Data Layout
It is strongly recommended to read the following sections before you learn about the data layout.
The data layout dictates how coordinates and values of multi-dimensional cells are serialized and stored in the inherently 1-dimensional storage medium, in the various files created by TileDB.
This section covers the following topics:
- Cell global order: This is the way cells are mapped into a unique, 1-dimensional order.
- Columnar format: The values of each attribute, the coordinates in sparse arrays and the offsets of variable-length attributes are all stored in separate files.
- Data tiles: The groups of non-empty cells, which serve as the atomic unit of I/O and compression.
- Fill values: How TileDB stores fill values for partially populated tiles in dense arrays.
Cell global order
TileDB handles the global cell order differently for dense and sparse arrays.
Dense arrays
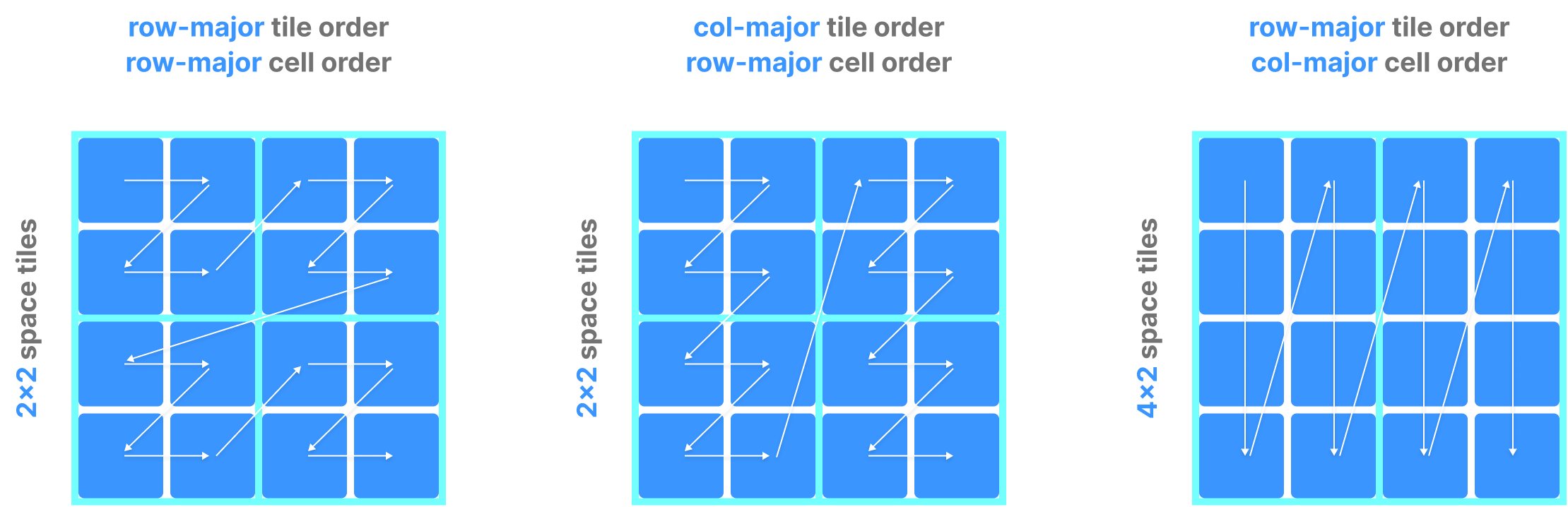
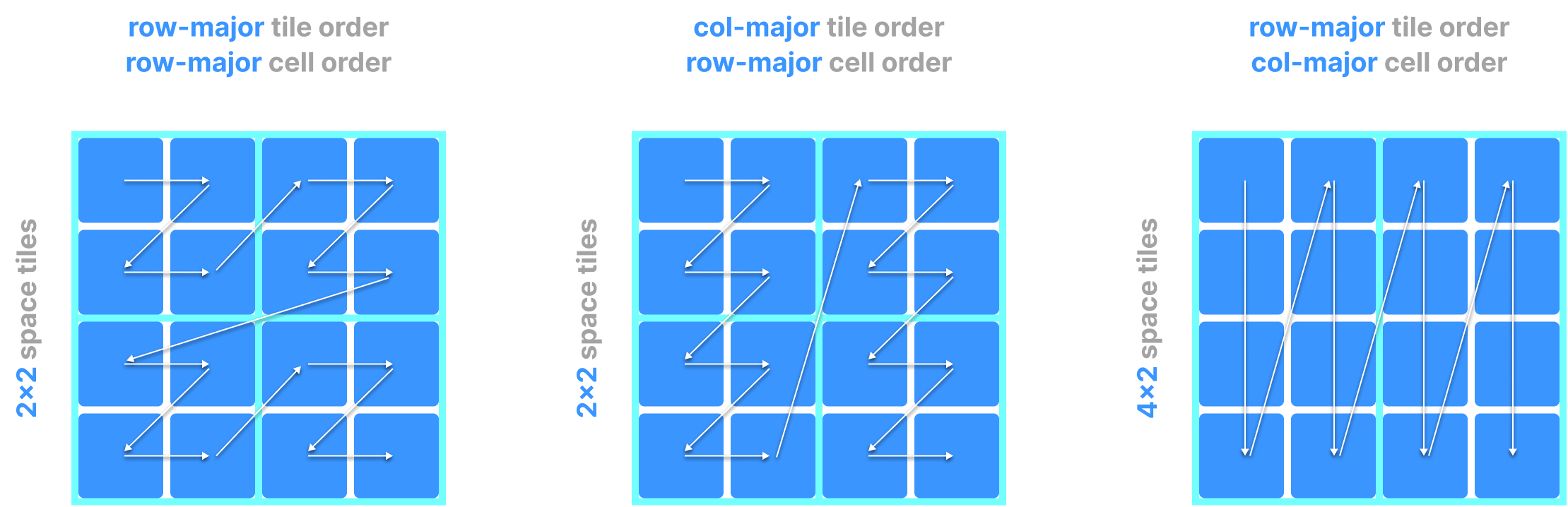
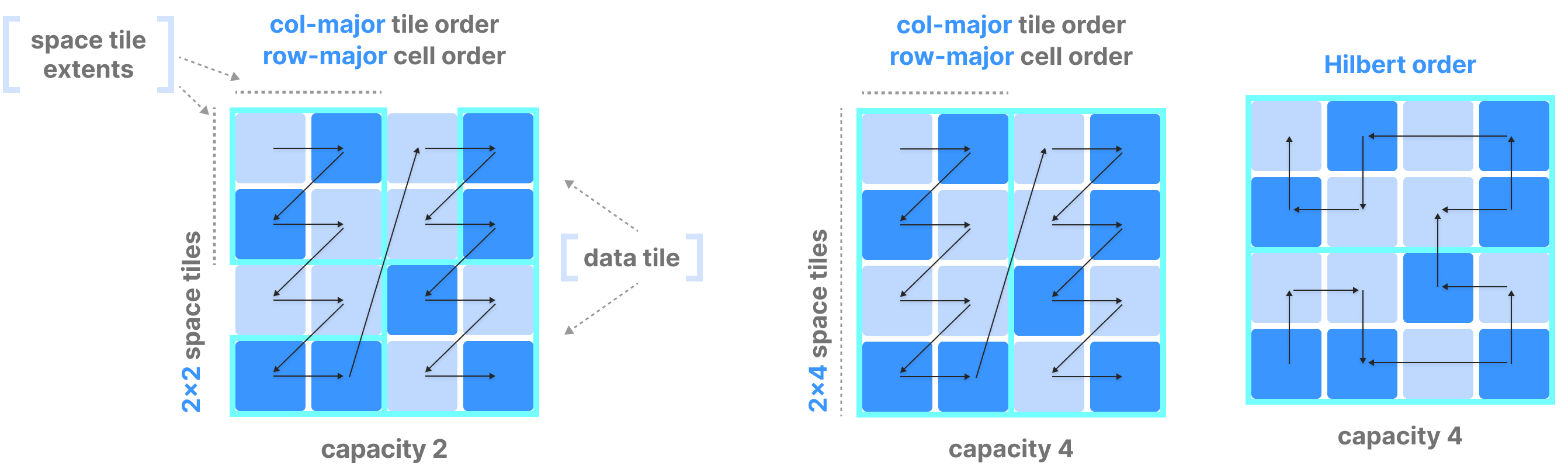
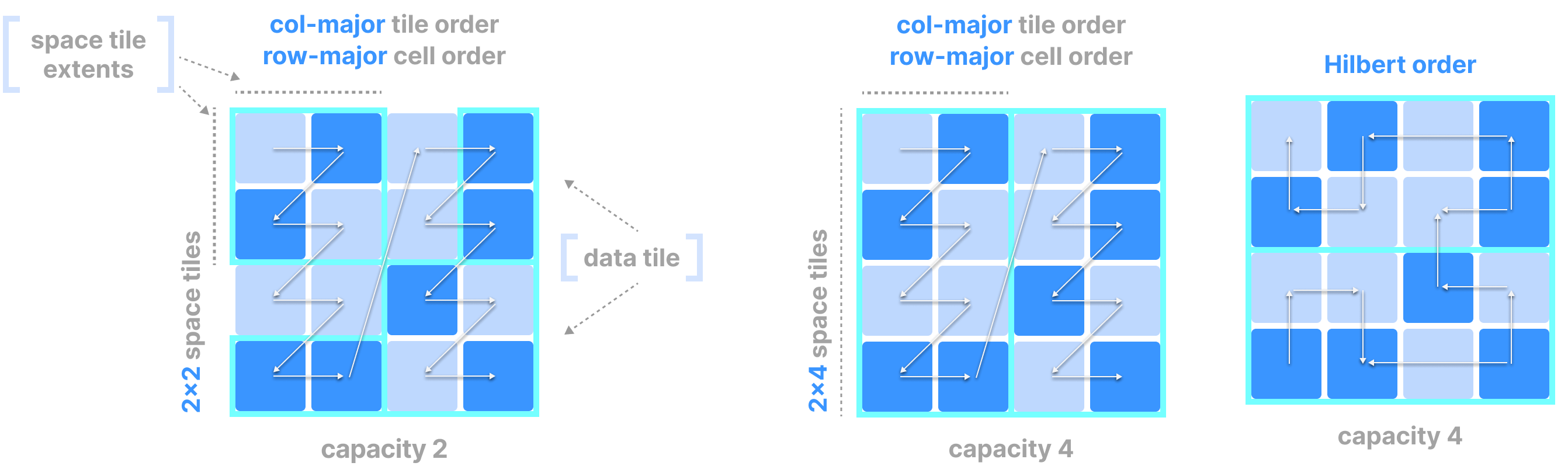
In dense arrays, the global cell order is determined by three parameters, all specified by the user upon array creation:
- Tile extent per dimension (which partitions each dimension in equal segments)
- Tile order (can be either row-major or column-major)
- Cell order (can be either row-major or column-major)
In arrays with more than two dimensions:
- row-major means that the faster running index in the order is the last dimension (e.g.,
[0,0,0], [0,0,1], [0,0,2], etc.). - col-major means that the faster running index in the order is the first dimension (e.g.,
[0,0,0], [1,0,0], [2,0,0], etc.).
The figure below shows examples of how different choices of the above parameters lead to different global orders in dense arrays.
Sparse arrays
In sparse arrays, the global cell order is determined by the following parameters, all specified by the user upon array creation:
- The same parameters as in dense arrays, or
- By using a Hilbert space-filling curve. In this case, all the user needs to specify is the domain of each dimension, and set the cell order as
hilbert(the tile extents and tile order have no effect in this case). Note that the Hilbert curve is based on quantizing each dimension domain and, therefore, it is strongly affected by it (e.g., if the domain is too small, all cells may map to the same Hilbert value and, hence, cell locality will be destroyed).
The figure below shows examples of how different choices of the above parameters lead to different global orders in sparse arrays.
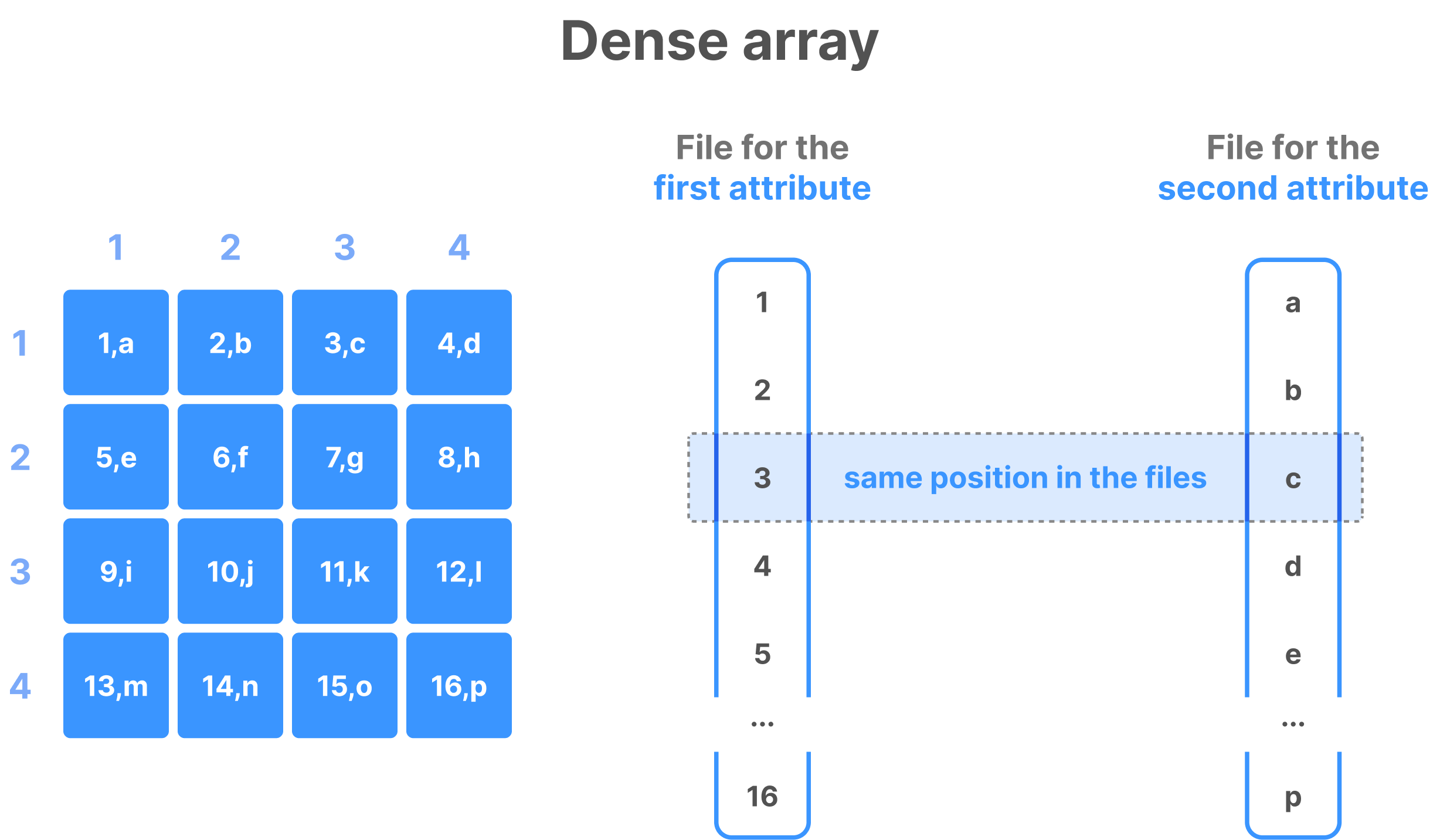
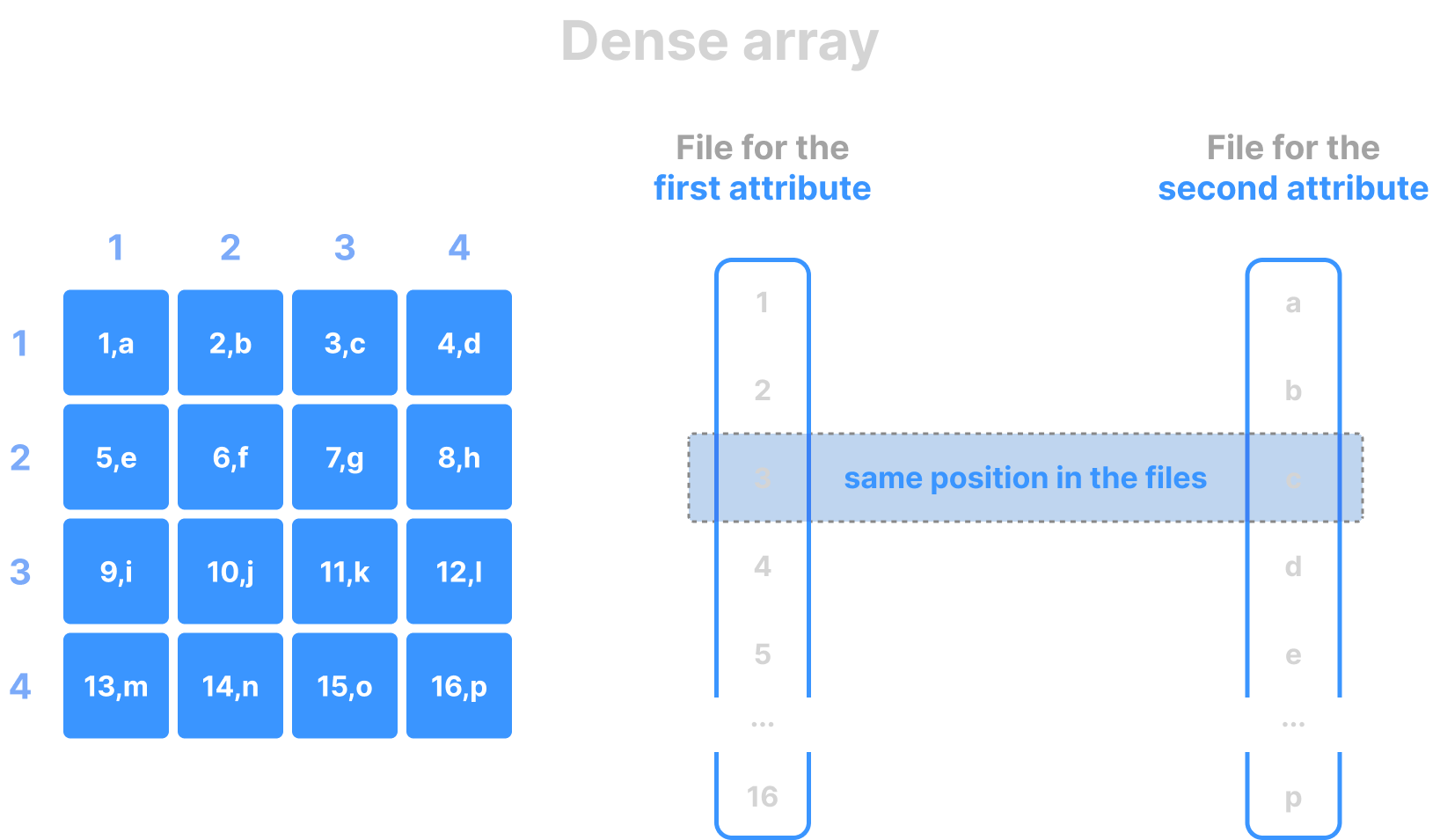
Columnar format
TileDB implements the so-called columnar format (adopted from analytical databases). This means that the cell values across each attribute are stored in a separate file. The same is true for the cell coordinates in sparse arrays, as well as the offsets of variable-length attributes. It is important to stress that all the values on all different files follow the same cell global order. The figures below show examples of various columnar layouts in dense and sparse arrays.

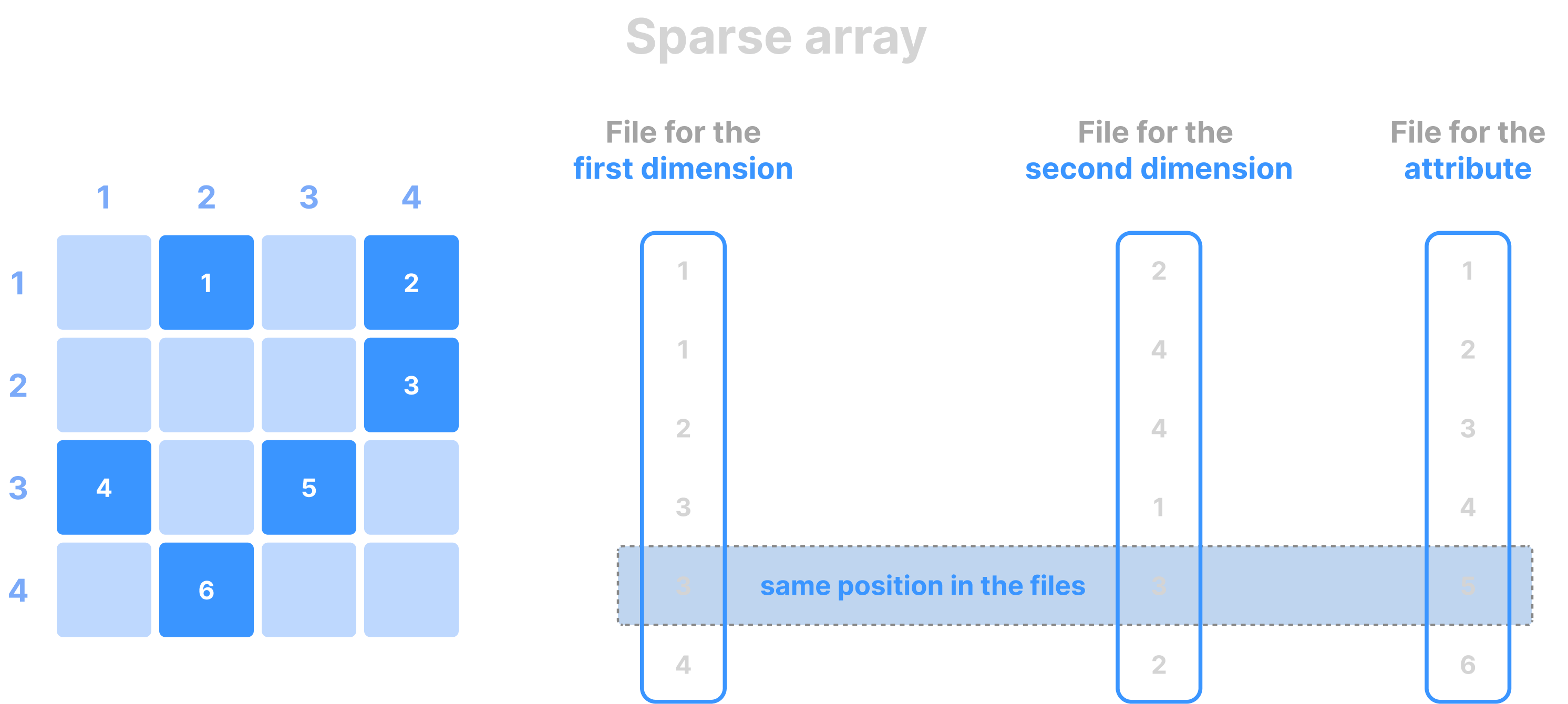

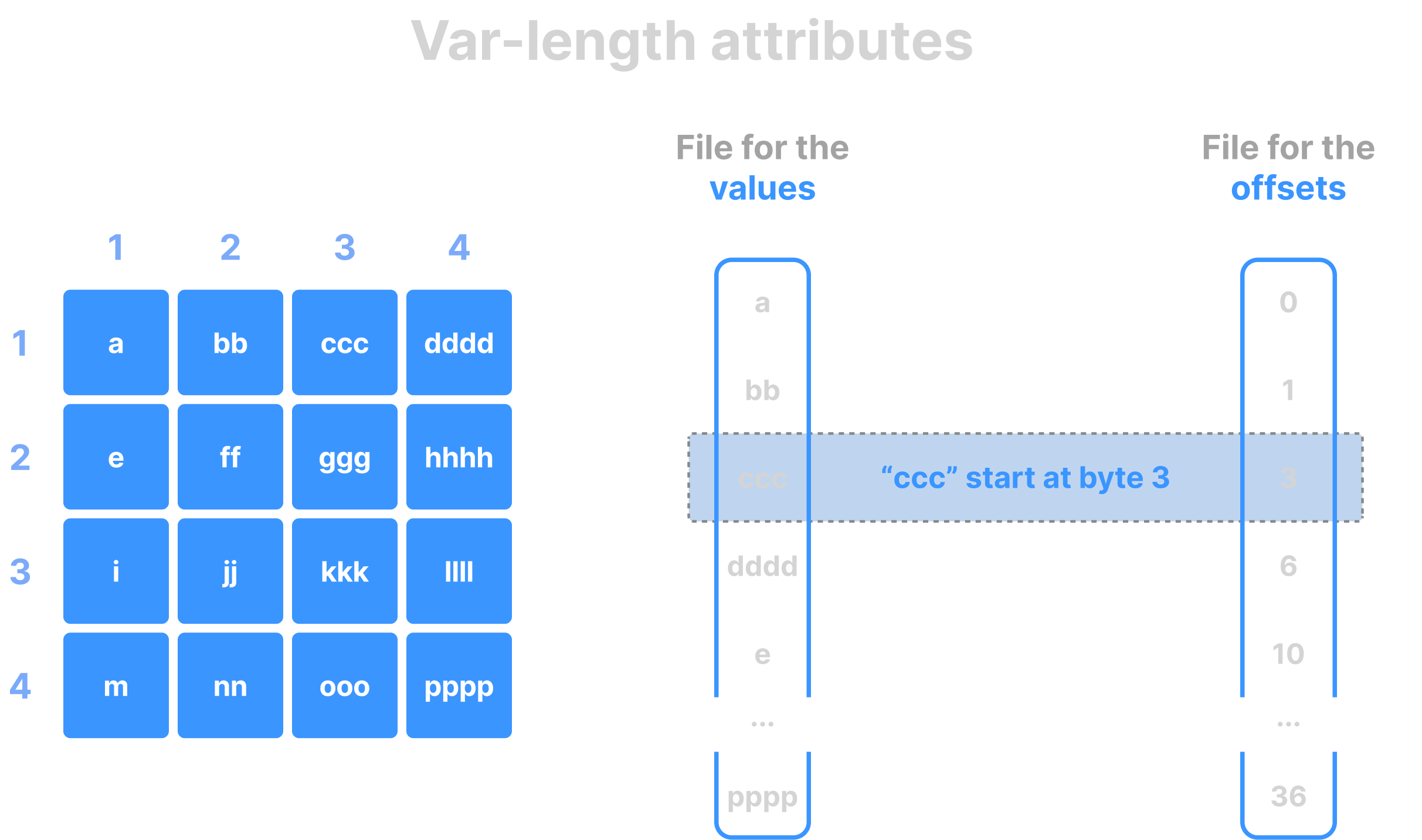
Data tiles
A data tile is the atomic unit of compression and I/O. Data tiles in dense and sparse arrays are different:
- In dense arrays, the space tile (i.e., the tile defined by the tile extents on each dimension) is the same as the data tile (i.e., the group of non-empty cells the data tile includes).
- In sparse arrays, the space tile is not the same as the data tile, because a space tile may contain empty cells that TileDB does not materialize. If the space and data tiles were the same, then there could be scenarios where one tile contains one cell, and another millions, leading to I/O and compression imbalance. To mitigate this, sparse arrays receive an extra parameter upon creation, called capacity, which is the fixed number of non-empty cells that a data tile should contain. To determine which cells correspond to which tile, TileDB just follows the cell global order and packs non-empty cells in groups with size equal to the specified capacity.
In both the above cases, a logical data tile encompasses only logical non-empty cells, whereas a physical data tile corresponds to the non-empty cell values on a specific attribute, dimension (for sparse coordinates) or offset file (for variable-length attributes).
The following figure shows examples of space and data tiles in dense and sparse arrays.
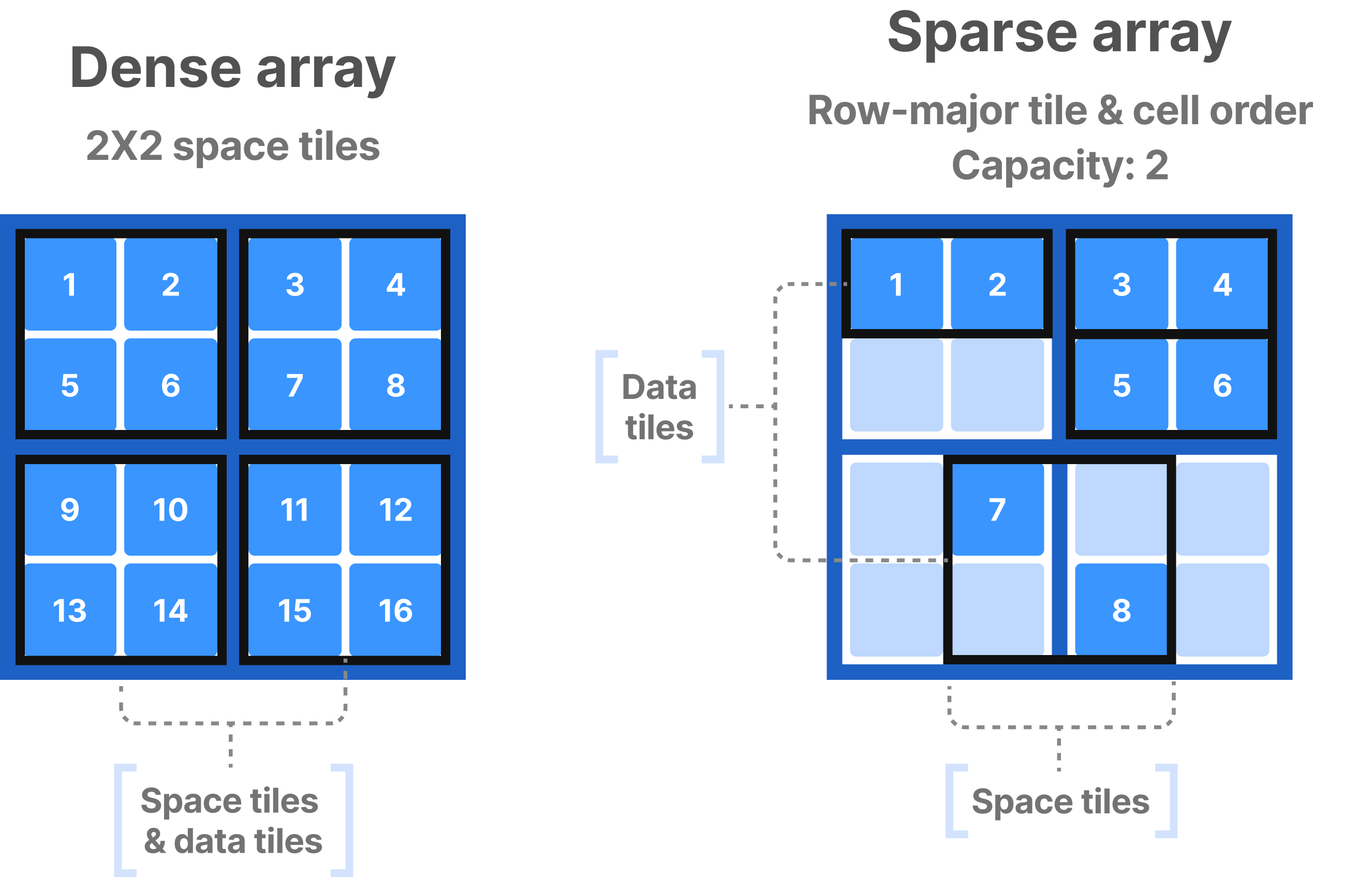
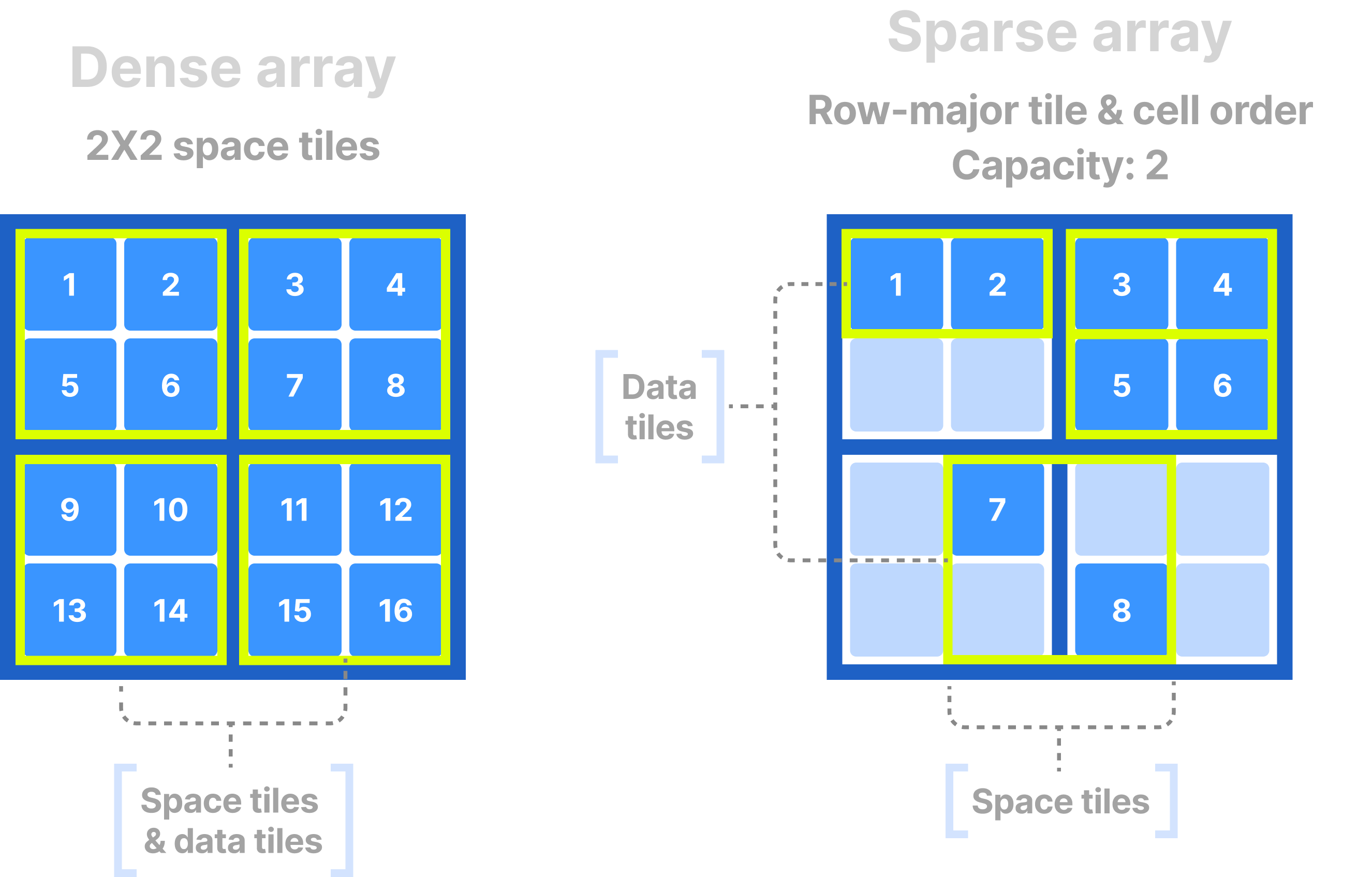
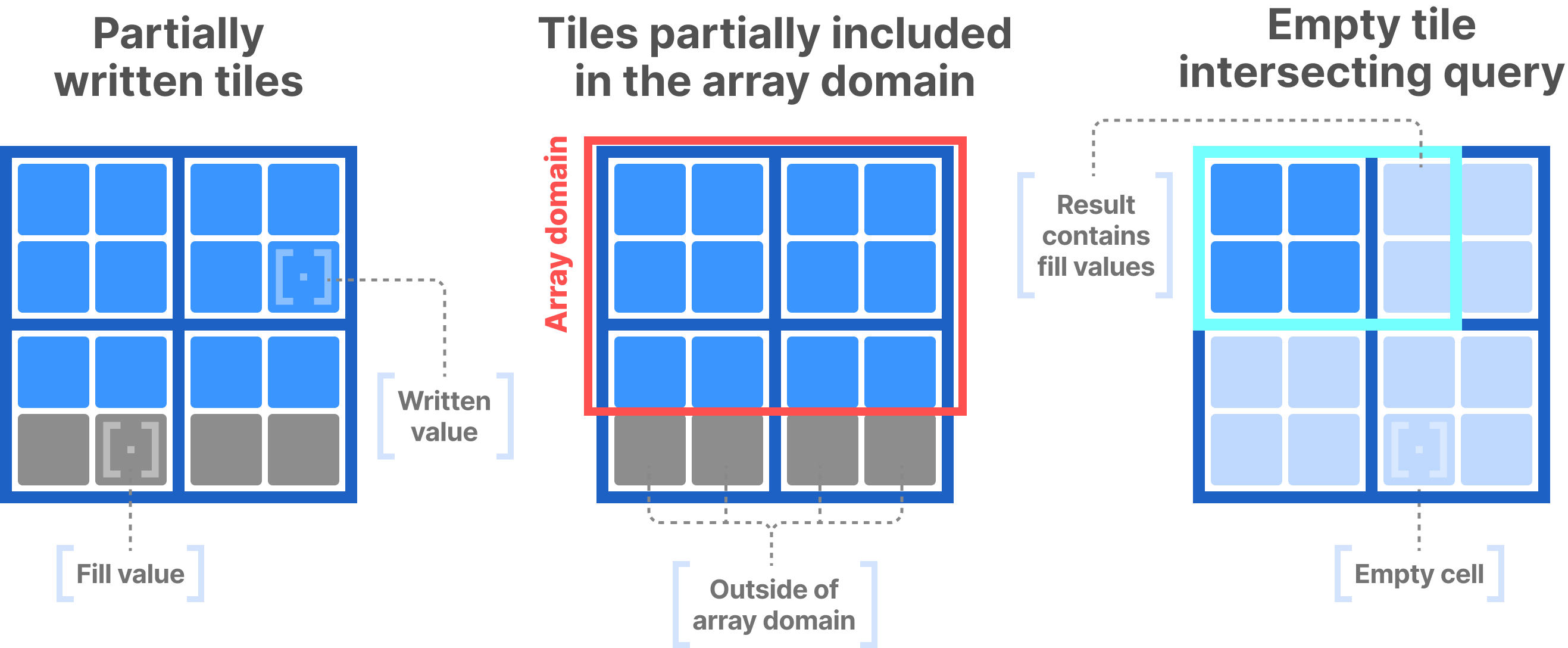
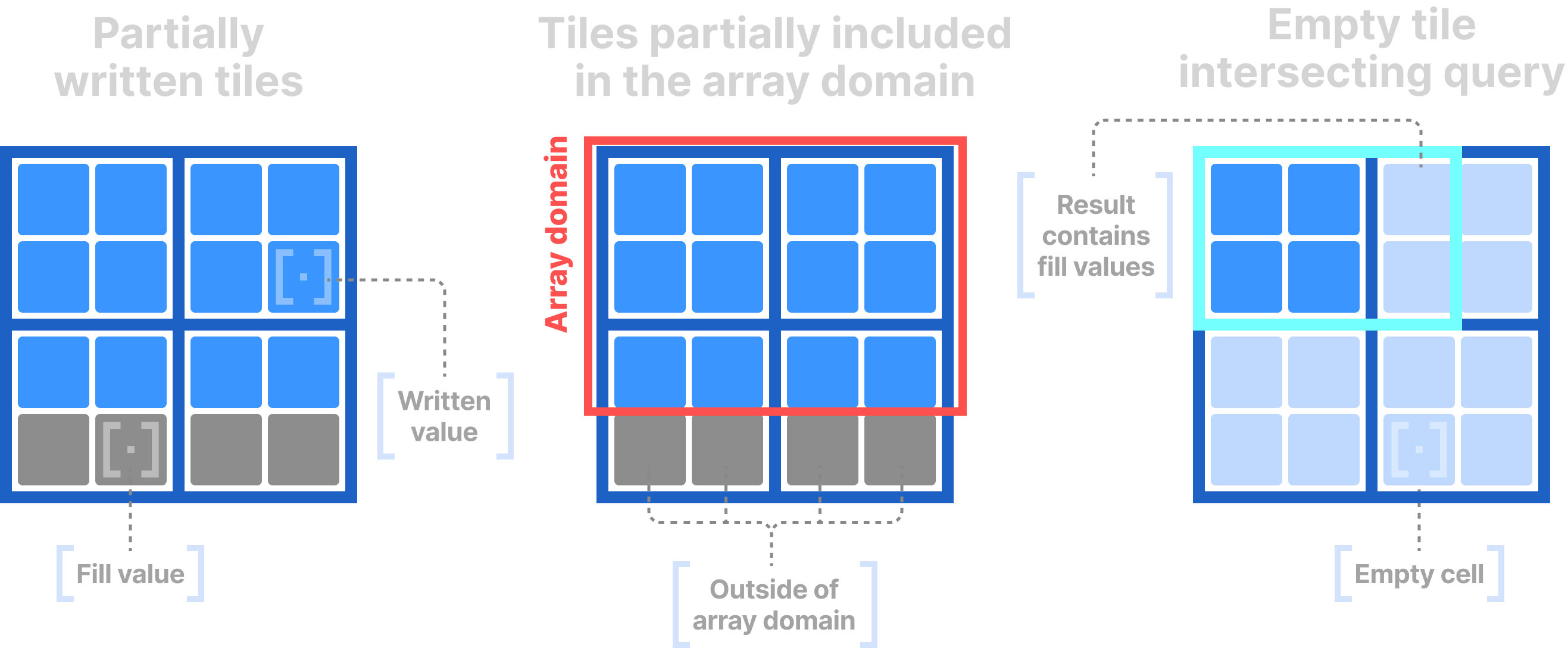
Fill values
Fill values are applicable only to dense arrays, and occur when data tiles are partially written. This happens in three cases:
- The user incrementally populates the array and writes a subarray such that it partially intersects certain tiles.
- The array domain does not contain integral tiles.
- The query subarray intersects empty tiles (or tiles with fill values).
In these cases, TileDB fills the partial tiles or result with special fill values. You can read about the default fill values in section Key Concepts: Tiles. Practically, a fill value represents a non-empty cell in a dense array.
The following figure shows examples of the above three scenarios, where TileDB uses fill values.