Notebook Assets
TileDB allows you to create, manage, and launch Jupyter notebooks inside its secure infrastructure. Notebooks are an easy way to perform exploratory, interactive data analysis.
Create notebook
From the Assets page (found in the left navigation menu), select the Add Asset button, and select Code and then Notebook. You have two choices:
- Create an empty notebook
- Upload an existing notebook from your machine
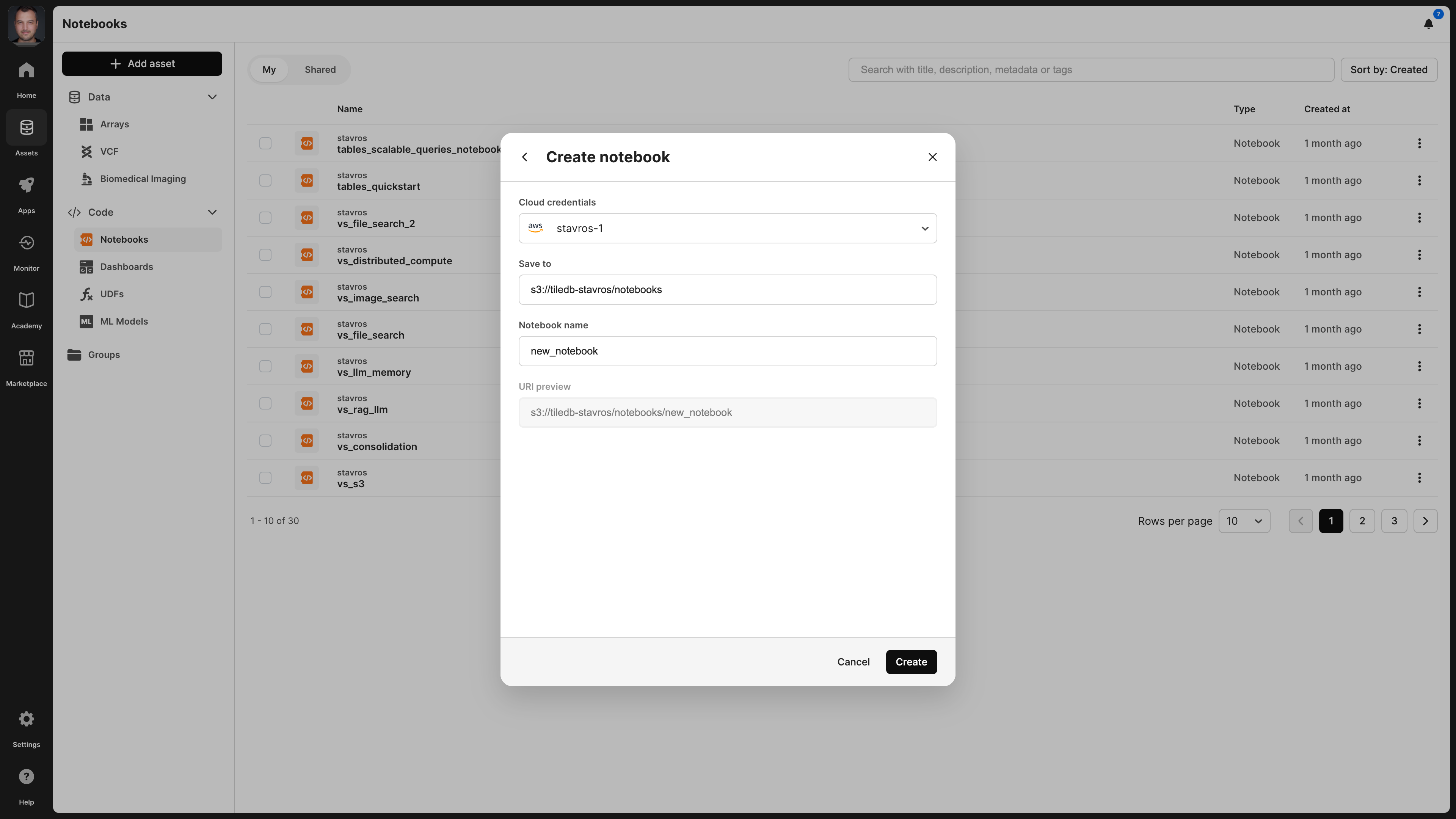
When creating an empty notebook, you need to provide the physical storage path, notebook name, and cloud credentials that can access the physical path.
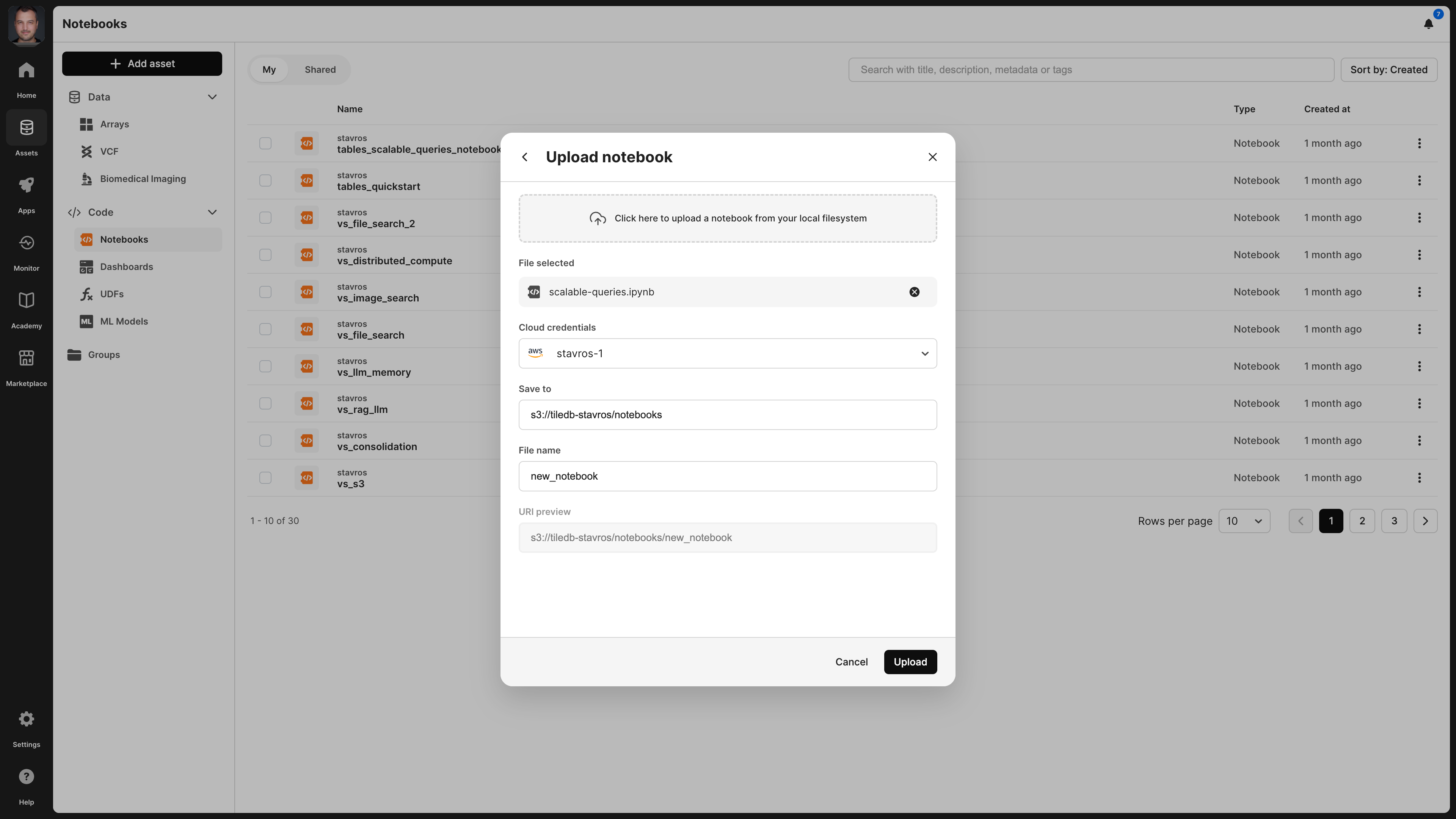
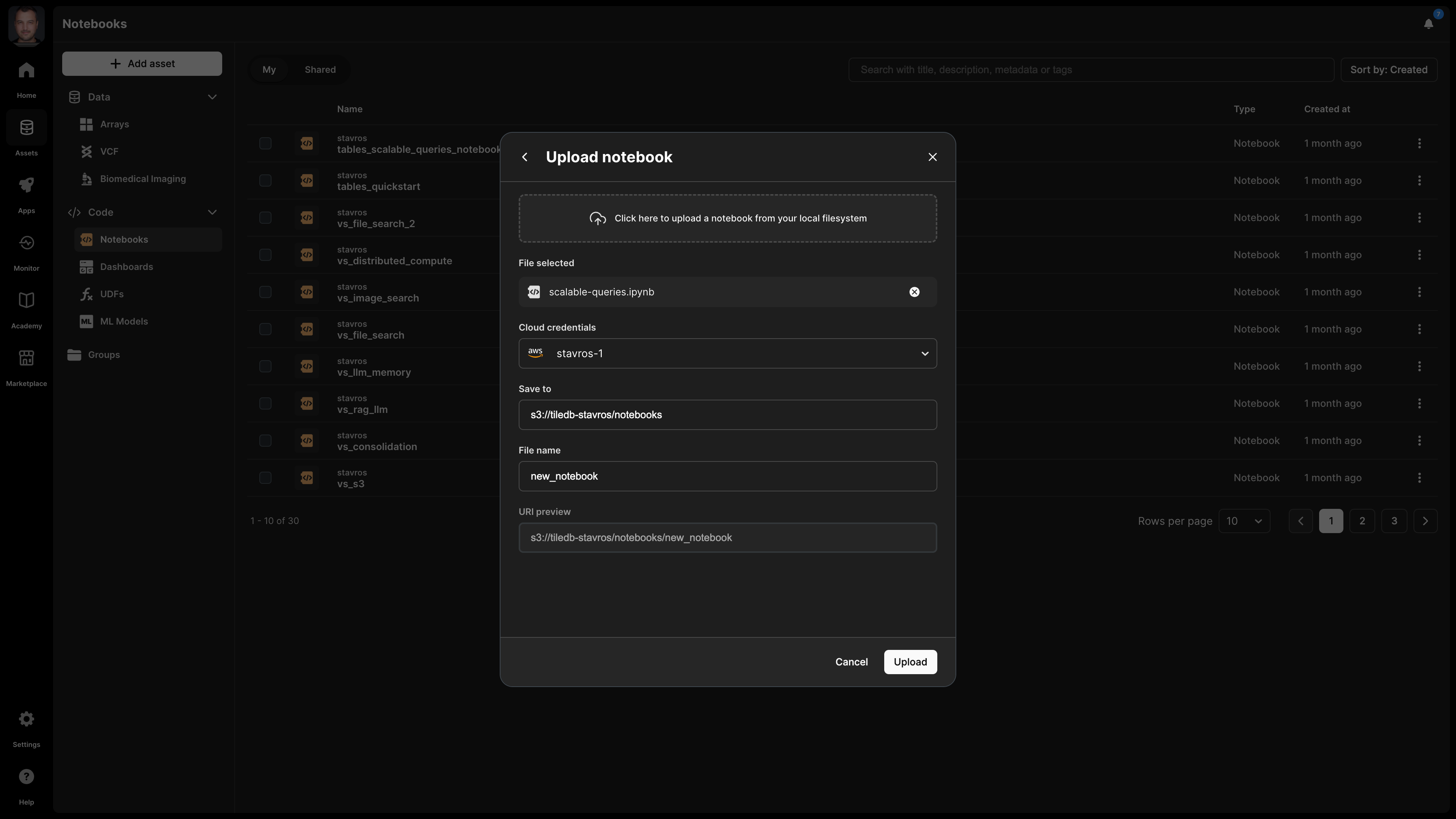
When uploading an existing notebook, you need to provide the local file, the physical storage path, notebook name, and cloud credentials that can access the physical path.
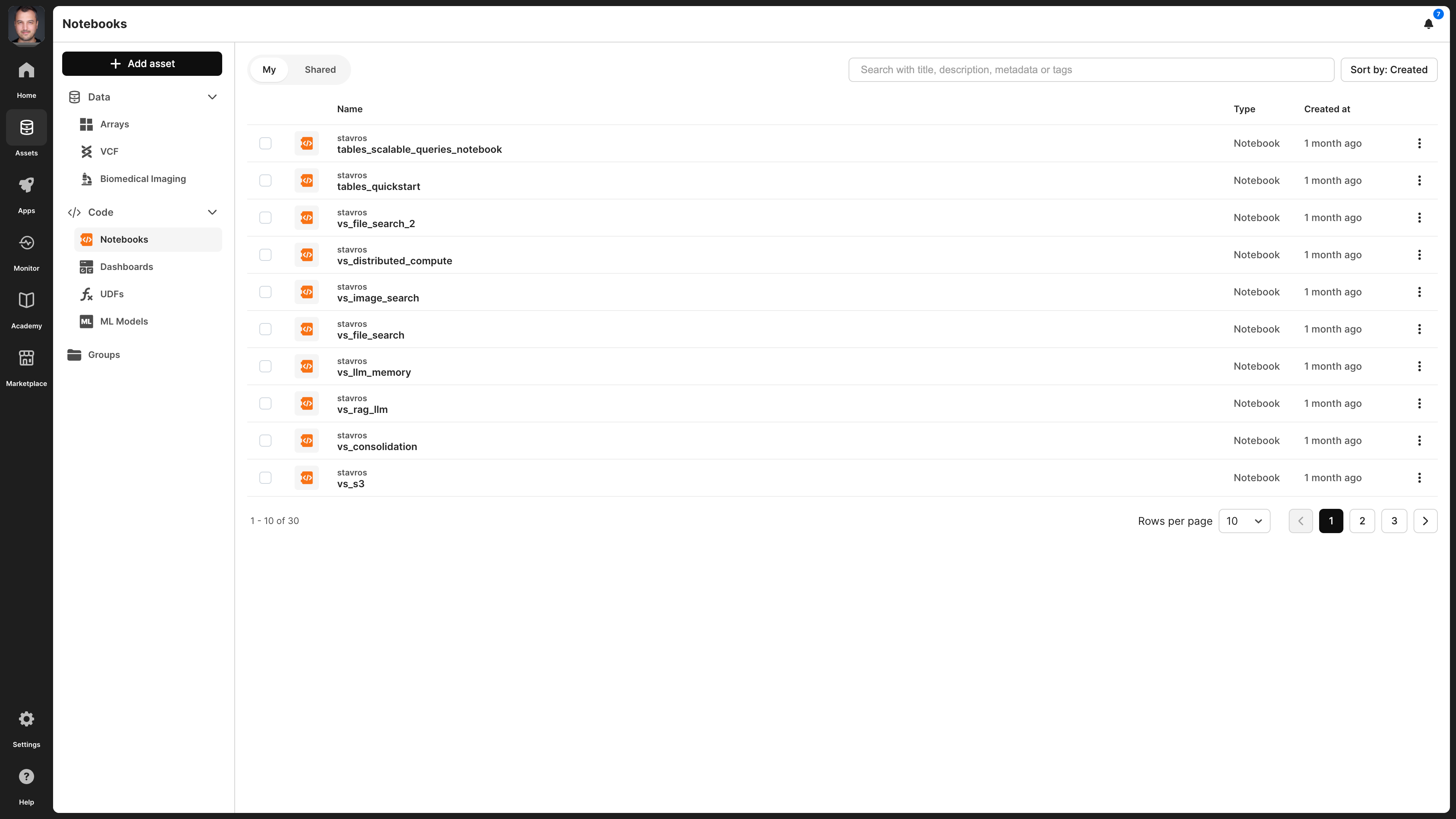
Once created, your notebook will appear under Assets -> Code -> Notebooks.
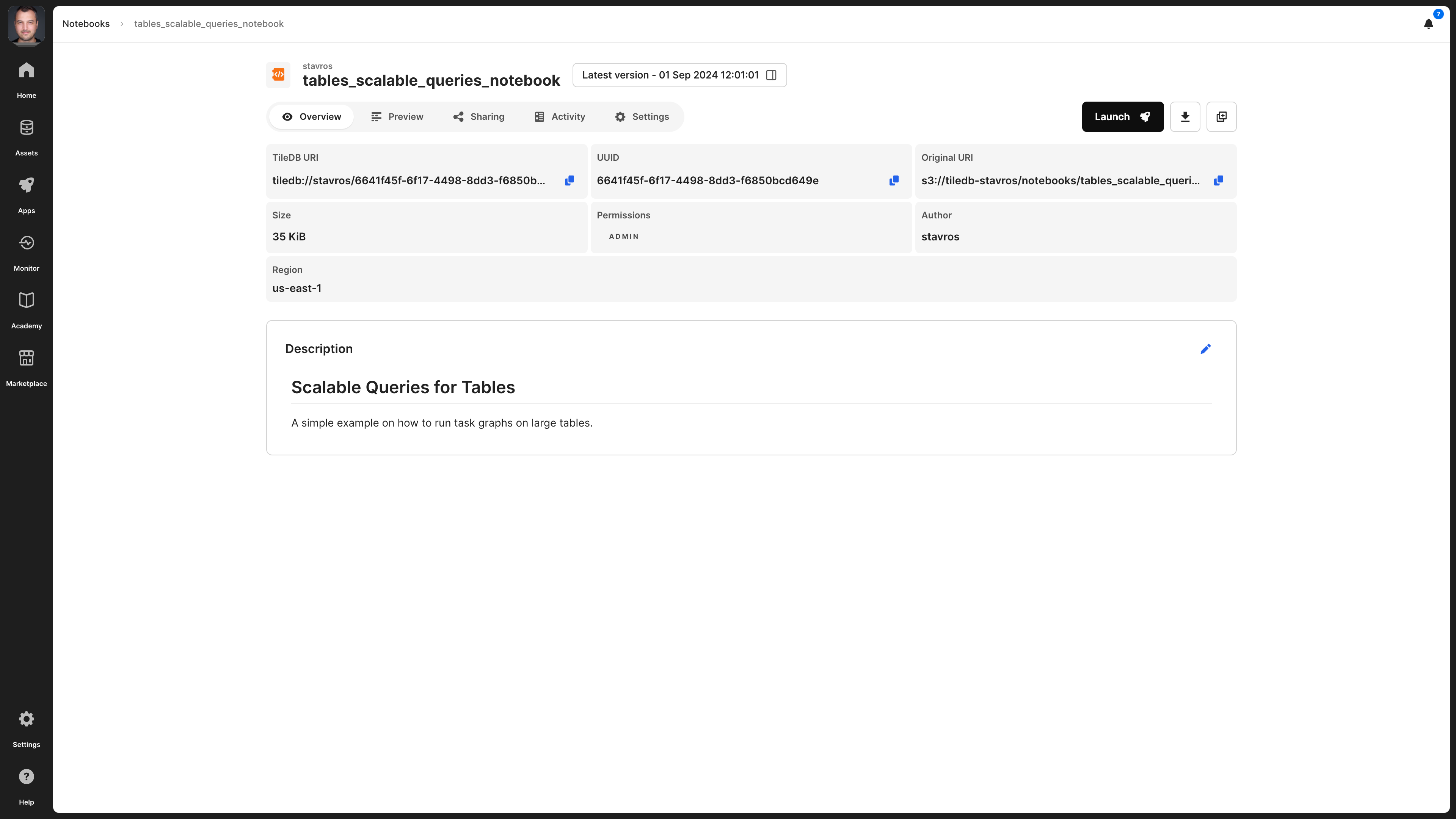
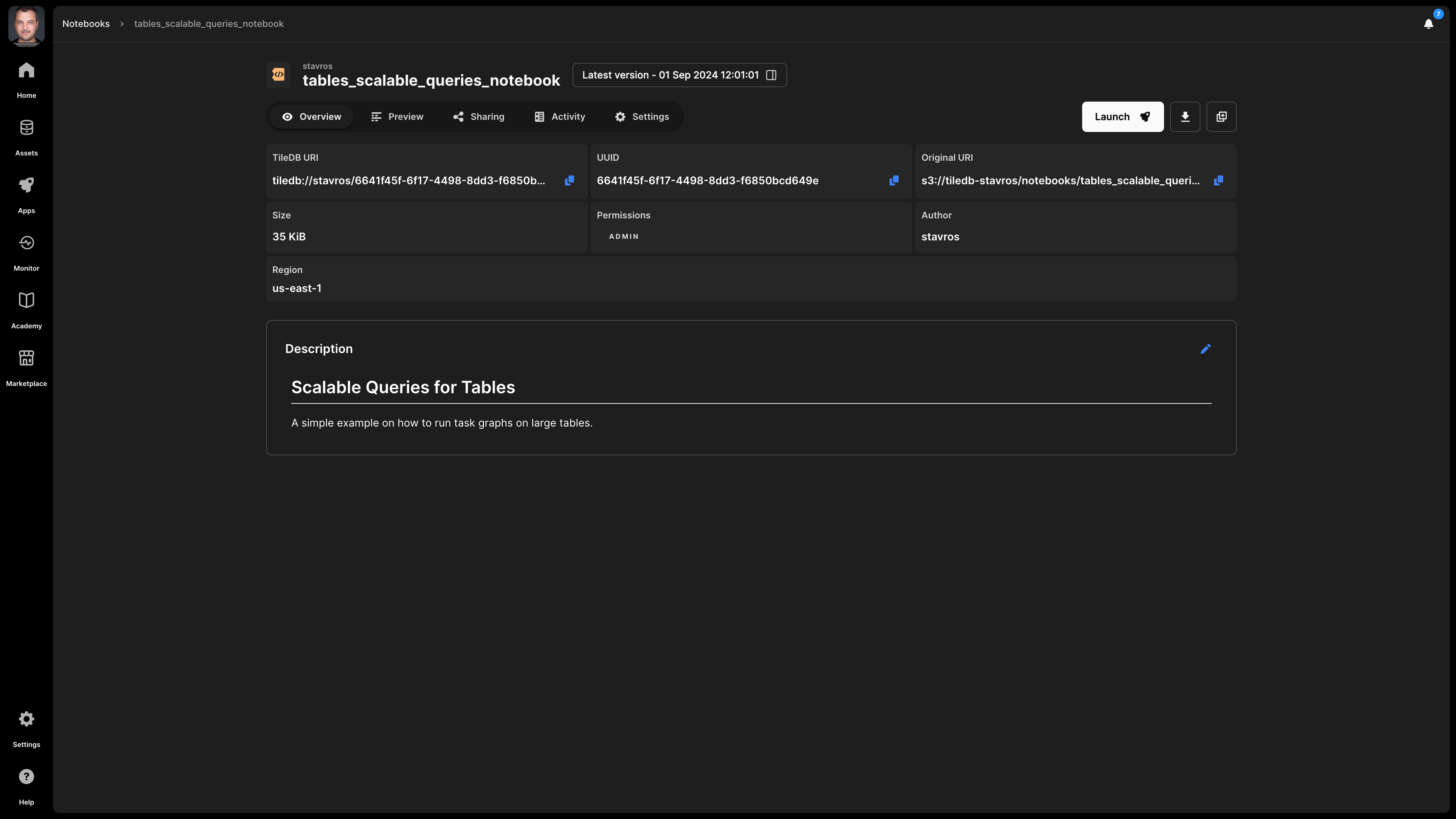
Overview
The Overview tab provides basic information about a notebook:
- Description - If you provided a description to the notebook (e.g., from
Settings), it is visible here. The description is indexed and searchable in the catalog. Therefore, it’s recommended to add a meaningful description for all your assets. - TileDB URI - The unique resource identifier for TileDB, based on which you can refer to the notebook. It contains the namespace and the UUID of the asset.
- UUID - The unique identifier for the notebook.
- Original URI - The location on cloud storage where the asset is stored. This property is visible only to the admin of the asset.
- Permissions - What rights the current user has on this asset.
- Image - This is the default server environment under which the notebook will run. It is configurable through
Settings. Launching a notebook will ask for this image. - Server profile - This shows the specifications of the server that will run the notebook upon its launch, among the options given by TileDB. It is configurable like the image option in
Settings. - License - If available, under which license the asset is available. Editable through
Settings, if you are the admin of the asset. - Tags - Any tags on the asset, if available, which will be searchable in the TileDB catalog.
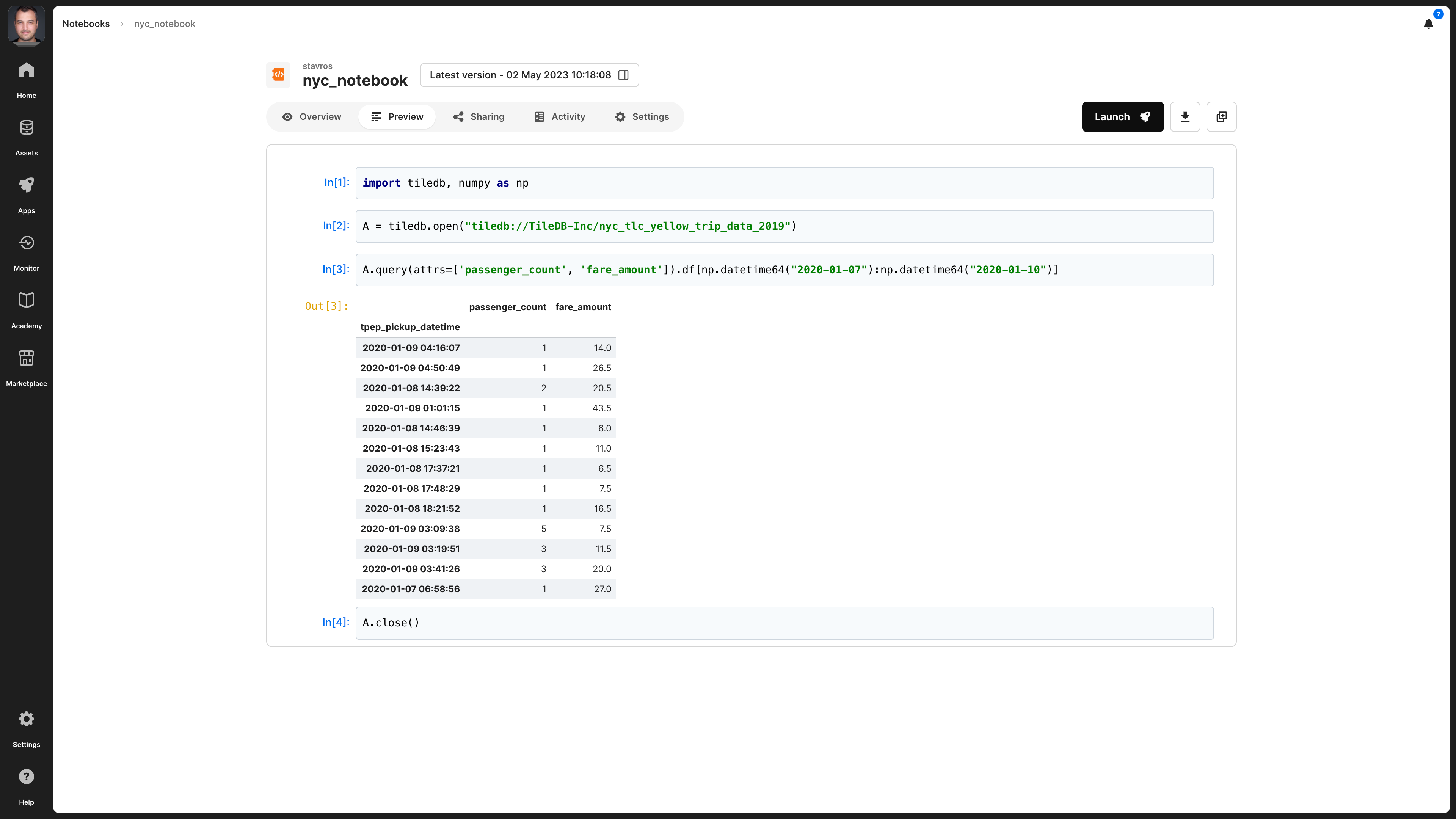
Preview
You can see a human-readable rendering of the notebook under the Preview tab.
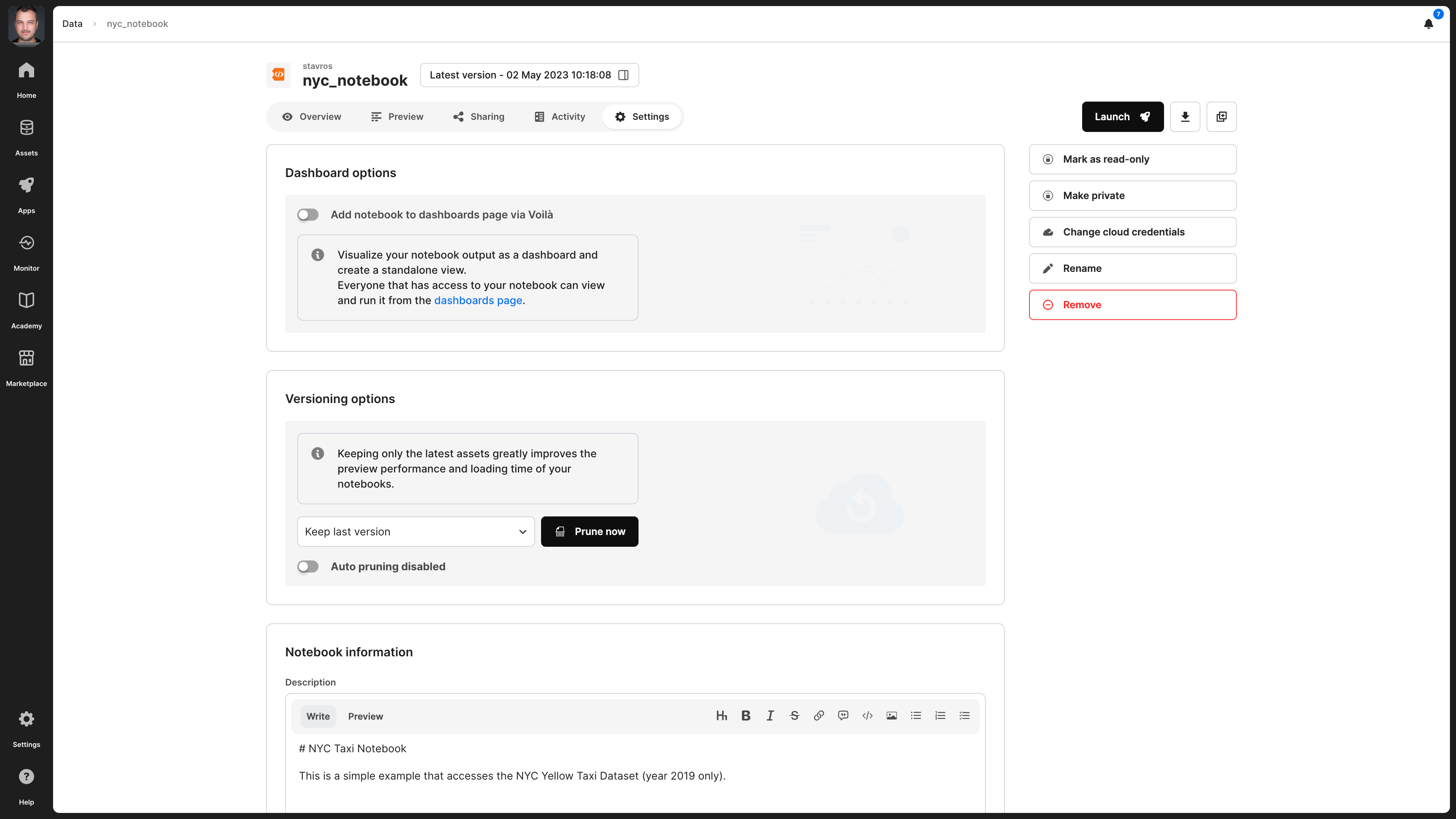
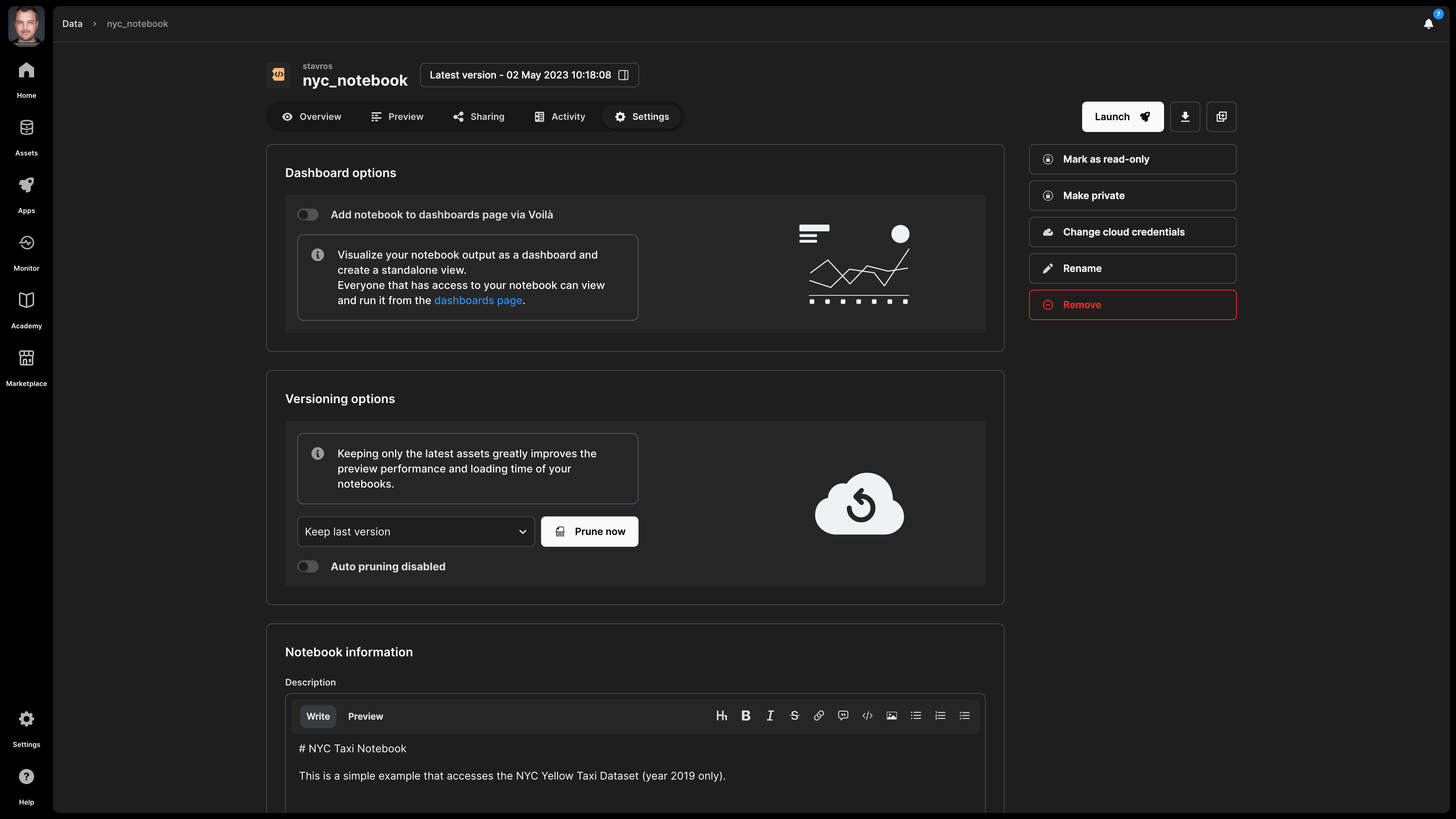
Settings
In the notebook settings, you can modify the following:
- Dashboard options - A notebook can be converted into a dashboard - visit the Dashboards section for more details.
- Versioning options - You can manage the number of versions for your notebook - visit the Versioning subsection below.
- Description - Note that this is indexed and, thus, searchable in the TileDB catalog.
- License - The type of license for the notebook, especially if you are making this publicly available.
- Tags - These can be used for efficient search in the catalog.
- Mark as read-only - This is useful if you want to prevent any notebook changes by you or someone with whom you shared the notebook.
- Make public - If you wish to share the notebook with all the TileDB users. This will appear in the
Marketplacetab in the left navigation menu. If you make a notebook public, you can easily change it back to private in the same manner. - Cloud credentials - Credentials should be provided so that TileDB can securely access the notebook on the cloud store where it is physically stored.
- Server type - Change the server with which to launch the notebook.
- Default region - The region in which you wish to launch the notebook server by default.
- Rename notebook - Read the Rename notebook subsection below.
- Delete notebook - Read the Delete notebook subsection below.
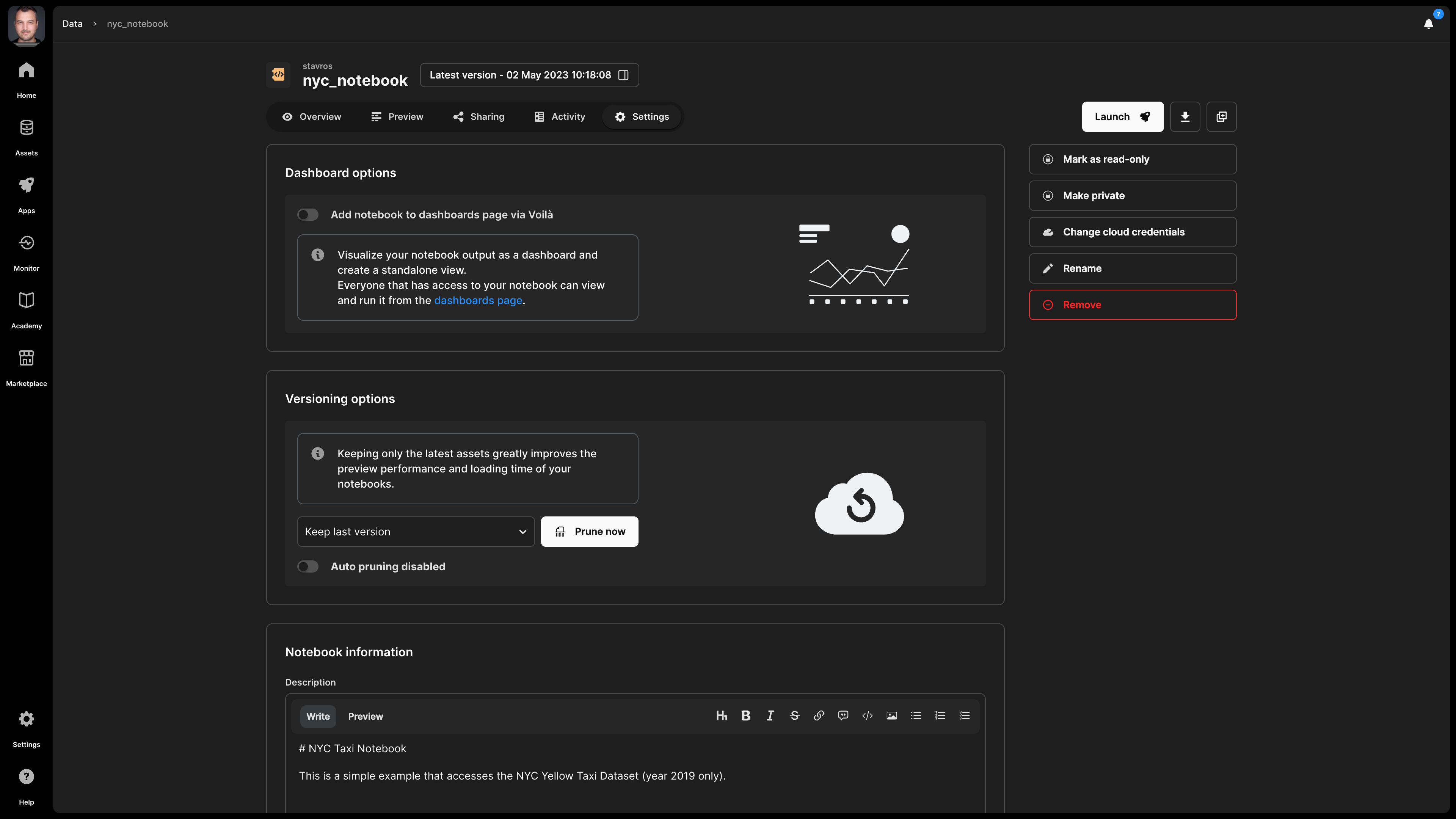
Versioning
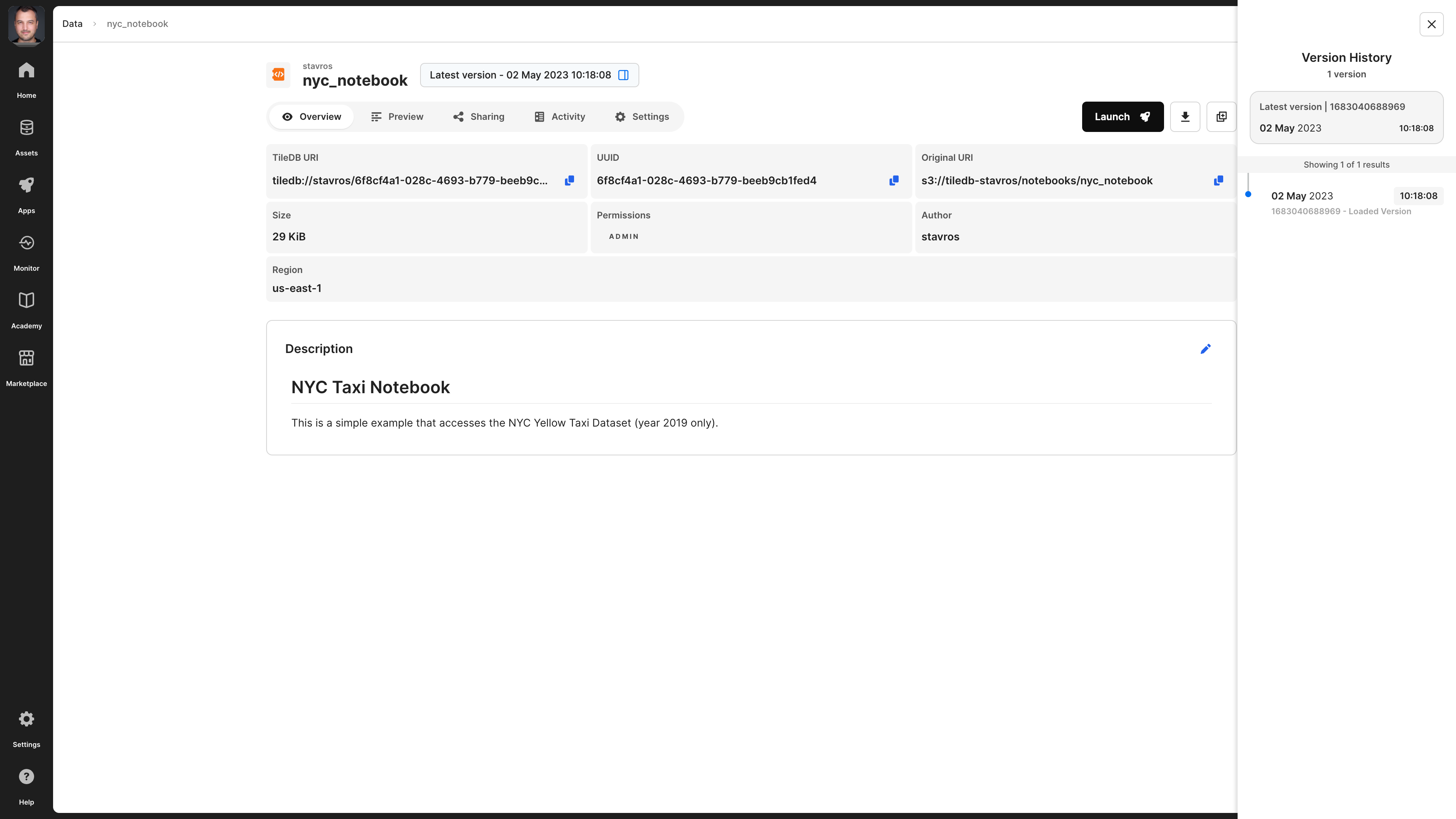
TileDB supports versioning for notebooks. Every time you edit a notebook (e.g., after launching it on a TileDB server - read the Analyze section for details), TileDB creates a new version. You can select which version to preview by selecting the button next to the notebook name, starting with Latest version - .... This brings up a modal on the right, which allows you to browse and select different notebook versions. Then you can preview or download the selected notebook version.
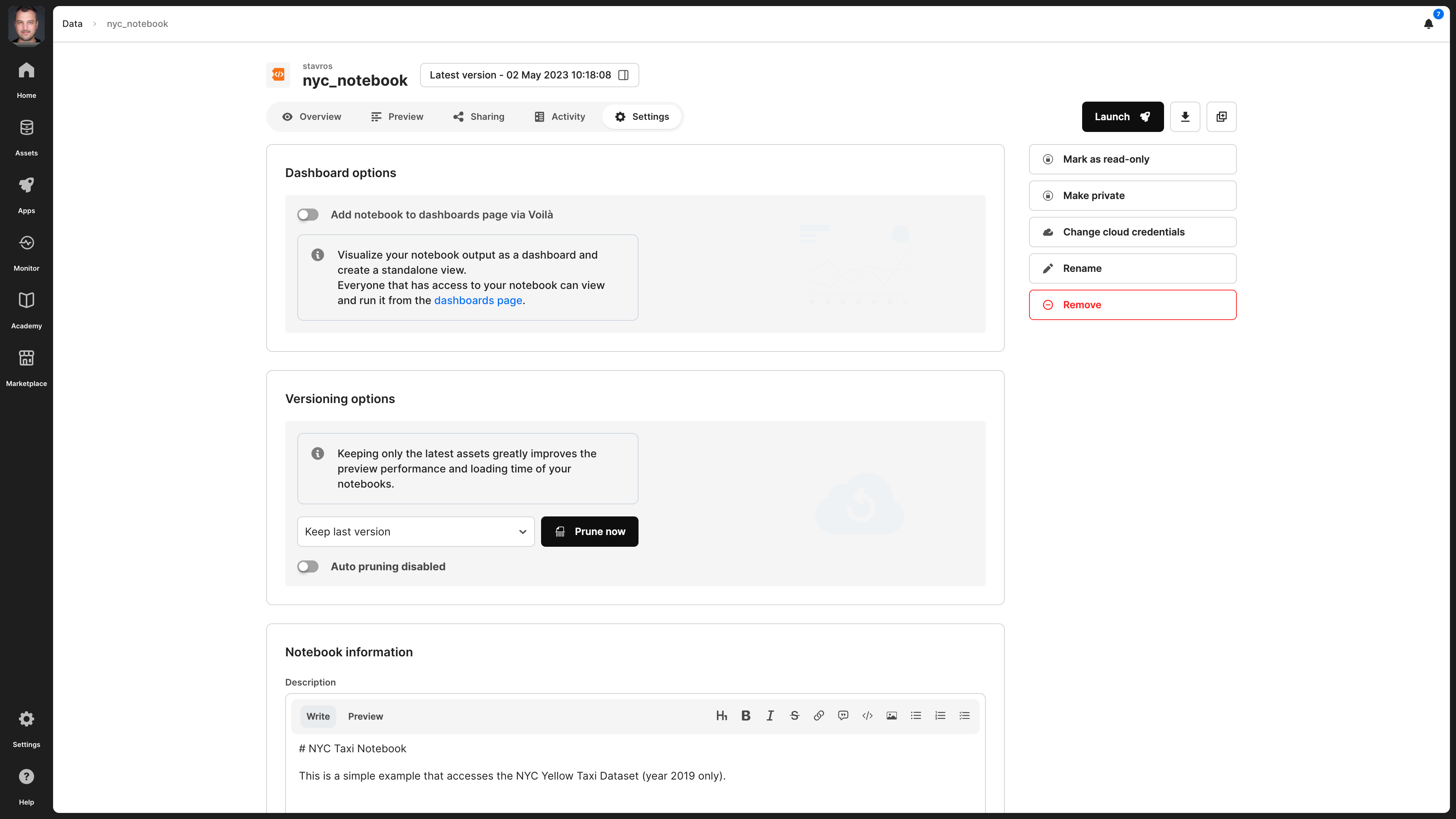
You can prune past versions from the Settings tab. You can also choose to auto-prune, which happens once a day and will keep only the number of versions you select in the drop-down list next to the Prune button.
Download notebook
You can download the notebook in the native, Jupyter-readable format by selecting the Download button next to Launch.
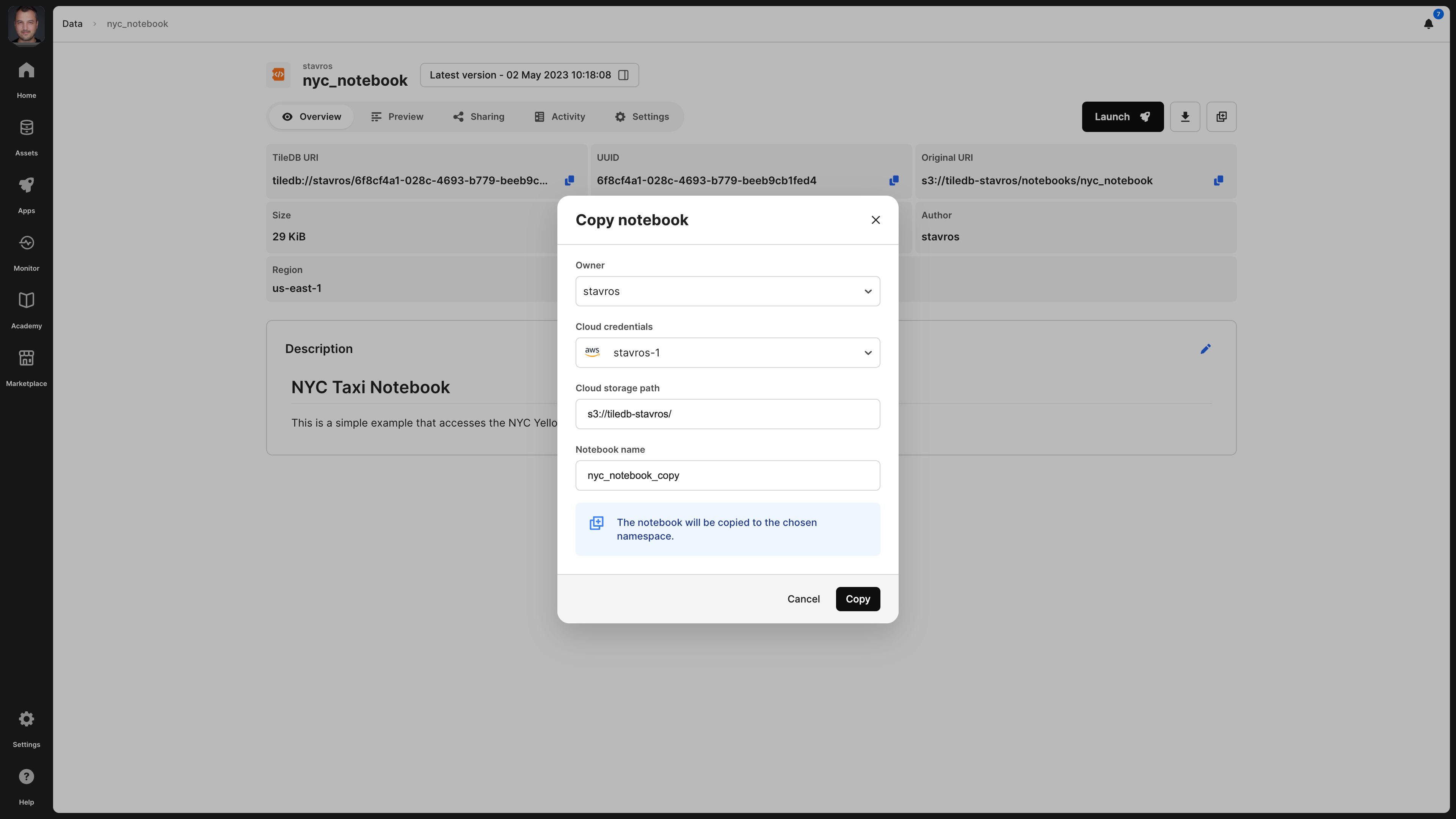
Copy notebook
TileDB allows you to duplicate a notebook by copying it in another physical storage location and with a different name. Select the Copy notebook button that is next to the Download button. In the emerging window, you can change the owner (e.g., to an organization of which you are a member), add a new physical storage path, and change the name.
Launch notebook
TileDB offers a powerful compute infrastructure, in which you can securly launch your notebook by selecting the Launch button. Visit the Analyze section for more details on launching notebooks in TileDB.
Rename notebook
You can rename a notebook from the Settings tab. This action does not alter or copy the contents of the notebook; it just registers the asset in the catalog under a different name.
You can programmatically rename a notebook as follows:
tiledb.cloud.asset.update_info(
"`tiledb://<account>/<previous_name>`",
name="<new_name>",
access_credentials_name="<acn>", # Optional - The cloud credentials that access the notebook (should already exist in your account settings)
)Take caution when renaming notebooks, as any URIs including the previous notebook name will no longer work.
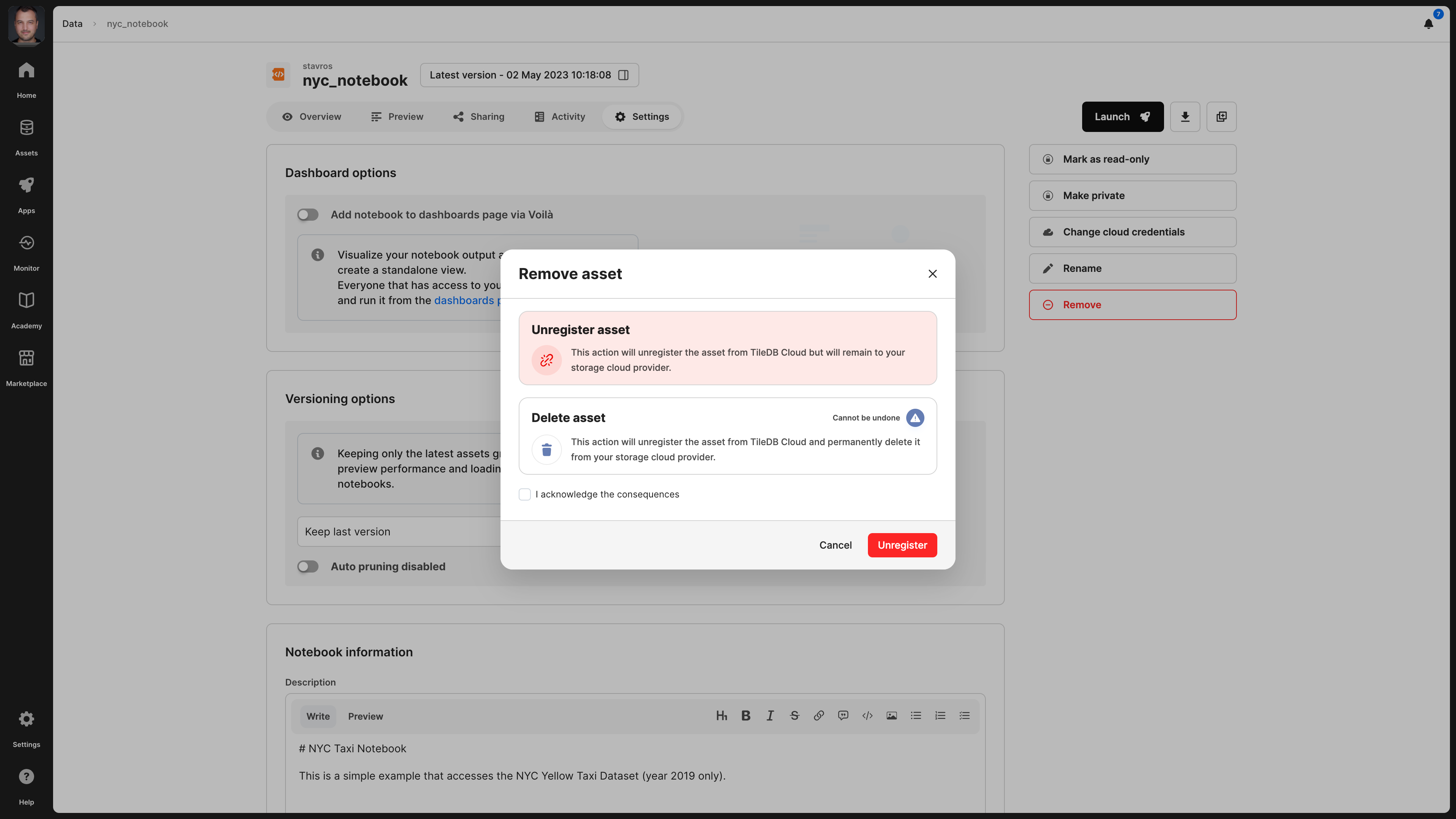
Delete notebook
When deleting a notebook, you have two options:
- Unregister: This operation removes the notebook from the TileDB catalog, but it does not physically remove it from the object store. Since the notebook will persist on storage, you can register it again in the TileDB catalog in the future.
- Delete: This operation both unregisters and physically removes the notebook from storage. Note that this operation cannot be undone.
You can delete the notebook from the Settings tab, which will prompt you to choose among the two operations above.

You can also programmatically delete or unregister a notebook as follows:
# Unregister a notebook
tiledb.cloud.asset.deregister(uri="tiledb://<account>/<notebook_name>")
# Delete a notebook
tiledb.cloud.asset.delete(uri="tiledb://<account>/<notebook_name>")