Azure Blob Storage
After configuring TileDB to work with Azure, your TileDB programs will function properly without any API change! Instead of using local file system paths for referencing files (e.g. arrays, groups, VFS files), you must format your URIs to start with azure://. For instance, if you wish to create (and subsequently write and read) an array on Azure, you use a URI of the format azure://<storage-container>/<your-array-name> for the array name.
TileDB does not support storage accounts with hierarchical namespaces.
Setup
Sign into the Azure portal, creating a new account if necessary.
On the Azure portal, select the
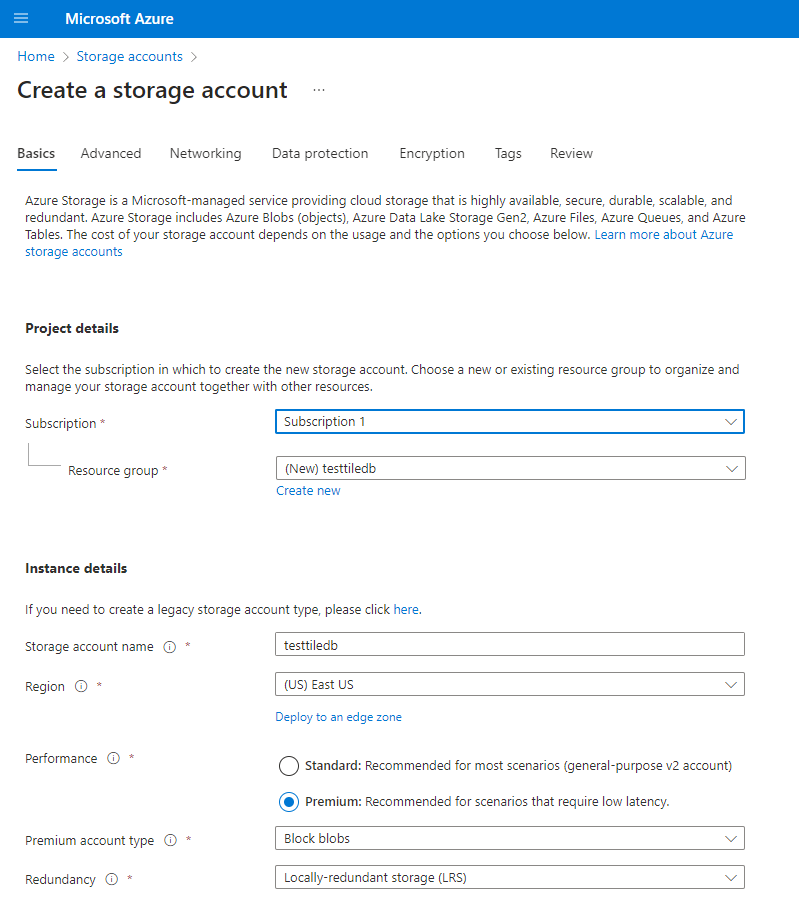
Storage accountsservice.Select the
+Addbutton to navigate to theCreate a storage accountform.Complete the form and create the storage account. You may use a Standard or Premium Block Blob account type.
In your application, set the
vfs.azure.storage_account_nameconfig option or theAZURE_STORAGE_ACCOUNTenvironment variable to the name of your storage account name.
Alternatively, you can directly set the endpoint you use to connect to Azure.
Authenticating to Azure
TileDB supports authenticating to Azure through Microsoft Entra ID, access keys, and shared access signature tokens.
Microsoft Entra ID
Microsoft Entra ID is the recommended way to authenticate to Azure and provides superior security and fine-grained access compared to shared keys. It is enabled by default, and you do not need to specifically configure TileDB to use it. Credentials are obtained automatically from the following sources in order:
- Environment variables.
- The Azure CLI.
- Managed identities for Azure compute resources. Only system-assigned managed identities are currently supported.
- Workload identities for Kubernetes.
When the Azure backend gets initialized, it attempts to obtain credentials by the above sources. If no credentials can be obtained, TileDB will fall back to anonymous authentication.
Manually selecting which authentication method to use is not currently supported.
Microsoft Entra ID will not be used if any of the following conditions apply:
- The
vfs.azure.storage_account_keyorvfs.azure.storage_sas_tokenconfiguration options are specified. - The
AZURE_STORAGE_KEYorAZURE_STORAGE_SAS_TOKENenvironment variables are specified. - A custom endpoint is specified that is not using HTTPS.
TileDB does not currently support the following features when connecting to Azure with Microsoft Entra ID:
- Selecting a specific credentials source without trying to authenticate with the others.
- Authenticating with a service principal specified in config options instead of environment variables.
- Authenticating with a user-assigned managed identity.
Make sure to assign the right roles to the identity to use with TileDB. The general Reader and Contributor roles do not provide access to data inside the storage accounts. You need to assign the Storage Blob Data Reader or the Storage Blob Data Contributor roles in order to read or write data, respectively.
Shared key
Authentication with shared keys is considered insecure. You are recommended to use Microsoft Entra ID.
Once your storage account has been created, navigate to its landing page. From the left menu, select the
Access keysoption. Copy theStorage account nameand one of the auto-generatedKeys.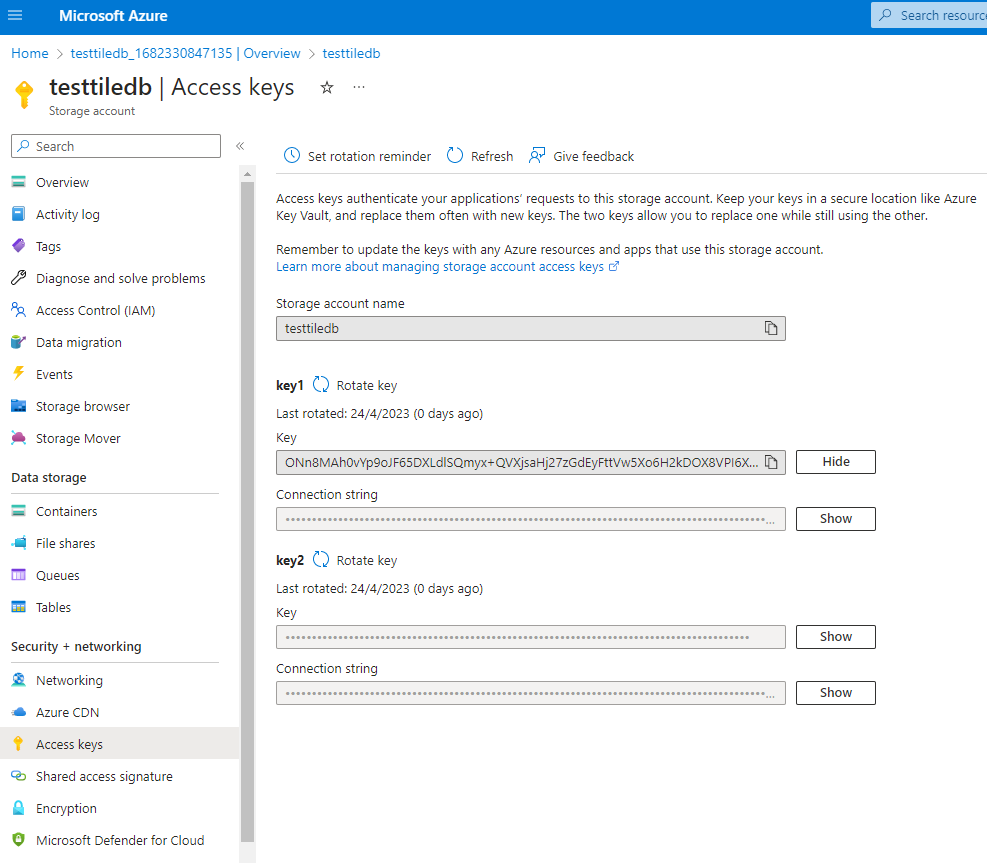
Set the following keys in a configuration object (visit the Configuration section) or environment variable. Use the storage account name and key from the last step.
| Parameter | Environment variable | Default value |
|---|---|---|
"vfs.azure.storage_account_name" |
AZURE_STORAGE_ACCOUNT |
"" |
"vfs.azure.storage_account_key" |
AZURE_STORAGE_KEY |
"" |
Shared access signature
Navigate to the new storage account landing page. From the left menu, select the
Shared Access Signatureoption.Use all checked defaults, and select
Allowed resource types → ContainerSet an appropriate expiration date (note: SAS tokens cannot be revoked)
Select
Generate SAS and connection stringCopy the
SAS Token(second entry) and use in the TileDB config or environment variable: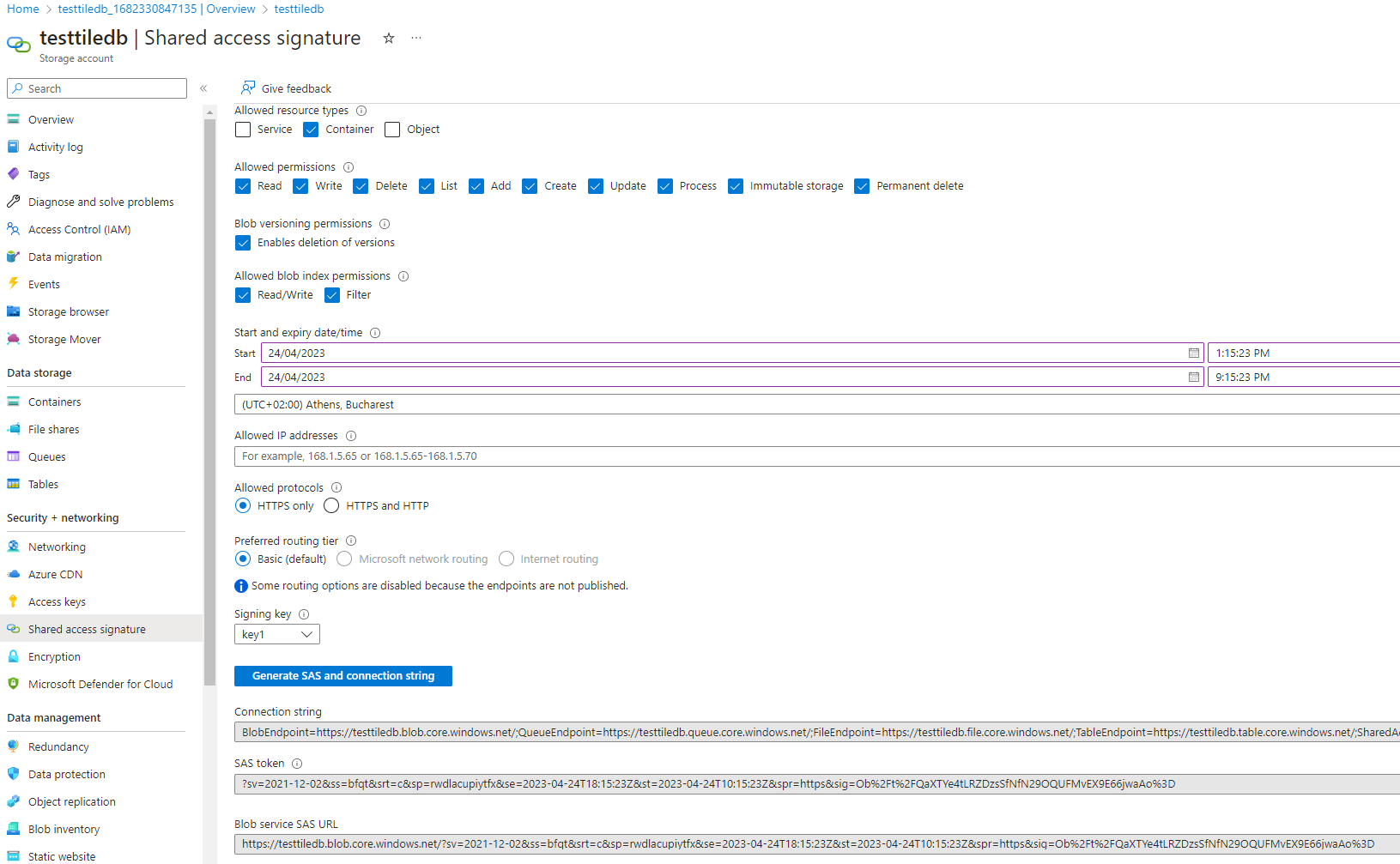
You can configure the following parameters.
| Parameter | Environment variable | Default value |
|---|---|---|
"vfs.azure.storage_sas_token" |
AZURE_STORAGE_SAS_TOKEN |
"" |
Physical organization
So far, you learned that TileDB stores arrays and groups as directories. Azure Blob Storage has no concept of a directory, similar to other object stores. However, Azure uses the / character in the object URIs which allows the same conceptual organization as a directory hierarchy in local storage. At a physical level, TileDB stores all files on Azure that it would create locally as objects. For instance, for array azure://container/path/to/array, TileDB creates array schema object azure://container/path/to/array/schema/__<timestamp>_<timestamp>_<uuid> and other files and objects. Since Blob Storage has no concept of a directory, nothing distinctive persist on Azure for directories (for example, azure://container/path/to/array/meta/ doesn’t exist as an object).
Performance
TileDB writes the various fragment files as append-only objects using the block-list upload API of the Azure SDK for C++. In addition to enabling appends, this API renders the TileDB writes to Azure particularly amenable to optimizations via parallelization. Since TileDB updates arrays only by writing (appending to) new files (i.e., it never updates a file in-place), TileDB does not need to download entire objects, update them, and re-upload them to Azure. This leads to excellent write performance.
TileDB reads utilize the range GET blob request API of the Azure SDK, which retrieves only the requested (contiguous) bytes from a file/object, rather than downloading the entire file from the cloud. This results in extremely fast subarray reads, especially because of the array tiling. Recall that a tile (which groups cell values that are stored contiguously in the file) is the atomic unit of I/O. The range GET API enables reading each tile from Azure in a single request. Finally, TileDB performs all reads in parallel using multiple threads, which is a tunable configuration parameter.
Advanced
By default, the blob endpoint will be set to https://foo.blob.core.windows.net, where foo is the storage account name, as set by the vfs.azure.storage_account_name config option, or the AZURE_STORAGE_ACCOUNT environment variable. You can use the vfs.azure.blob_endpoint config parameter to override the default blob endpoint.
| Parameter | Default value |
|---|---|
"vfs.azure.blob_endpoint" |
"" |
If the custom endpoint contains a SAS token, the vfs.azure.storage_sas_token option must not be specified.