Writes
TileDB is architected to efficiently support:
- Object stores, where all files/objects are immutable and, therefore, cannot be updated in place.
- Parallel batch writes, that is, writing collections of cells with multiple processes or threads.
Each write operation creates one or more dense or sparse timestamped fragments (visit the Key Concepts: Fragments and Key Concepts: Time traveling sections for more details on fragments and time traveling). You can process multiple write operations to populate your array, or overwrite existing cells in your array. TileDB handles each write separately and without any locking (for more information, visit Concurrency: Writes). Each fragment is immutable (that is, write operations always create new fragments, without altering any older fragment).
Dense writes
A dense write is applicable to dense arrays and creates one or more dense fragments. In a dense write, the user provides:
- The subarray to write into (it must be single-range).
- The attribute values of the cells that are being written.
- (In some APIs only) The cell order within the subarray (which must be common across all attributes), so that TileDB knows which values correspond to which cells in the array domain. The cell order may be row-major, column-major, or global.
The example below illustrates writing into a subarray of an array with a single attribute. The figure depicts the order of the attribute values in the user buffers for the case of row- and column-major cell order. TileDB knows how to appropriately re-organize the user-provided values so that they obey the global cell order before storing them to disk. Moreover, note that TileDB always writes integral space tiles to disk. Therefore, it will inject special fill values (depicted in gray below) into the user data to create full data tiles for each space tile.
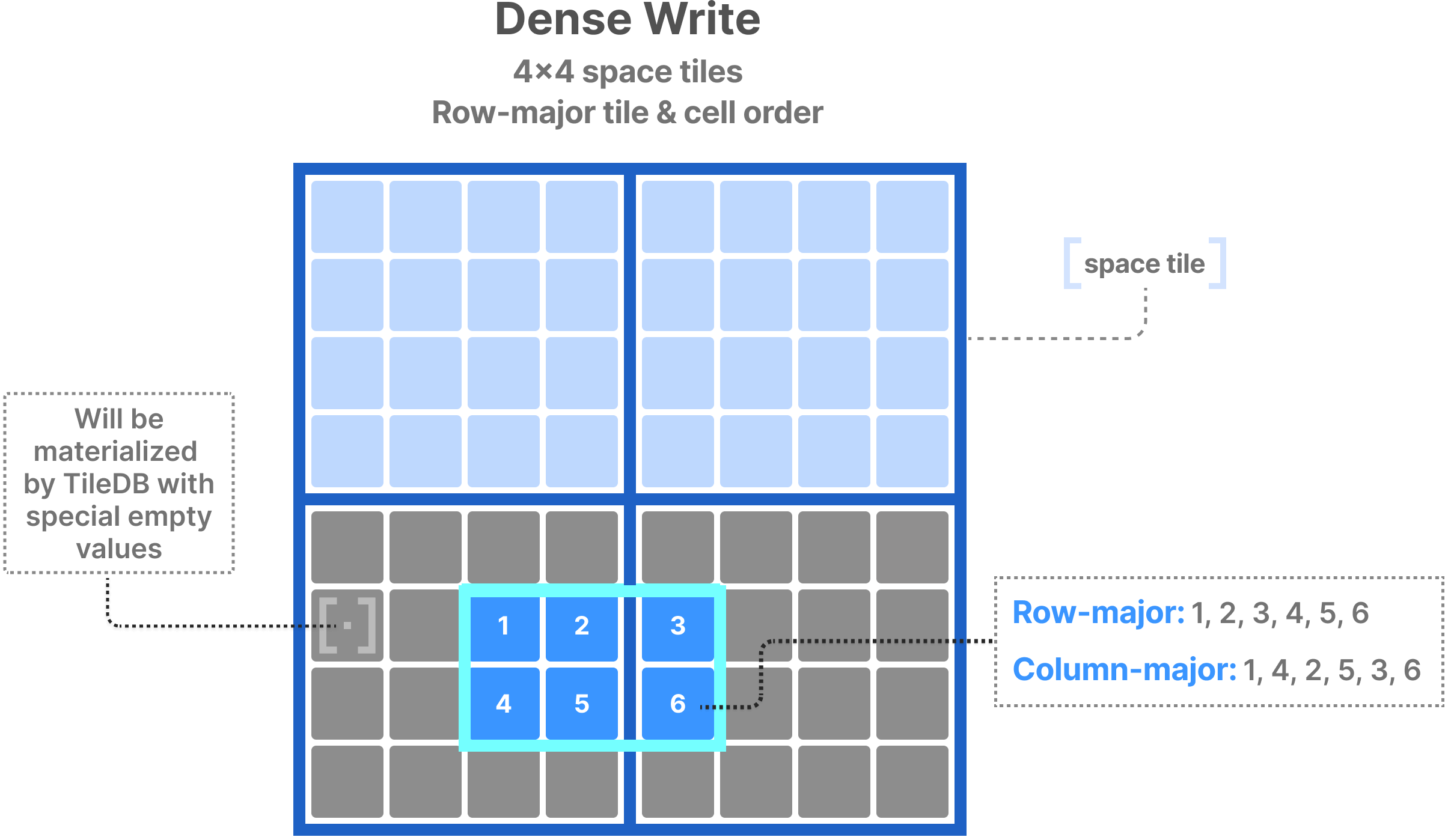
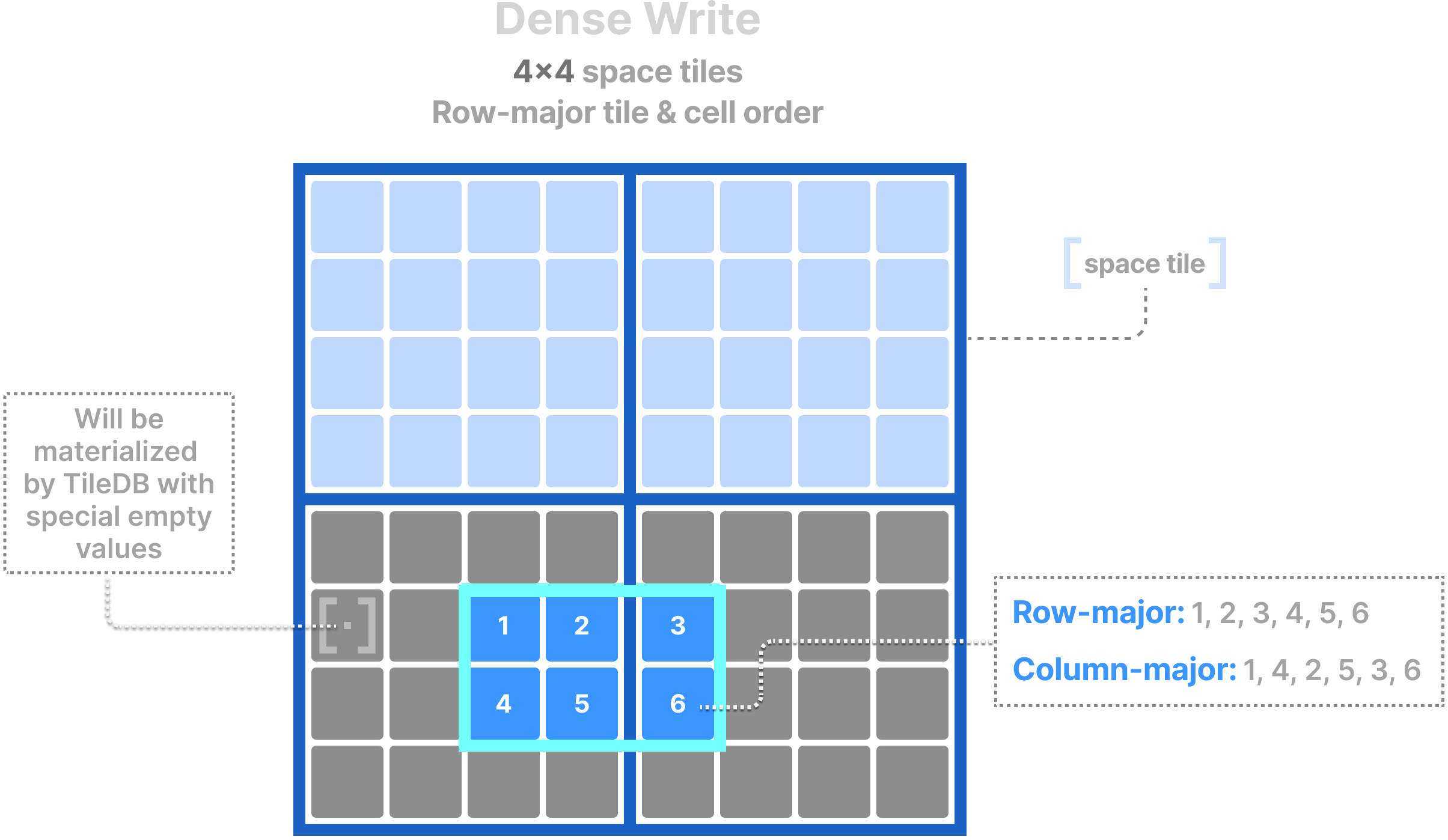
Writing in the array global order needs a little bit more care. The subarray must be specified such that it coincides with space tile boundaries, even if the user wishes to write in a smaller area within that subarray. The user is responsible for manually adding any necessary empty cell values in their buffers. This is illustrated in the figure below, where the user wishes to write in the blue cells, but has to expand the subarray to coincide with the two space tiles and provide the empty values for the gray cells as well. The user must provide all cell values in the global order, following the tile order of the space tiles and the cell order within each space tile.

Writing in global order requires knowledge of the space tiling and cell/tile order, and is rather cumbersome to use. However, this write mode leads to the best performance, because TileDB does not need to internally re-organize the cells along the global order. It is recommended for use cases where the data arrive already grouped according to the space tiling and global order (e.g., in geospatial applications).
Sparse writes
Sparse writes are applicable to sparse arrays and create one or more sparse fragments. The user must provide:
- The attribute values to be written.
- The coordinates of the cells to be written.
- (In some APIs) The cell layout of the attribute and coordinate values to be written (must be the same across attributes and dimensions). The cell layout may be unordered or global.
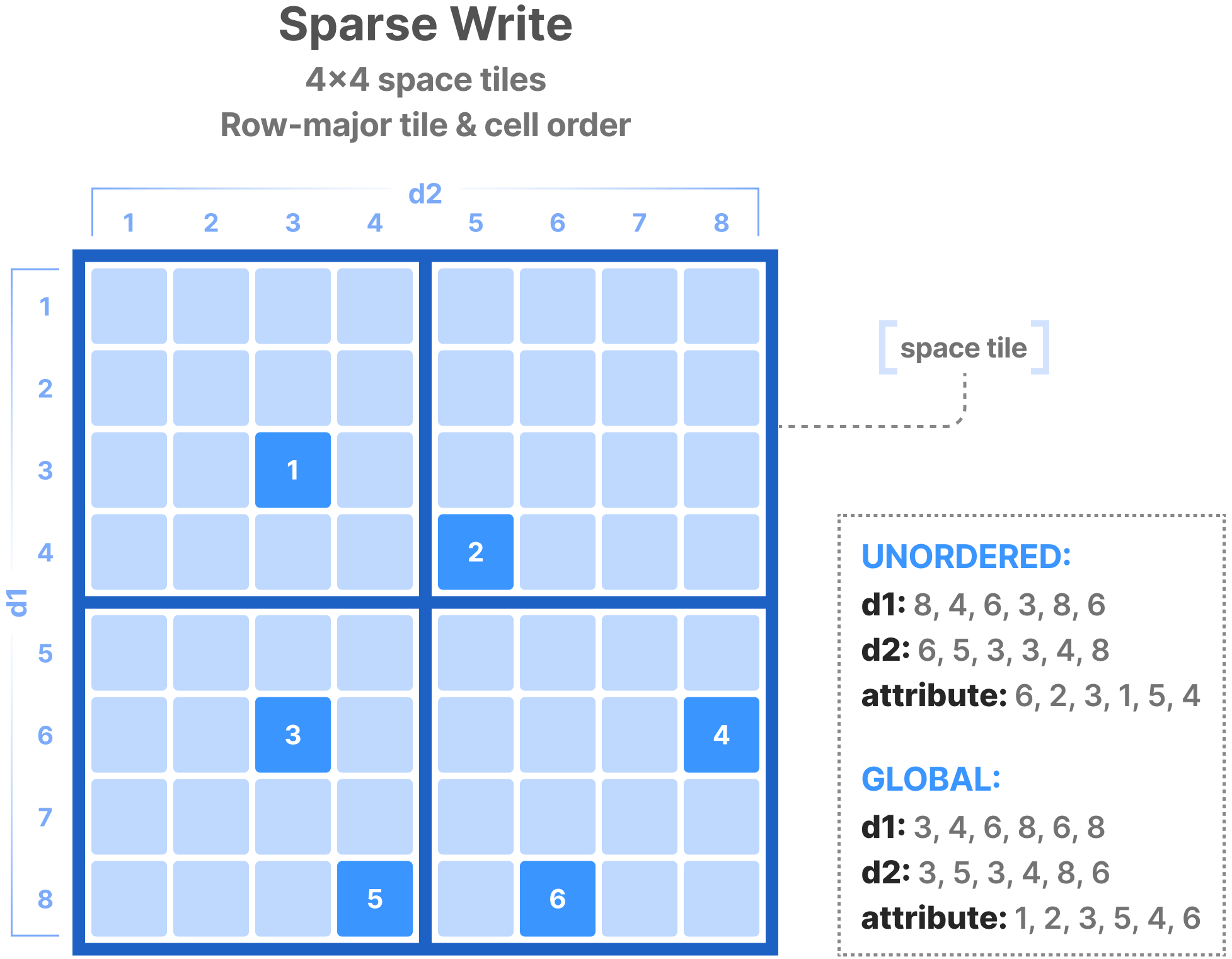
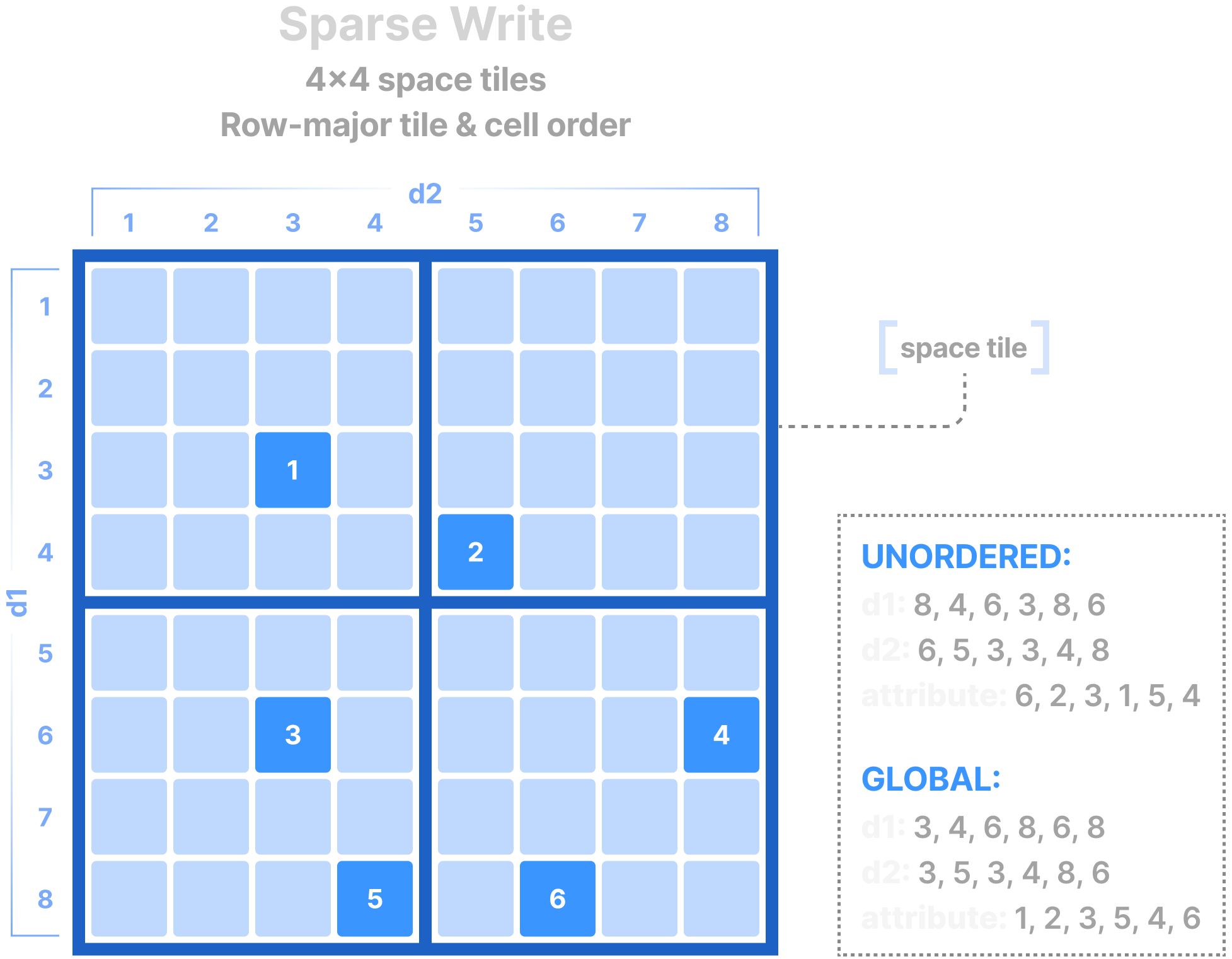
Note that sparse writes do not need to be constrained in a subarray, since they contain the explicit coordinates of the cells to write into. The figure below shows a sparse write example with the two cell orders. The unordered layout is the easiest and most typical. TileDB knows how to appropriately re-organize the cells along the global order internally before writing the values to disk. The global layout is once again more efficient but also more cumbersome, since the user must know the space tiling and the tile/cell order of the array, and manually sort the values before providing them to TileDB.
Commits
TileDB supports a multiple writer, multiple reader model, making sure that ongoing writes do not interfere with other concurrent writes and reads. This is achieved with the concept of commits. Visit the Key Concepts: Commits section for more details on commits, and the Key Concepts: Reads section on how TileDB reads utilize the commits.
Consolidation
Many immutable writes may lead to degradation of read performance, due to the numerous fragments they create. To mitigate this, TileDB supports advanced consolidation techniques that help compact multiple fragments into a single one, potentially significantly boosting read performance. Visit the Key Concepts: Consolidation section for more details on consolidation.