TileDB-VCF Architecture
The main code libraries you will use in your population genomics work with TileDB are the following:
- TileDB Embedded: A C++ library (exposing C and C++ APIs) implementing the core array engine of TileDB.
- TileDB-Py: A Python wrapper of TileDB Embedded.
- TileDB-Java: A Java wrapper of TileDB Embedded.
- TileDB-VCF: A C++ library built on top TileDB Embedded, which implements specific VCF functionality (such as efficient ingestion, genomic APIs and efficient queries). It exposes C++, Python and Java APIs.
- TileDB-Cloud-Py: A Python client for TileDB Cloud.
- TileDB-Cloud-Java: A Java client for TileDB Cloud.
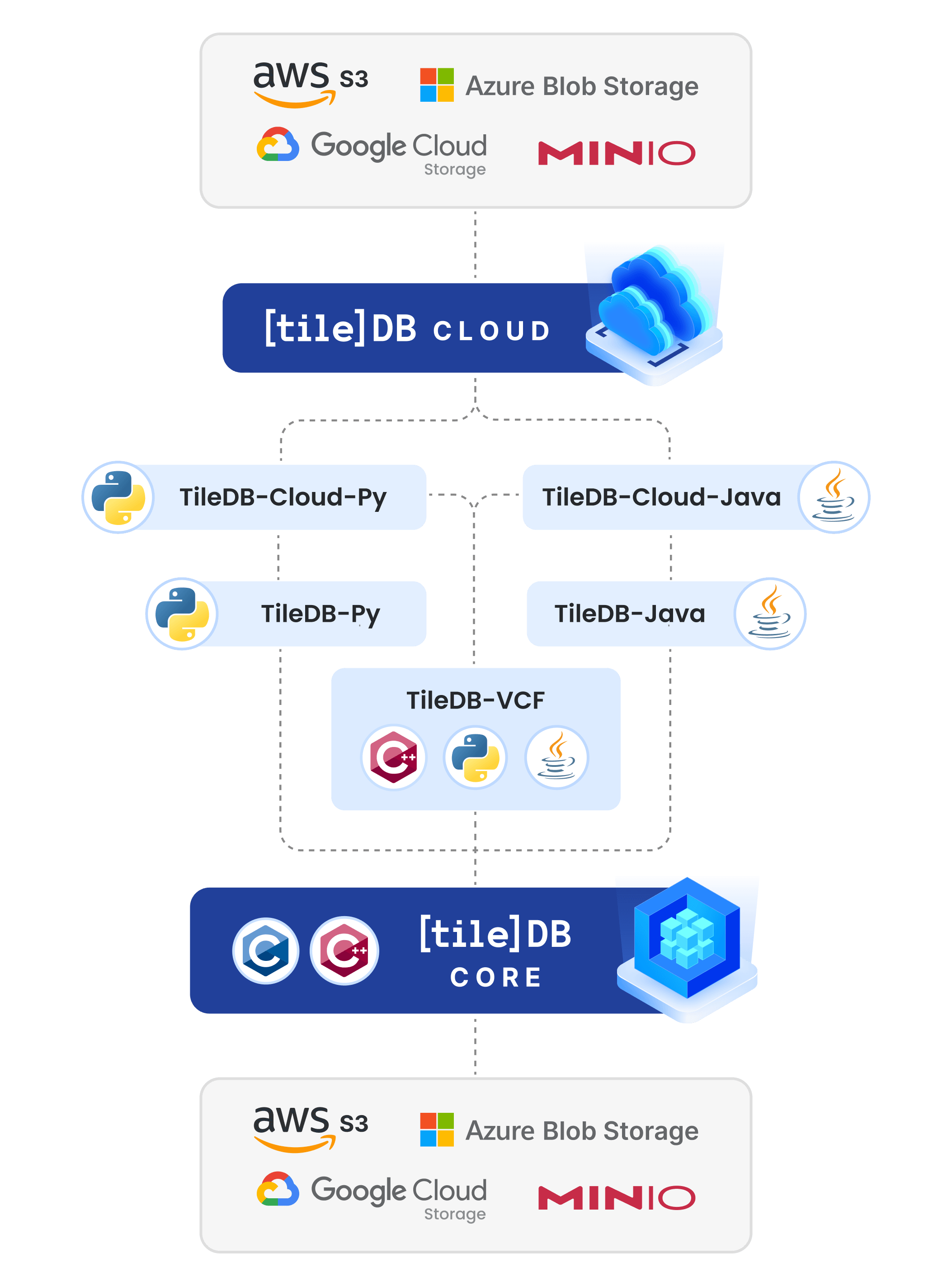
The following figure outlines the interactions among the above libraries. TileDB Embedded is responsible for the bulk of interactions with the preferred backend, which can be either an object store (such as Amazon S3, Google Cloud Storage, Azure Blob Storage or MinIO), or TileDB Cloud. TileDB-VCF in built on top of TileDB Embedded, leveraging the power of arrays. TileDB-Cloud-Py and TileDB-Cloud-Java are useful clients for TileDB Cloud, which implement TileDB Cloud functionality (such as authentication) and some VCF-specific features (such as distributed ingestion). TileDB-Py and TileDB-Java are respectively Python and Java wrappers for TileDB Embedded.
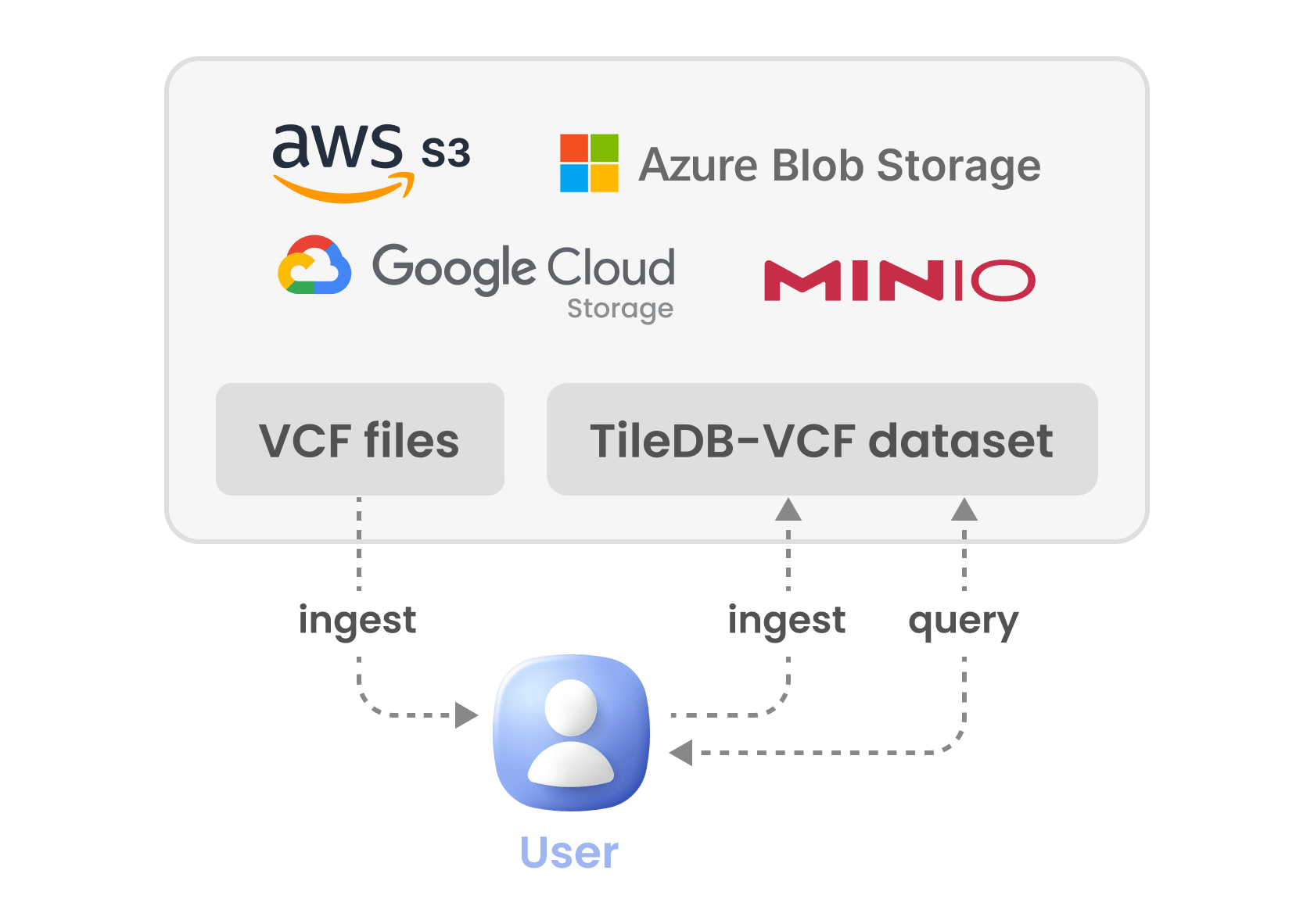
The following figure describes a typical TileDB-VCF workflow, when interacting directly with object stores. The workflow starts with a set of VCF files stored on the object store. The user uses TileDB-VCF to ingest the VCF files into TileDB’s array format. The conversion is lossless. Then the user can use TileDB-VCF to efficiently query the data directly from the object store, without having to download any large files to local storage (TileDB-VCF and TileDB Embedded implement efficient indexes and perform minimal byte range requests to the object store).
For scalable and secure population genomics data management, you can alternatively use TileDB Cloud, as demonstrated in the figure below. The VCF files are stored in an object store supported by TileDB Cloud. You can invoke distributed ingestion using TileDB-VCF, which leverages the scalable computational power of TileDB Cloud to perform it in a highly parallel fashion across numerous cloud workers. Then you can use TileDB-VCF to query the data, in a similar scalable fashion.
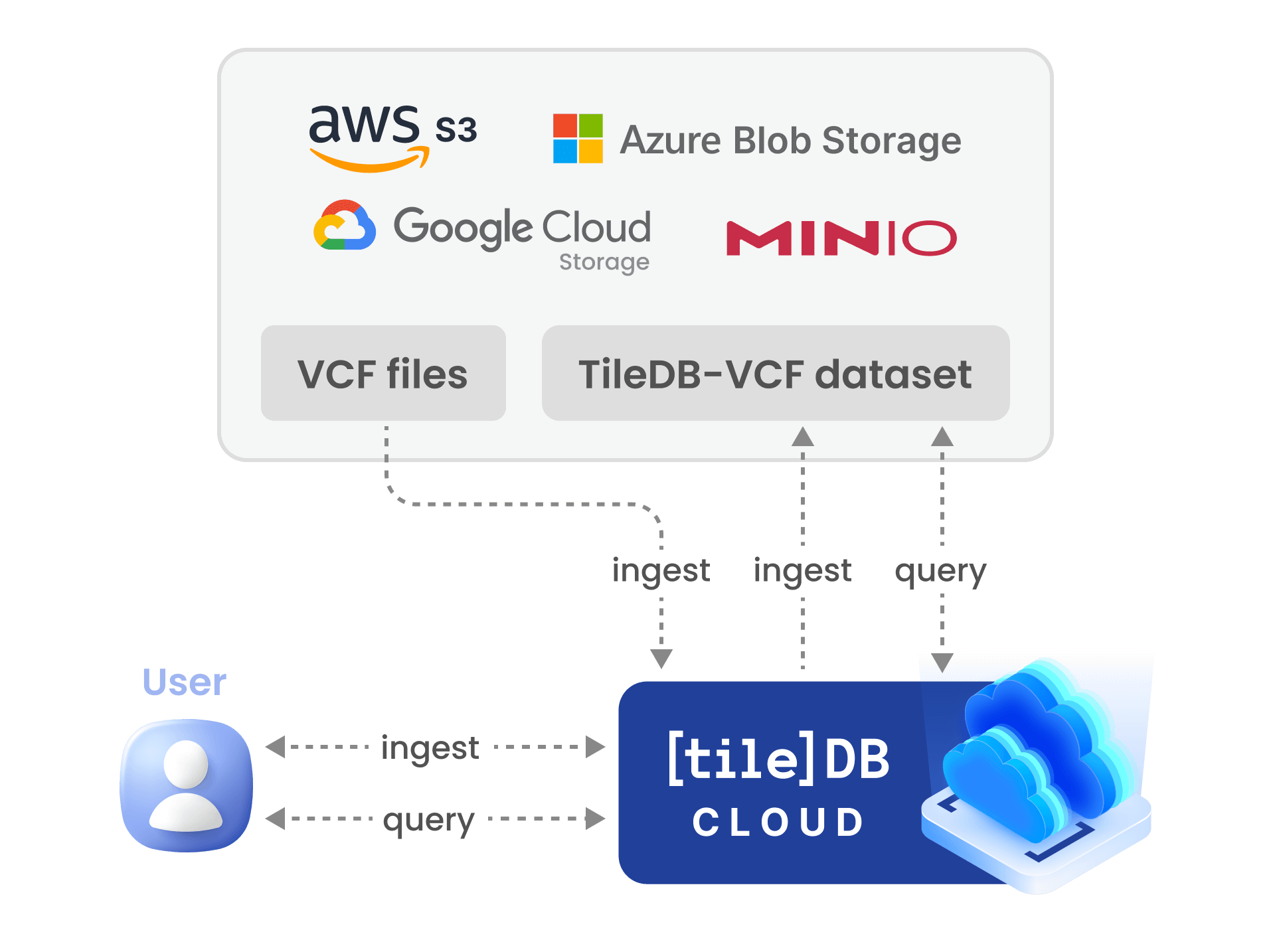
TileDB Cloud also offers a broad spectrum of governance and application building features.