Launch a Notebook
TileDB provides a managed “notebook” environment for interactive, web-browser based execution and interaction with Python and R code running on TileDB servers within a web-browser frontend environment (built around Jupyter with extensions for use with TileDB datasets).
Server types
Notebooks may run on several different server types depending on the needs of a given analysis. TileDB provides notebook server types ranging from 2 vCPU / 8 GB RAM to 128 vCPU / 1 TB RAM.
Execution images
The TileDB managed notebook environment includes a wide range of commonly used Python and R packages. These environments are built using the completely free, community-driven conda forge package collection and the mamba package manager. Contact us to discuss adding new notebook environment packages, and for customization options.
For more information about the supported images and their dependencies, visit Image Dependencies.
Launch a notebook
To launch a new or existing notebook, select the Apps menu option from the TileDB toolbar.


Then select the Launch an app option:


The following modal will appear:
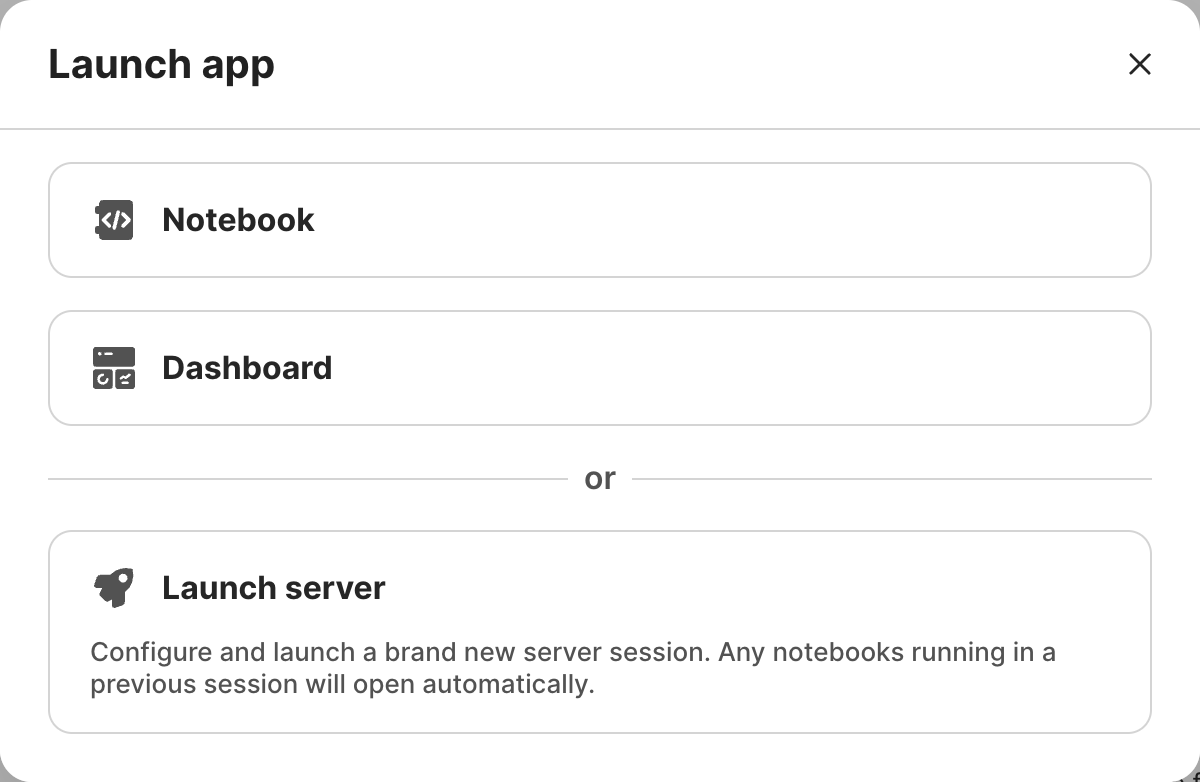
From here, you can launch a new notebook or open an existing notebook.
New notebook
Select Launch server. The following modal will appear:
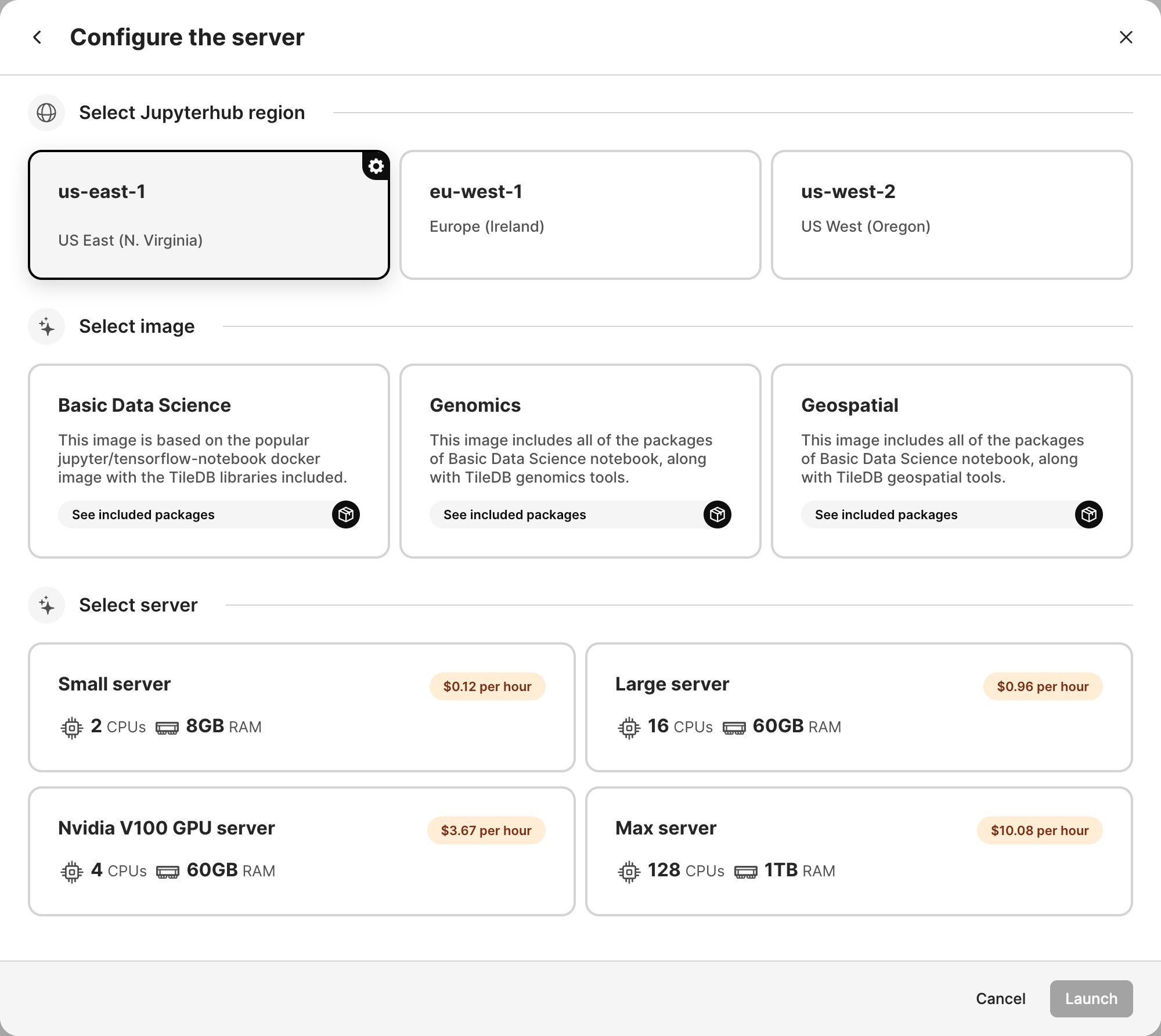
Select the desired Jupyterhub region, image, and server size. Then, select Launch to start a new notebook with the requested settings.


Existing notebook
Select Notebook, then browse for your desired notebook. You can choose notebooks you own, notebooks Shared with you, or public notebooks in the Marketplace. You can also search for a specific notebook and sort notebooks by their Name or their Created date.
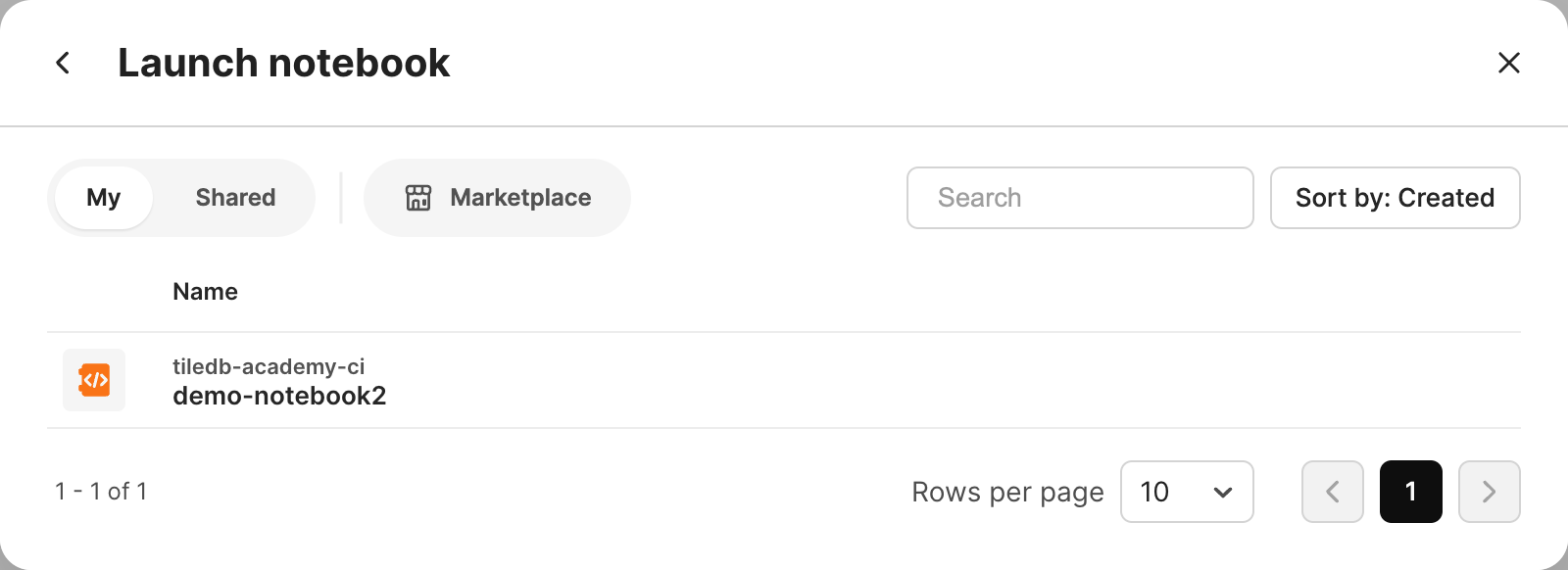
Selecting the notebook will re-launch it with the existing server type and image environment settings, which may be changed in the Notebook settings.