import os
import numpy as np
import tiledb
import tiledb.cloud
import tiledb.vector_search as vs
# Get the bucket from environment variables
s3_bucket = os.environ["S3_BUCKET"]
# Your username
username = tiledb.cloud.user_profile().username
# URIs you will use throughout this tutorial
index_name = "distributed_compute"
index_uri = "tiledb://" + username + "/" + index_name
index_reg_uri = "tiledb://" + username + "/" + s3_bucket + "/" + index_name
source_uri = "tiledb://TileDB-Inc/ann_sift1b_raw_vectors_col_major"
query_vector_uri = "tiledb://TileDB-Inc/bigann_1b_ground_truth_query"
# Clean up
if tiledb.object_type(index_uri) == "group":
tiledb.cloud.asset.delete(index_uri, recursive=True)Use Distributed Compute with Vector Index Data
ai/ml
vector search
tutorials
scalable compute
Demonstration of TileDB-Vector-Search distributed execution capabilities.
How to run this tutorial
We recommend running this tutorial, as well as the other various tutorials in the Tutorials section, inside TileDB Cloud. This will allow you to quickly experiment avoiding all the installation, deployment, and configuration hassles. Sign up for the free tier, spin up a TileDB Cloud notebook with a Python kernel, and follow the tutorial instructions. If you wish to learn how to run tutorials locally on your machine, read the Tutorials: Running Locally tutorial.
This tutorial shows the capabilities of TileDB-Vector-Search distributed execution on TileDB Cloud. It assumes you have already completed the Get Started section.
Setup
Import the necessary libraries, set up the URIs you will use throughout this tutorial, and clean up any previously created data.
Distributed ingestion
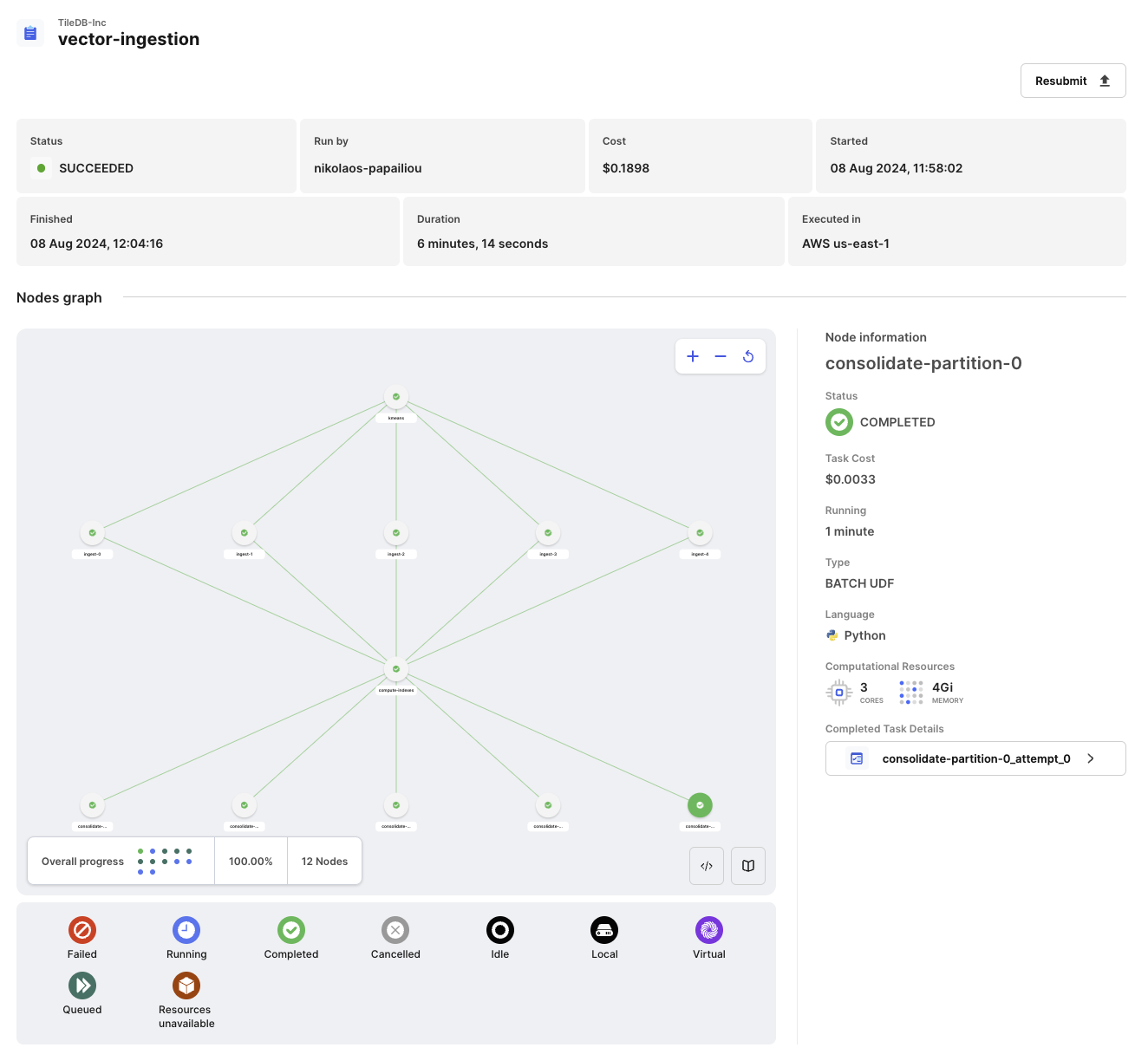
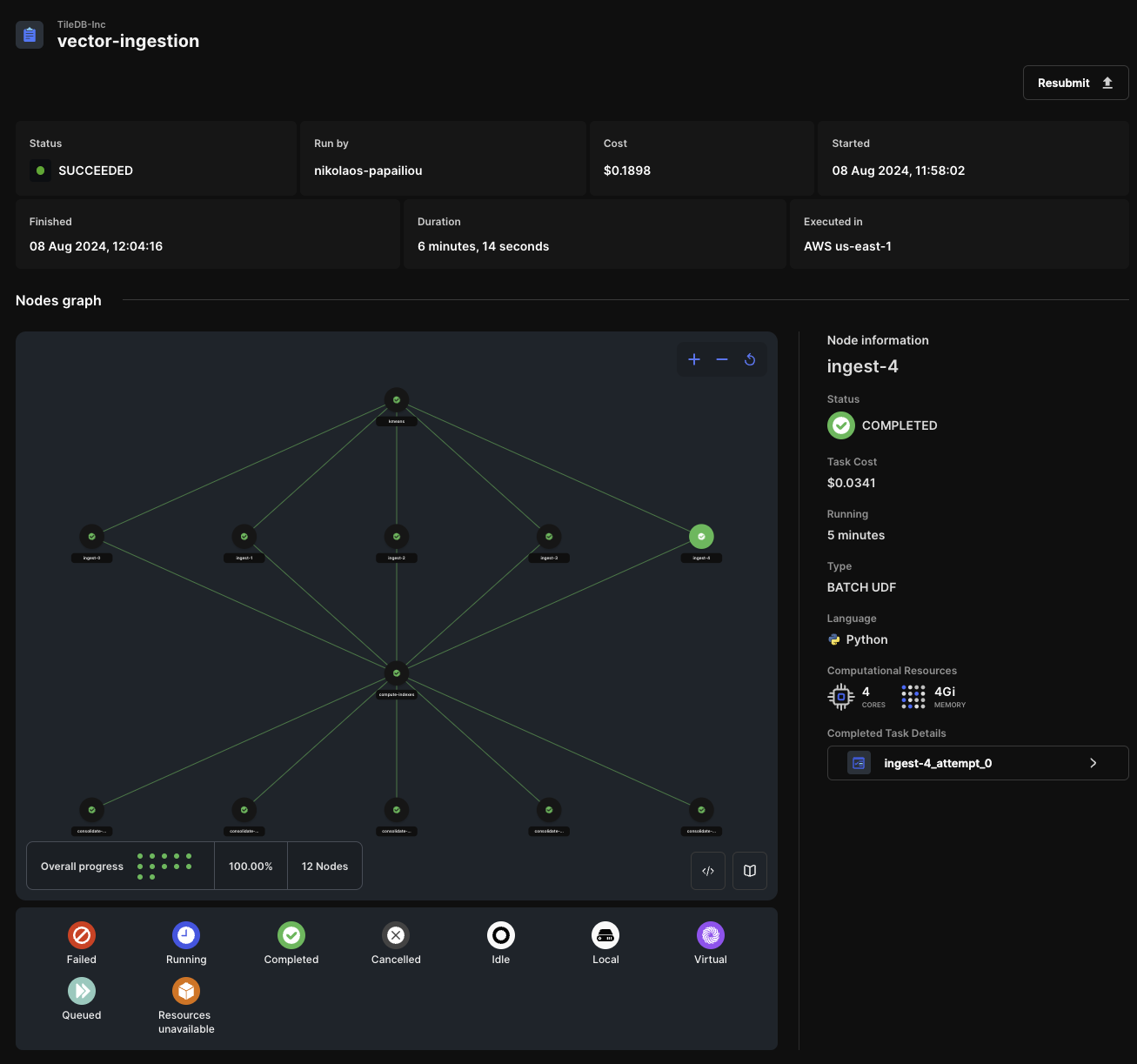
Distributed ingestion can greatly speed up and horizontally scale out the ingestion of vectors. In this example, you will ingest the entire SIFT 10 million vector dataset using the IVF_FLAT index (which involves computing \(k\)-means, a computationally intensive operation) in 6 minutes, for a total cost of approximately $0.18 in TileDB Cloud.
To use distributed execution in TileDB Cloud, you can change the ingestion mode of TileDB-Vector-Search ingest function. Passing mode=vs.Mode.BATCH instructs TileDB-Vector-Search to use distributed computation with TileDB Cloud batch task graphs. For more information on task graph modes, visit the Scale: Task Graphs section.
You can ingest the first 10M vectors of SIFT-1B dataset to an IVF_FLAT index as follows:
Note that ingest automatically calculates the number of workers that will work in parallel to perform the ingestion, and you don’t need to spin up any cluster. Everything is serverless!
TileDB Cloud records all the details about the task graph, and lets you monitor it in real time. You can find this information under Monitor -> Logs on the TileDB Cloud UI console.
Distributed queries
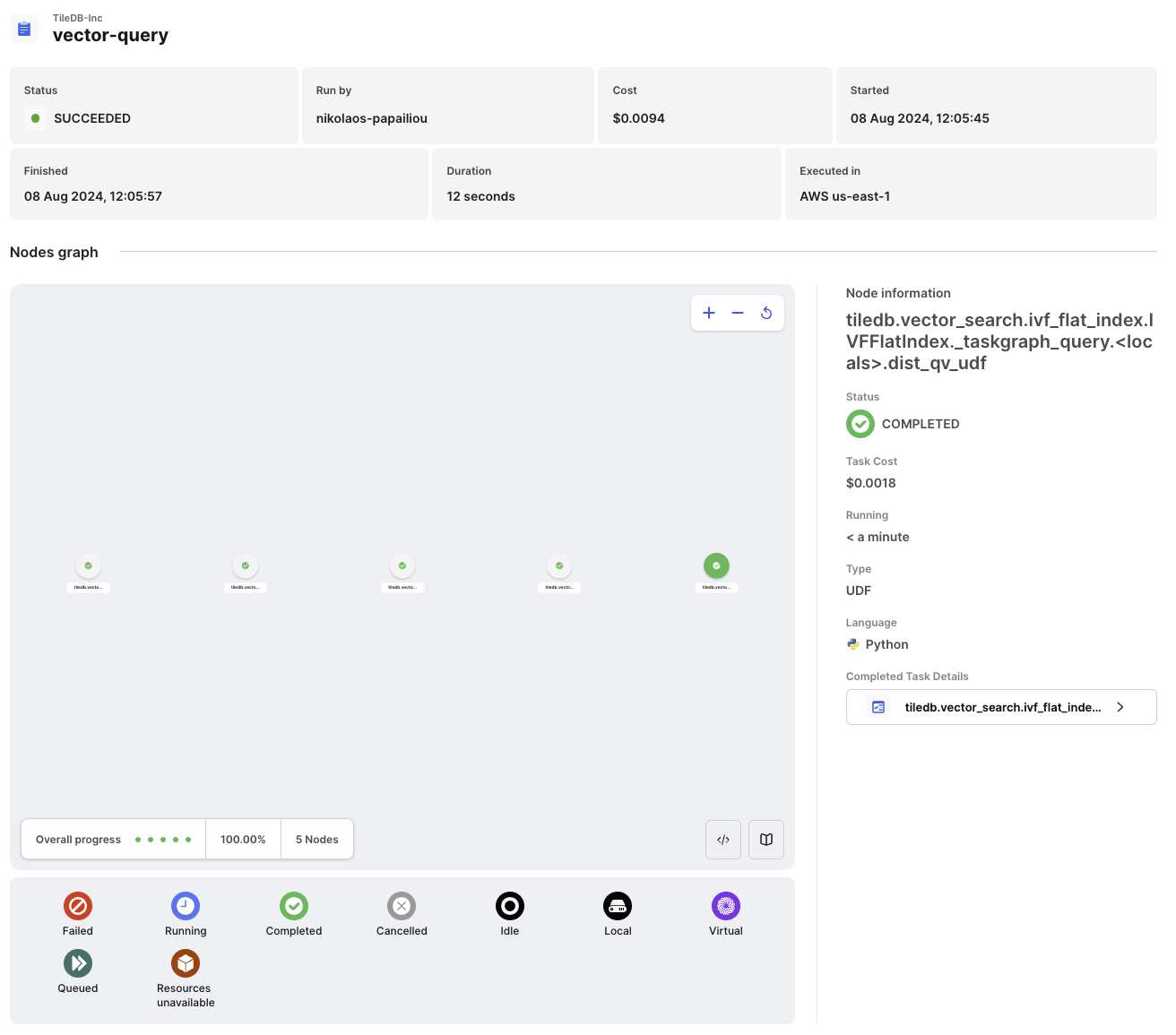
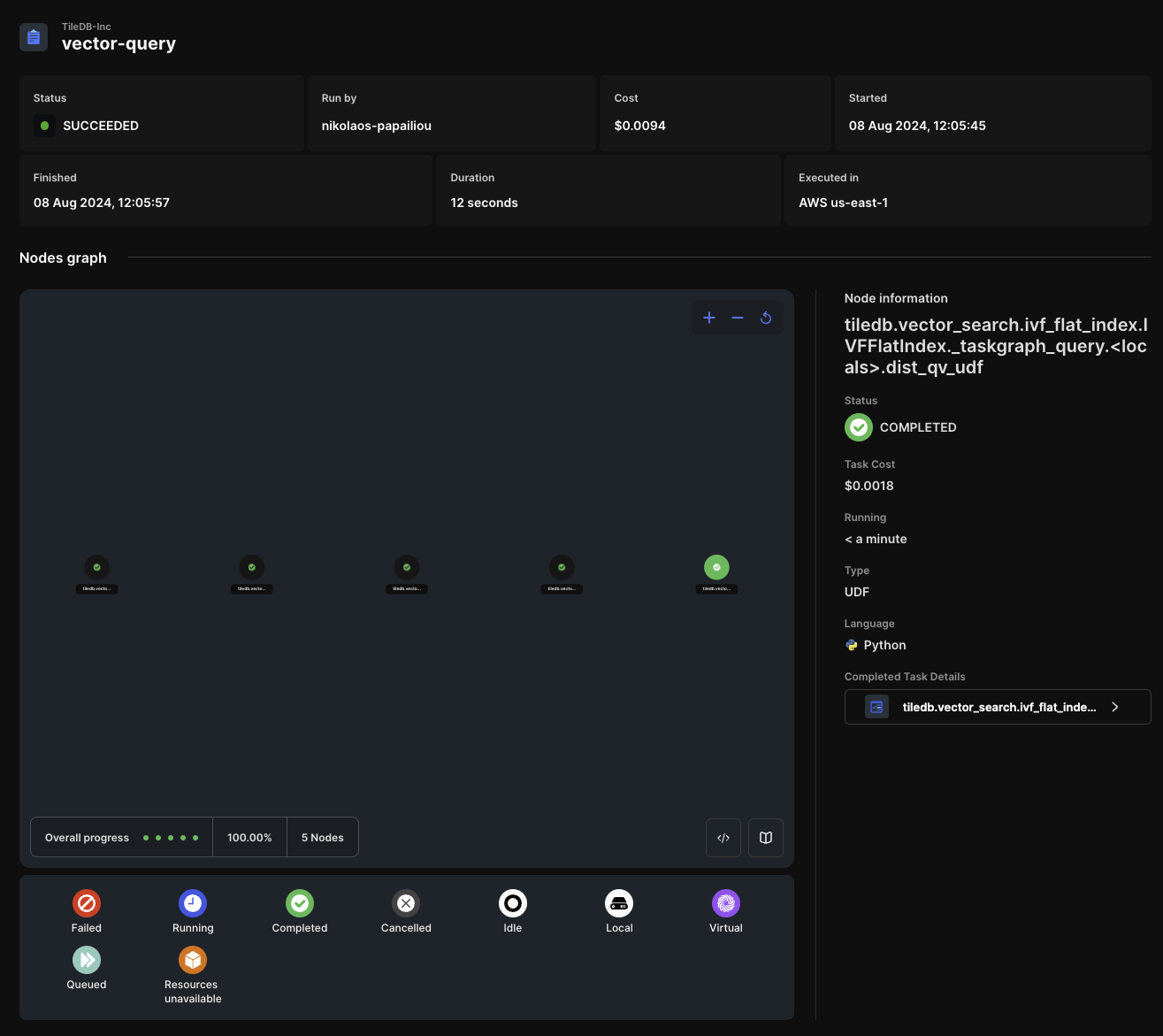
Distributed queries give you the capability of using more computing resources to query larger datasets with lower latency, yielding a much higher queries per second (QPS). In the example below, you will submit a batch of 1000 query vectors to the 10 million vector dataset, all executed in 12 seconds for a cost of approximately $0.009.
Performing a distributed query is similar to the ingestion described above, but now you can set mode to REALTIME as it will be faster:
Cleanup
Clean up in the end by deleting the created index: