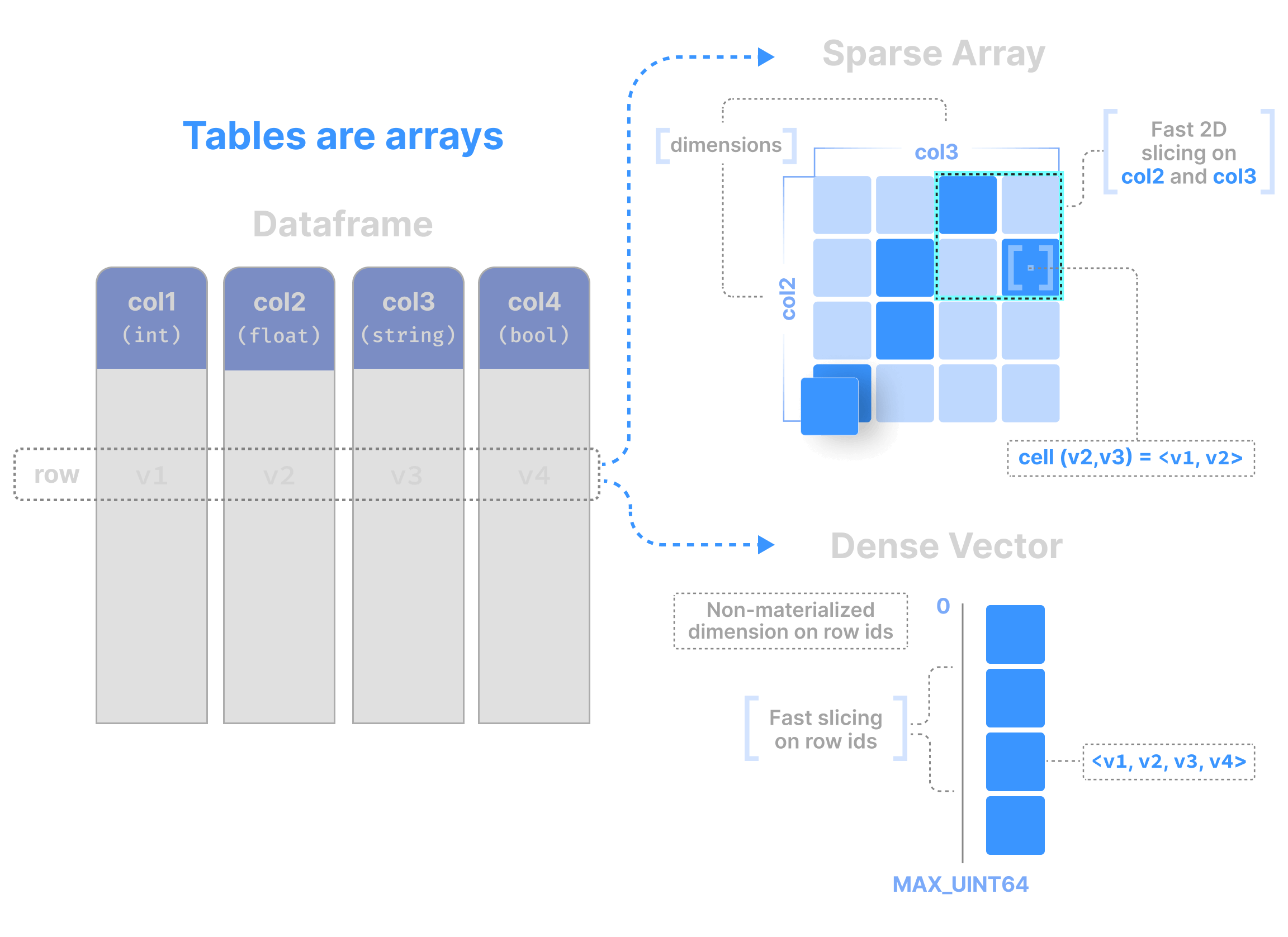
Since tables are arrays, tabular support in TileDB take advantage of all the benefits from arrays, such as efficient indexing, the columnar format with effective compression, and so on.
The next two sections described these two variations in more detail.
Tables as 1D dense arrays
The most basic case is to model a table as a 1-dimensional dense array. In this case, each row is a cell, and all fields (that is, “columns” in traditional tabular systems) are stored as attributes.
TileDB tables have a single uint64_t dimension, which stores a numerically increasing row ID. Since the array is dense, this dimension isn’t materialized on physical storage, but it’s queryable like all other row fields.
This model implies that 1D dense tables have no unique indexing on any table field, which means that any query condition on any field will result in a full table scan. However, this model allows efficient slicing based on row IDs (for example, “return the first 1000 rows, rows 500-2500, and so on”), which you may want when performing a distributed query, where each worker needs to slice a partition of rows.
Tables as ND sparse arrays
The second data model uses \(N\)-dimensional sparse arrays to represent the tabular dataset, where one or more fields are selected as the dimensions. This model allows for very efficient range queries over the dimensions. All other fields are stored as attributes. TileDB still runs a lot of optimizations for conditions and aggregates over attributes, but queries with conditions over dimensions will be much faster due to the underlying indexing they involve.
Visit Array Key Concepts: Indexing for more details on TileDB array indexing.
Sparse arrays in TileDB offer the option to enforce uniqueness on the dimension values, or to allow duplicates. For enforcing uniqueness, you can think of this as TileDB applying a primary index over the dimensions of the array. You can think of allowing duplicates as TileDB adding a clustered index.