Arrays: Time Traveling
It is strongly recommended to read the following sections before you learn about time traveling.
Writing to TileDB arrays produces a number of timestamped fragments, deleting from TileDB produces timestamped delete commits, and evolving the array schema produces timestamped schema files. These allow TileDB to support reading an array at an arbitrary point in time, by providing a timestamp range upon opening the array for reading. This is called time traveling, and applies to dense and sparse arrays, array and group metadata, as well as schema evolution. Time traveling can be affected by consolidation and vacuuming. The following subsections describe time traveling for various scenarios.
Time traveling in dense arrays
The figure below shows an example of a dense array with 3 fragments, along with the results of a subarray depending on the timestamp with which the array gets opened.
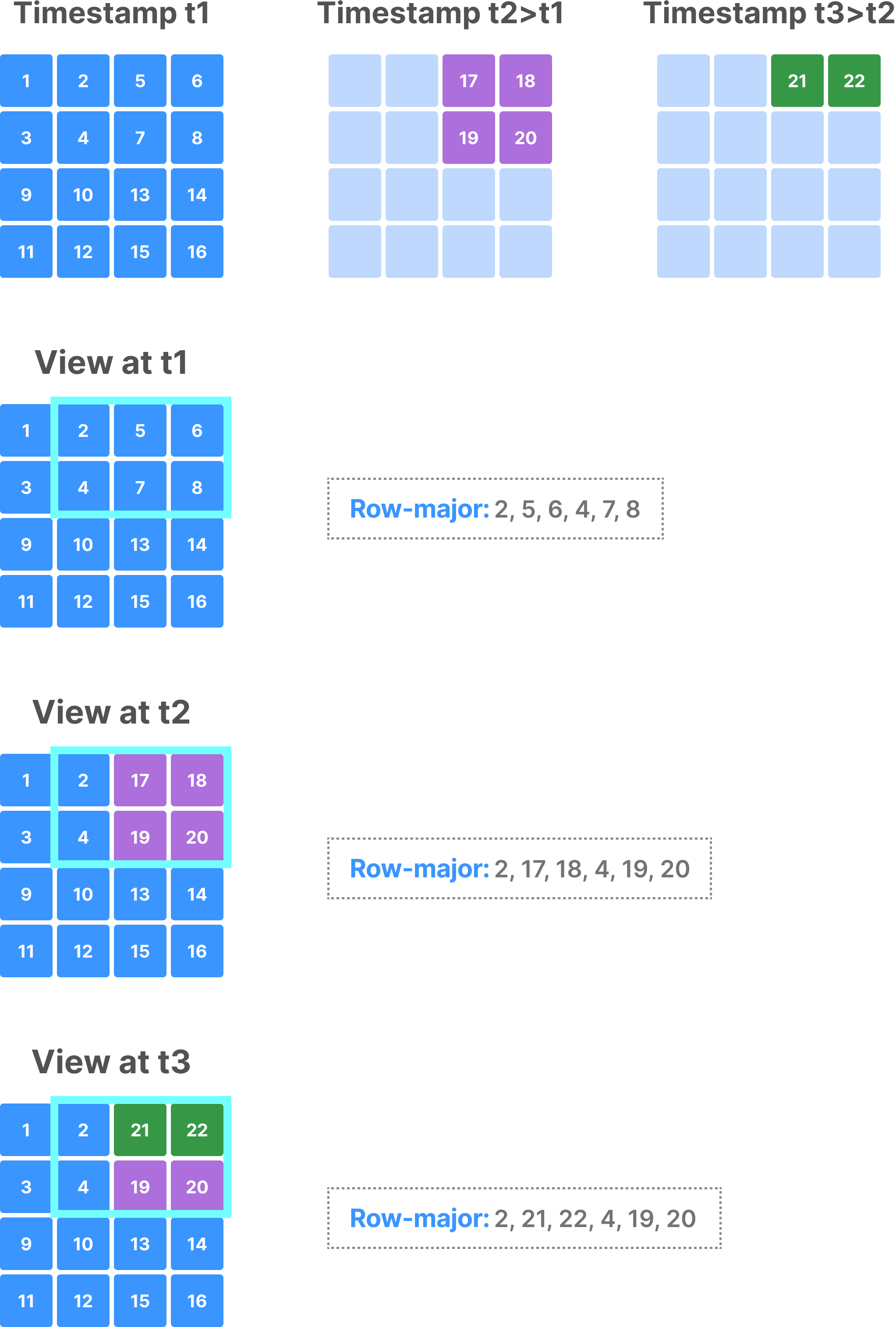
Time traveling in dense arrays works as follows:
- If no consolidated fragments exist (that is, the array has only fragments and commits that carry a unary timestamp range in their name), given a time range upon opening the array, TileDB will consider only the fragments and commits whose timestamps fall inside the time range.
- If one or more consolidated fragments exist (in which case the time range in their name isn’t unary), two distinct cases exist:
- If the original fragments that took part in consolidation haven’t been vacuumed yet, TileDB will consider the finest timestamp granularity to choose the fragments in the read query, which leads to the highest fidelity of results when time traveling. For example, if the array has three fragments with timestamps
1,2, and3, which were consolidated into a fragment with time range1-3, then four fragments will exist given that no vacuuming took place. If the time range in the query is1-2, TileDB will consider the original fragments with timestamps1and2, instead of the consolidated fragment1-3. - If the original fragments are vacuumed, TileDB will consider a consolidated fragment only if its time range falls completely within the query time range. In the above example, if you run vacuuming, then fragments with timestamps
1,2, and3will be deleted, and only1-3will remain. If the time range in the query is1-2, TileDB will skip completely the consolidated fragment with timestamp range1-3and no results will be produced (i.e., the fidelity is lower in this case).
- If the original fragments that took part in consolidation haven’t been vacuumed yet, TileDB will consider the finest timestamp granularity to choose the fragments in the read query, which leads to the highest fidelity of results when time traveling. For example, if the array has three fragments with timestamps
Time traveling in sparse arrays
The figure below shows an example of a sparse array with 3 fragments, along with the results of a subarray depending on the timestamp with which the array gets opened.
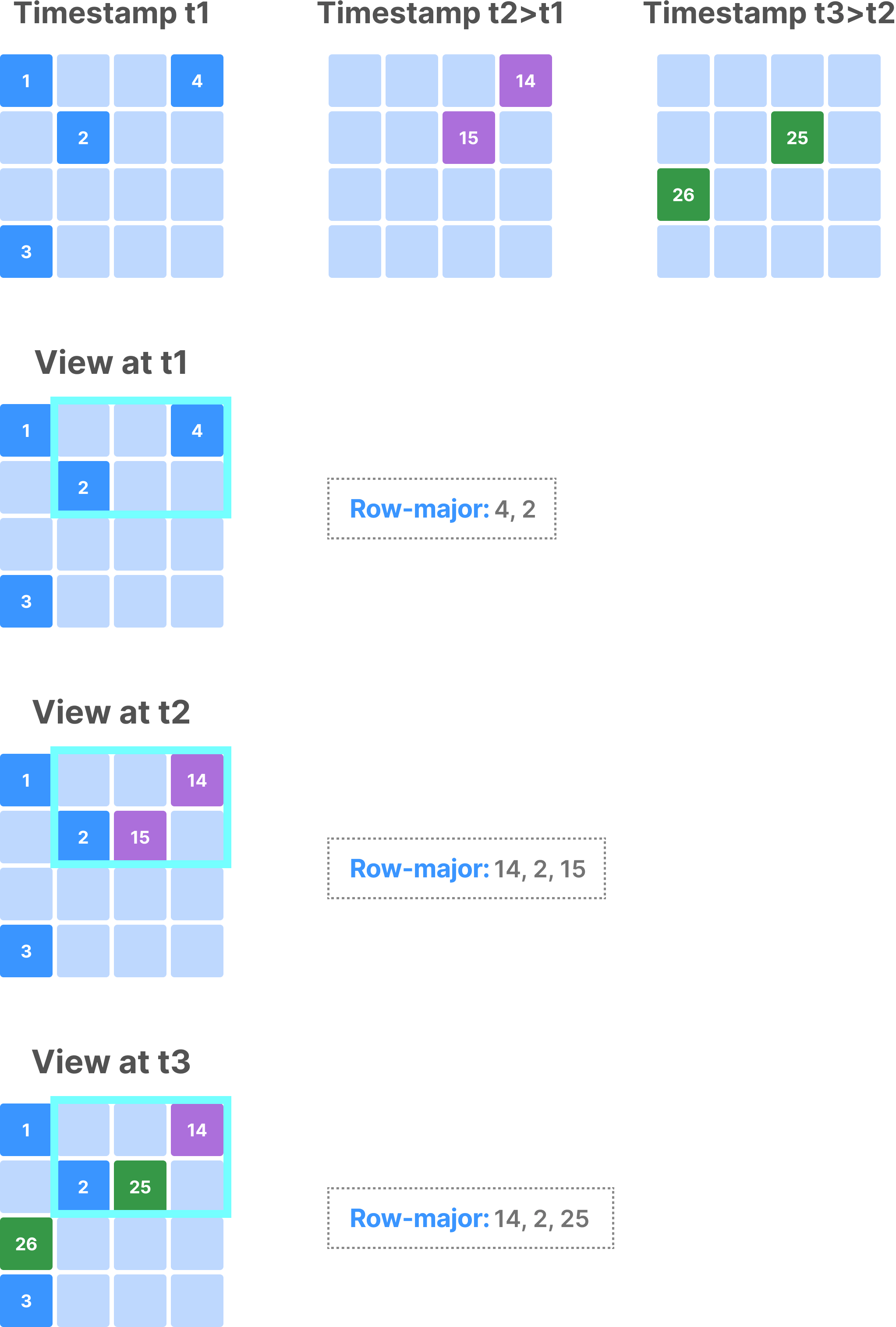
Time traveling in sparse arrays works as follows:
- If no consolidated fragments exist (that is, the array has only fragments and commits that carry a unary timestamp range in their name), given a time range upon opening the array, TileDB will consider only the fragments and commits whose timestamps fall inside the time range. The same holds true for delete commits as well.
- If one or more consolidated fragments exist (in which case the time range in their name isn’t unary), then sparse arrays handle them as follows: A consolidated fragment in sparse arrays include two extra system attributes; the first records the creation time of a non-empty cell, and the second the time it was potentially deleted. Given a time range in the query, TileDB considers all fragments whose timestamp range overlaps even partially with it. Then it performs further filtering as it processes the read queries by using the extra two timestamp attributes, in order to identify which non-empty cells fall within the time range of the query.
Observe that sparse arrays offer higher fidelity than dense arrays when traveling and in the presence of consolidation and vacuuming.
Time traveling in array and group metadata
The array and group metadata files are all timestamped and, hence, TileDB can quickly identify which metadata to load upon reading. The metadata file consolidation works like fragment consolidation. That is, if the array has consolidated fragment metadata but you haven’t run vacuuming yet, TileDB loads the higher fidelity data. Otherwise, TileDB loads only the consolidated metadata files. In the latter case, fidelity might be lower, because TileDB purges any deleted array and group metadata upon consolidation and, thus, you won’t be able to time travel in case you vacuumed the original metadata files that have the deletions.
Time traveling in schema evolution
Since all array schemas generated by schema evolution are timestamped, TileDB can easily identify which array schema is the latest within the provided time range in the read query, and uses it to load the appropriate array information to process the query.