This quickstart gives you a rapid introduction to TileDB-ML and its capabilities. It’s split into two main categories:
Models in TileDB Data in TileDB
This tutorial will teach you how to:
Store and load an ML model into TileDB.Register a TileDB-ML model in TileDB Cloud.Store and load a basic dataset into TileDB.Run sample queries on this dataset.Register a dataset in TileDB Cloud.Run model training on a dataset in TileDB.
Installation
You have two options to install TileDB-ML . You can either install TileDB-ML via pip —the preferred mechanism for installing it—or from source.
gh repo clone TileDB-Inc/TileDB-MLcd TileDB-MLpip install .
Installation options
Given that TileDB-ML integrates with many ML frameworks, you have the following options:
Install all frameworks.
Limit TileDB-ML’s installation to your preferred framework, without the need to install extra dependencies.
Pip
pip install tiledb-ml[ pytorch ] # or zsh pip install tiledb-ml\[ pytorch\]
pip install tiledb-ml[ tensorflow ] # or zsh pip install tiledb-ml\[ tensorflow\]
Complete installation
To install TileDB-ML with all its dependencies and all options enabled, run the following:
pip install tiledb-ml[ full ]
pip install tiledb-ml\[full\]
Basic ML example
This quickstart guide will show you how to ingest the MNIST dataset, train a ML model and use it for inference on this dataset.
The MNIST dataset is a widely used benchmark dataset in the field of machine learning. It consists of a collection of 28×28 pixel grayscale images of handwritten digits (0 to 9), along with their corresponding labels showing the digit represented in each image. The dataset is commonly used for training and evaluating machine learning models, particularly for image classification tasks.
Import libraries
Start by importing the libraries used in this tutorial.
import osimport tempfileimport idx2numpyimport matplotlib.pyplot as pltimport numpy as npimport tiledbimport torchimport torch.nn as nnimport torch.optim as optimimport torchvisionfrom tiledb.ml.models.pytorch import PyTorchTileDBModelfrom tiledb.ml.readers.pytorch import PyTorchTileDBDataLoaderfrom tiledb.ml.readers.types import ArrayParams
Download the dataset
def load_mnist_data():= os.path.join(os.path.pardir, "data" )= torchvision.datasets.MNIST(root= data_home, train= False , download= True )= os.path.join(data_home, "MNIST/raw/train-images-idx3-ubyte" )= os.path.join(data_home, "MNIST/raw/train-labels-idx1-ubyte" )= idx2numpy.convert_from_file(img_path)= idx2numpy.convert_from_file(labels_path)return images, labels= load_mnist_data()
Ingest in TileDB
def ingest_in_tiledb(data: np.array, batch_size: int , uri: str ):# Equal number of dimensions with the numpy array. = [= "dim_" + str (dim),= (0 , data.shape[dim] - 1 ),= data.shape[dim] if dim > 0 else batch_size,= np.int32,for dim in range (data.ndim)# TileDB schema = tiledb.ArraySchema(= tiledb.Domain(* dims),= False ,= [tiledb.Attr(name= "features" , dtype= data.dtype)],# Create array # Ingest with tiledb.open (uri, "w" ) as tiledb_array:= {"features" : data}
= tempfile.mkdtemp("mnist_array" )# Ingest images = os.path.join(dataset, "training_images" )= images, batch_size= 64 , uri= training_images)# Ingest labels = os.path.join(dataset, "training_labels" )= labels, batch_size= 64 , uri= training_labels)
TileDB dataset
= tiledb.open (training_images)= tiledb.open (training_labels)
Arrays schemas
Domain
Name
Domain
Tile
Data Type
Is Var-length
Filters
dim_0
(0, 59999)
64
int32
False
-
dim_1
(0, 27)
28
int32
False
-
dim_2
(0, 27)
28
int32
False
-
Attributes
Name
Data Type
Is Var-Len
Is Nullable
Filters
features
uint8
False
False
-
Cell Order
row-major
Tile Order
row-major
Sparse
False
Domain
Name
Domain
Tile
Data Type
Is Var-length
Filters
dim_0
(0, 59999)
64
int32
False
-
Attributes
Name
Data Type
Is Var-Len
Is Nullable
Filters
features
uint8
False
False
-
Cell Order
row-major
Tile Order
row-major
Sparse
False
Import libraries
Start by importing the libraries used in this tutorial.
import osimport tempfileimport matplotlib.pyplot as pltimport numpy as npimport tensorflow as tfimport tiledbfrom tiledb.ml.models.tensorflow_keras import TensorflowKerasTileDBModelfrom tiledb.ml.readers.tensorflow import ArrayParams, TensorflowTileDBDataset
Download the dataset
= tf.keras.datasets.mnist.load_data()= images / 255.0
Ingest in TileDB
def ingest_in_tiledb(data: np.array, batch_size: int , uri: str ):# Equal number of dimensions with the numpy array. = [= "dim_" + str (dim),= (0 , data.shape[dim] - 1 ),= data.shape[dim] if dim > 0 else batch_size,= np.int32,for dim in range (data.ndim)# TileDB schema = tiledb.ArraySchema(= tiledb.Domain(* dims),= False ,= [tiledb.Attr(name= "features" , dtype= data.dtype)],# Create array # Ingest with tiledb.open (uri, "w" ) as tiledb_array:= {"features" : data}
= tempfile.mkdtemp("mnist_array" )# Ingest images = os.path.join(dataset, "training_images" )= images, batch_size= 64 , uri= training_images)# Ingest labels = os.path.join(dataset, "training_labels" )= labels, batch_size= 64 , uri= training_labels)
TileDB dataset
= tiledb.open (training_images)= tiledb.open (training_labels)
Arrays schemas
Domain
Name
Domain
Tile
Data Type
Is Var-length
Filters
dim_0
(0, 59999)
64
int32
False
-
dim_1
(0, 27)
28
int32
False
-
dim_2
(0, 27)
28
int32
False
-
Attributes
Name
Data Type
Is Var-Len
Is Nullable
Filters
features
float64
False
False
-
Cell Order
row-major
Tile Order
row-major
Sparse
False
Domain
Name
Domain
Tile
Data Type
Is Var-length
Filters
dim_0
(0, 59999)
64
int32
False
-
Attributes
Name
Data Type
Is Var-Len
Is Nullable
Filters
features
uint8
False
False
-
Cell Order
row-major
Tile Order
row-major
Sparse
False
Dataloaders
TileDB offers an API with native dataloaders for all the ML frameworks with which TileDB integrates. After you store your data, you can use the API to create dataloaders in each framework that will be later used as input to the model’s training stage. The API takes two TileDB arrays as inputs: x, which refers to the sample data; and y, which holds the label data corresponding to each sample in x. The dataloader collates these two arrays into a single data object that can later be used as input for training a model.
with tiledb.open (training_images) as x, tiledb.open (training_labels) as y:= PyTorchTileDBDataLoader(= 128 ,= 0 ,= 256 ,= next (iter (train_loader))print (f"Input Shape: { batch_imgs. shape} " )print (f"Label Shape: { batch_labels. shape} " )
Input Shape: torch.Size([128, 28, 28])
Label Shape: torch.Size([128])
with tiledb.open (training_images) as x, tiledb.open (training_labels) as y:= TensorflowTileDBDataset(= x, fields= ["features" ]),= y, fields= ["features" ]),= tiledb_dataset.batch(128 )= next (batched_dataset.as_numpy_iterator())print (f"Input Shape: { batch_imgs. shape} " )print (f"Label Shape: { batch_labels. shape} " )
Input Shape: (128, 28, 28)
Label Shape: (128,)
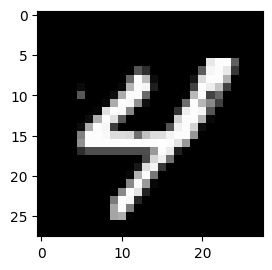
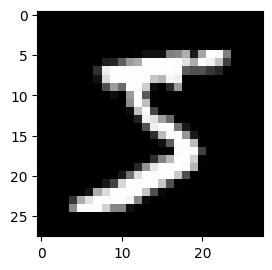
Visualization
Render the first image from the batched data fetched by TileDB-ML loaders:
= batch_imgs[0 ]1 , 2 , 1 )= "gray" )
= batch_imgs[0 ]1 , 2 , 1 )= "gray" )
Model training
Define the model
class Net(nn.Module):def __init__ (self , shape):super (Net, self ).__init__ ()self .flatten = nn.Flatten()self .linear_relu_stack = nn.Sequential(32 ),32 , 32 ),32 , 10 ),def forward(self , x):= self .flatten(x)= self .linear_relu_stack(x)return logits
Model training
= []= []= nn.CrossEntropyLoss()= optim.SGD(network.parameters(), lr= 0.01 , momentum= 0.5 )def do_random_noise(img, mag= 0.1 ):= np.random.uniform(- 1 , 1 , img.shape) * mag= img + noise= np.clip(img, 0 , 1 )return imgwith tiledb.open (training_images) as x, tiledb.open (training_labels) as y:= PyTorchTileDBDataLoader(= do_random_noise),= 128 ,= 0 ,= 256 ,for epoch in range (1 , 3 ):for batch_idx, (inputs, labels) in enumerate (train_loader):# zero the parameter gradients # forward + backward + optimize = network(inputs.to(torch.float ))= criterion(outputs, labels.to(torch.float ).type (torch.LongTensor))if batch_idx % 100 == 0 :print ("Train Epoch: {} Batch: {} Loss: {:.6f} " .format (
Train Epoch: 1 Batch: 0 Loss: 2.306959
Train Epoch: 1 Batch: 100 Loss: 2.268600
Train Epoch: 1 Batch: 200 Loss: 2.188591
Train Epoch: 1 Batch: 300 Loss: 1.987314
Train Epoch: 1 Batch: 400 Loss: 1.855456
Train Epoch: 2 Batch: 0 Loss: 1.624074
Train Epoch: 2 Batch: 100 Loss: 1.569407
Train Epoch: 2 Batch: 200 Loss: 1.558700
Train Epoch: 2 Batch: 300 Loss: 1.329881
Train Epoch: 2 Batch: 400 Loss: 1.217714
Define the model
= tf.keras.models.Sequential(= (28 , 28 )),128 , activation= "relu" ),0.2 ),10 ),= tf.keras.losses.SparseCategoricalCrossentropy(from_logits= True )compile (optimizer= "adam" , loss= loss_fn, metrics= ["accuracy" ])
Training
with tiledb.open (training_images) as x, tiledb.open (training_labels) as y:= TensorflowTileDBDataset(= x),= y),= 2 if os.cpu_count() > 2 else 0 ,= tiledb_dataset.batch(64 ).shuffle(128 )= 5 )
Epoch 1/5
938/938 [==============================] - 3s 2ms/step - loss: 0.0755 - accuracy: 0.9772
Epoch 2/5
938/938 [==============================] - 3s 2ms/step - loss: 0.0675 - accuracy: 0.9786
Epoch 3/5
938/938 [==============================] - 3s 2ms/step - loss: 0.0590 - accuracy: 0.9806
Epoch 4/5
938/938 [==============================] - 3s 2ms/step - loss: 0.0551 - accuracy: 0.9828
Epoch 5/5
938/938 [==============================] - 3s 2ms/step - loss: 0.0500 - accuracy: 0.9837
Store models
Save the model
= Net(shape= (28 , 28 ))= optim.SGD(network.parameters(), lr= learning_rate, momentum= momentum)= PyTorchTileDBModel(uri= model_uri, model= network, optimizer= optimizer)= {"epochs" : epochs})
Save the model
= TensorflowKerasTileDBModel(uri= uri, model= model)= True )