Array Data Model
This page describes the basic array model of TileDB. There is an important distinction between a dense and a sparse array. A dense array can have any number of dimensions. Each dimension must have a domain with integer values, and all dimensions have the same data type. An array element is defined by a unique set of dimension coordinates and it is called a cell. In a dense array, all cells must store a value. A logical cell can store more than one value of potentially different types (which can be integers, floats, strings, etc.). An attribute defines a collection of values that have the same type across all cells. A dense array may be associated with a set of arbitrary key-value pairs, called array metadata.
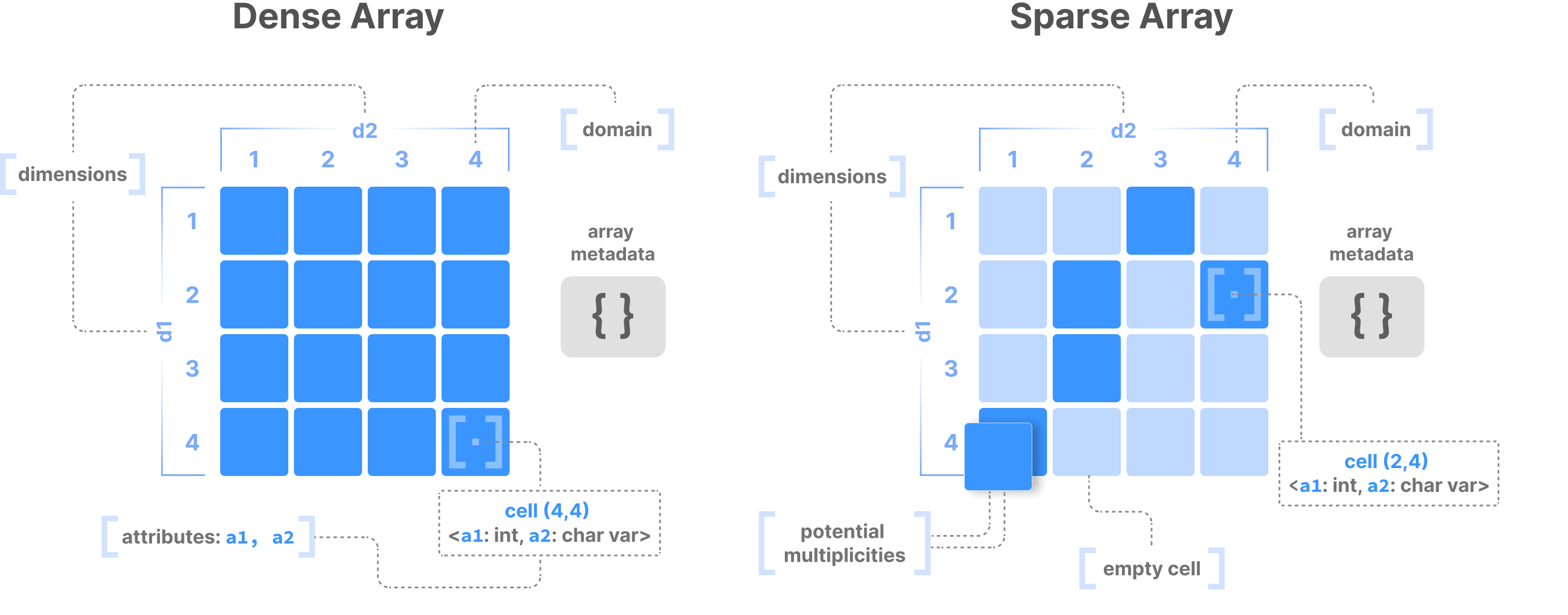
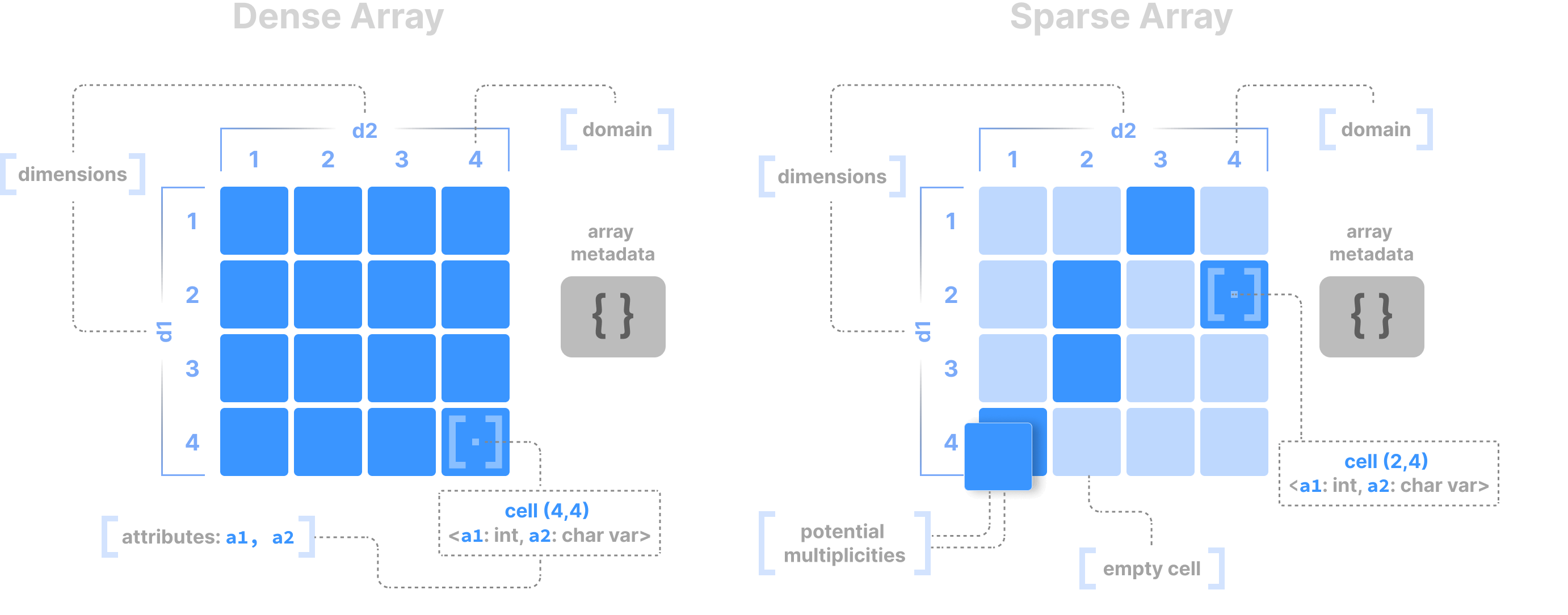
A sparse array is very similar to a dense array, but it has three important differences:
Cells in a sparse array can be empty.
The dimensions can have heterogeneous types, including floats and strings (i.e., the domain can be “infinite”).
Cell multiplicities (i.e., cells with the same dimension coordinates) are allowed.
The decision on whether to model your data with a dense or sparse array depends on the application, and it can greatly affect performance. Also, extra care should be taken when choosing to model a data field as a dimension or an attribute. These decisions are covered in detail in other sections of the Academy, but for now, you should know this:
Array systems are optimized for rapidly performing range conditions on dimension coordinates.
Arrays can also support efficient conditions on attributes, but by design, the most optimized selection performance will come from querying on dimensions, and the reason will become clear soon.
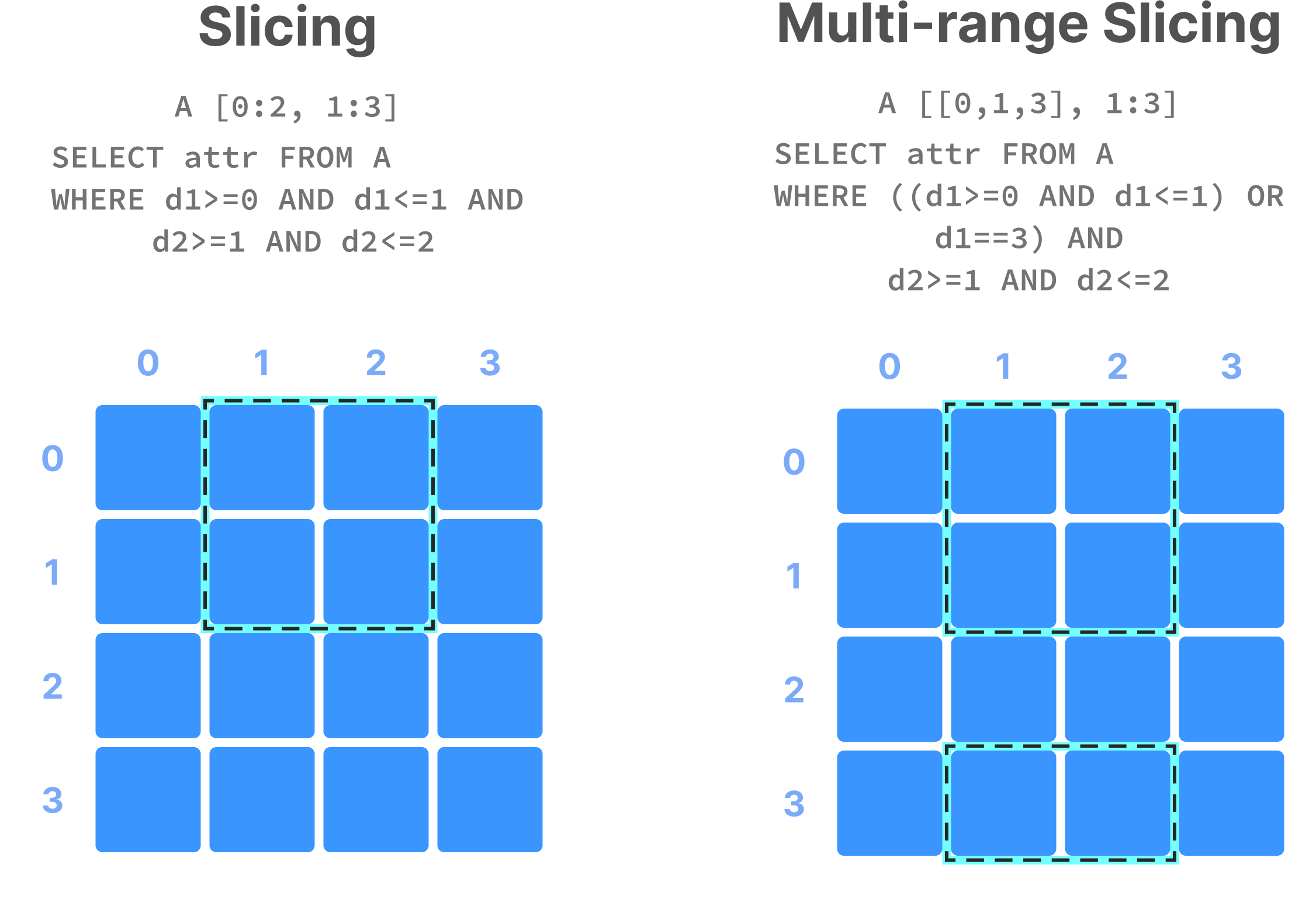
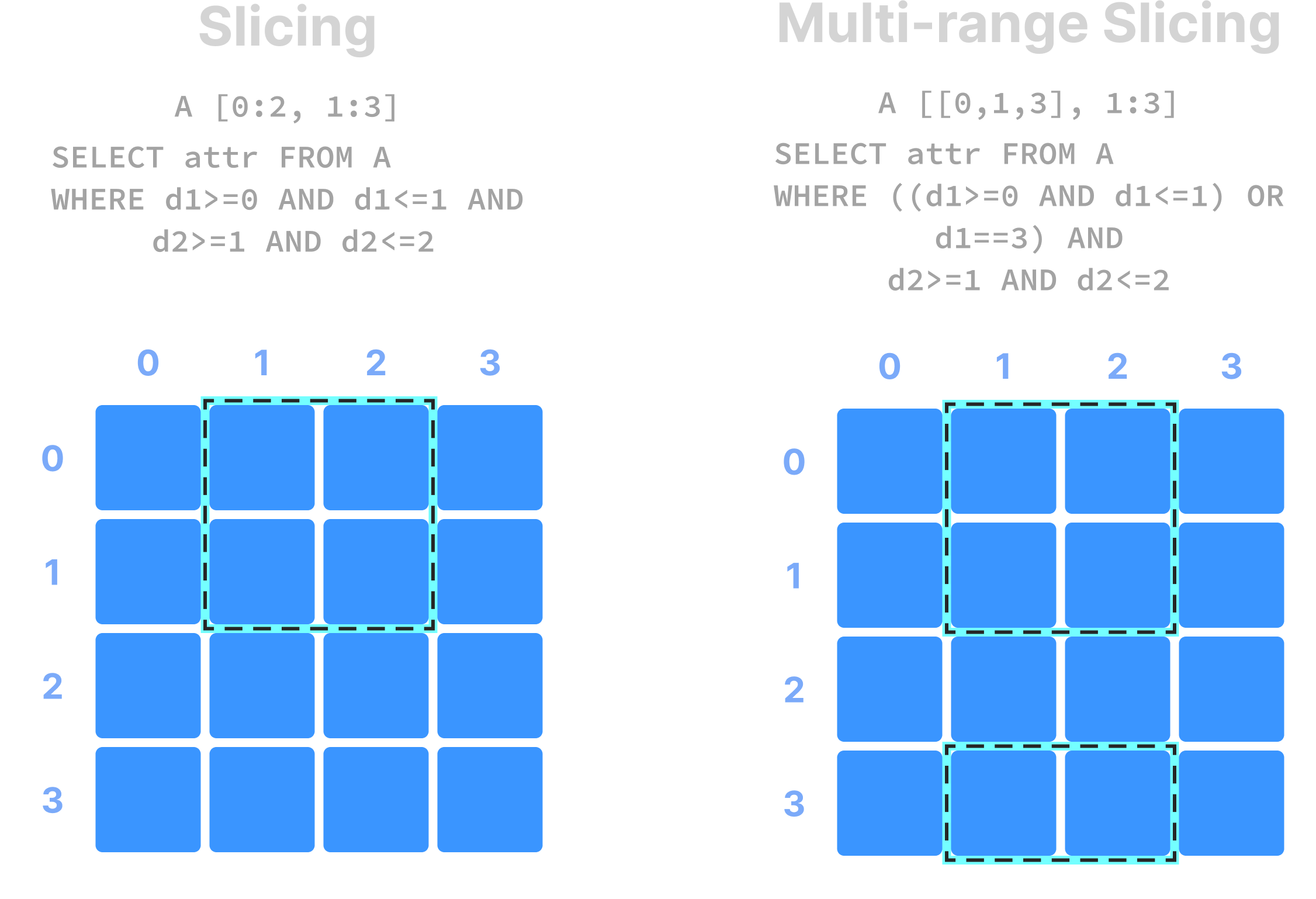
Range conditions on dimensions are often called slicing and the results constitute a “slice” or “subarray”. Some examples are shown in the figure below. In NumPy notation, A[0:2, 1:3] is a slice that consists of the values of cells with coordinates 0 and 1 on the first dimension, and coordinates 1, and 2 on the second dimension (assuming a single attribute). Alternatively, this can be written in SQL as SELECT attr FROM A WHERE d1>=0 AND d1<=1 AND d2>=1 AND d2<=2 , where attr is an attribute and d1 and d2 the two dimensions of array A. Note also that slicing may contain more than one range per dimension (a multi-range slice).
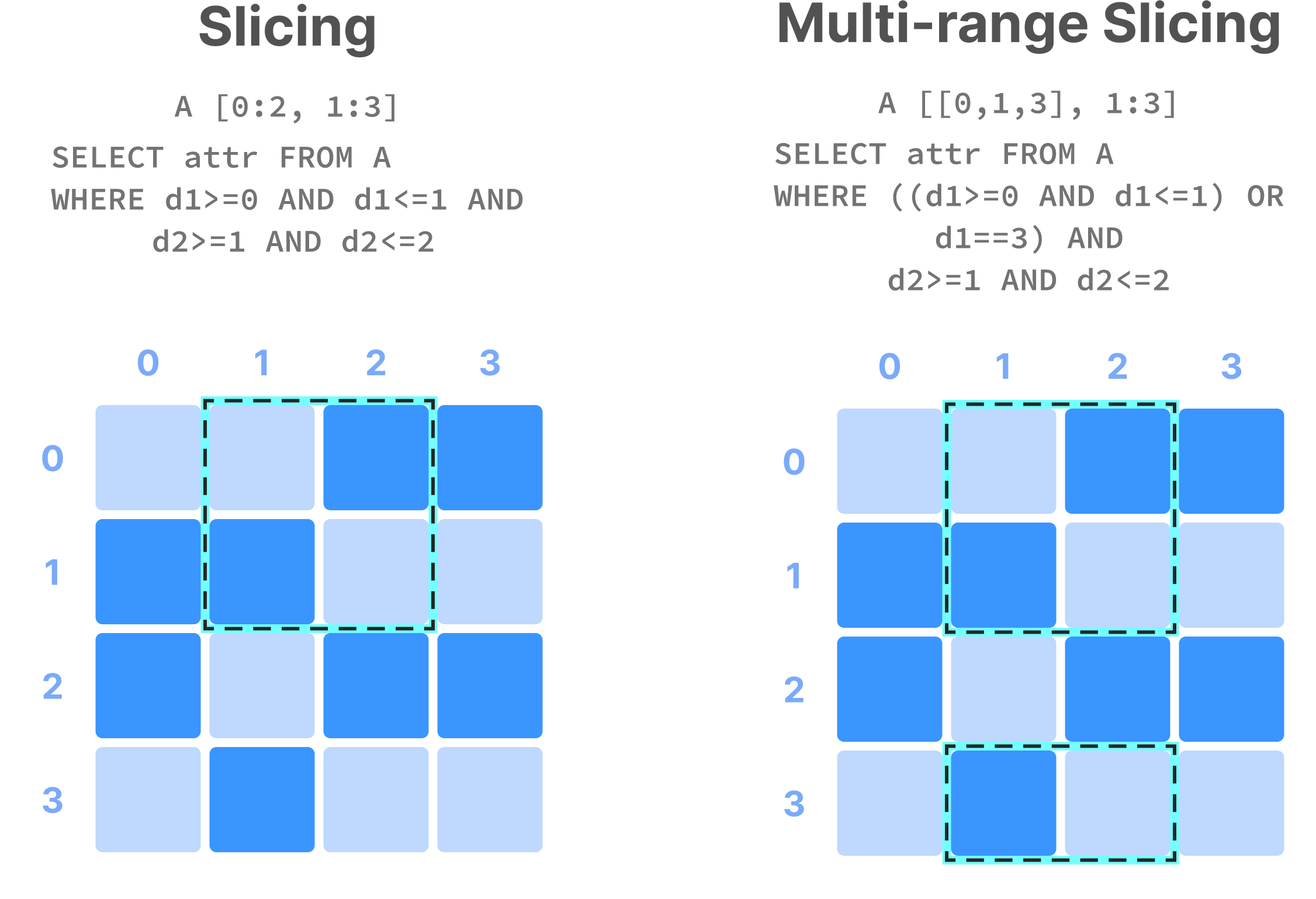
A great advantage of the array model is the fact that it can shapeshift and adapt to any problem setting with even the most complex data. In the Structure section, you can find a broad set of use cases, which explain in detail how arrays are adapted to efficiently capture the intricacies of their data.
Despite the simplicity of the array model, in order to implement it efficiently and make it adaptive to any challenging application scenario, the TileDB array engine implementation is based on a solid foundation described in the Key Concepts section. The architectural decisions stemming from these concepts led to a powerful, open data specification covered in detail in the Storage Format Spec section.
Keep on diving deeper into the internal mechanics of TileDB arrays, or start getting hands on experience with the Array Tutorials.