import scanpy as sc
import tiledbsoma
import tiledbsoma.io
from matplotlib import patches as mplp
from matplotlib import pyplot as plt
from matplotlib.collections import PatchCollection
tiledbsoma.show_package_versions()Access Spatial Data
life sciences
single cell (soma)
spatial
tutorials
Learn how to access the spatial data components of a SOMA Experiment.
TileDB-SOMA supports spatial omics data, such as those generated by 10X Visium. SOMA experiments created from these spatial datasets include extra elements beyond typical single-cell experiments, such as high-resolution tissue images and spatial coordinates for each measurement location. This tutorial guides you through understanding these new spatial components and shows how to access them using TileDB-SOMA’s API. You’ll learn how to do the following:
- Open a TileDB-SOMA experiment with spatial data.
- Navigate the experiment’s spatial components, including scenes, images, and spatial dataframes.
- Load image data for visualization.
- Access spatial location data using bounding boxes.
Prerequisites
While you can run this tutorial locally, note that this tutorial relies on remote resources to run correctly.
You must create a REST API token and create an environment variable named $TILEDB_REST_TOKEN set to the value of your generated token.
However, this is not necessary when running this notebook inside of a TileDB workspace where the API token is automatically generated and configured for you.
Setup
Load the necessary packages. Import tiledbsoma to interact with SOMA data, scanpy for some data visualization, and matplotlib for displaying images and plots.
Configure the notebook to display images in jpeg format, which keeps the size of the rendered notebook smaller.
Dataset
The dataset used here is a spatial gene expression dataset of a mouse brain coronal section (FFPE), generated by 10X Genomics’ Visium CytAssist platform. To view the raw data, visit 10x Genomics. This data has been processed with Space Ranger and ingested into TileDB-SOMA. You can find it on TileDB.
Tip
Visit the Spatial Data Ingestion tutorial for information on how to create a SOMA experiment from a spatial dataset.
Spatial components
The spatial collection organizes the spatial data elements. This collection stores all spatial information associated with your experiment.
Scenes
Inside the spatial collection, you can find one or more Scene objects. A scene represents a distinct view or a physical section of the sample. This particular dataset has a single scene called scene0.
Each Scene includes a coordinate space shared by all its members.
A Scene has three key SOMA collections:
img: This collection stores image data, such as the high- and low-resolution slide images of the tissue sample.obsl: This collection stores theobs-indexed location data. In this case, it has aPointCloudDataFramecalledloc, holding the Visium spot locations and sizes.varl: This collection stores thevar-indexed location data. In this example, the collection is empty because Visium datasets don’t include spatial feature data.
Images
Inside the img collection, you will find one or more MultiscaleImage objects.
In this example, a single MultiscaleImage image named “tissue” exists.
This object has a pyramid of images at different resolutions, which supports efficient loading of each zoom level.
The coordinate_space property of the MultiscaleImage has the pixel coordinate space of the image.
Use the level_count property to see the number of levels in the MultiscaleImage.
Examine the metadata for each image resolution level in the tissue collection.
Each image is a DenseNDArray with dimensions corresponding to the image’s width, height, and color channels (RGB).
You can use the DenseNDArray’s read method to load the image data. This next snippet shows how to load the low-resolution image data and store the results as a NumPy array with shape (height, width, channels).
Now, visualize the low-resolution image with matplotlib.
fig, ax = plt.subplots()
ax.imshow(im, cmap="gray")
plt.show()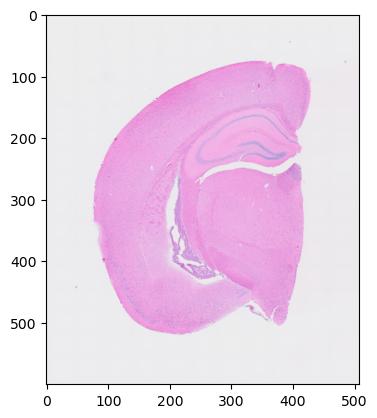
Spatial Dataframe
The obsl collection has a PointCloudDataFrame called loc, which holds the spatial coordinates for each spot in the experiment.
Just like with the MultiscaleImage, you can access the coordinate_space property of the PointCloudDataFrame to see the coordinate space of the point cloud.
This spatial dataframe has a key soma_joinid that maps to the obs array in the root of the SOMA experiment and the x and y coordinates of each spot. Read the data from the loc dataframe into memory.
You can use the read_spatial_region method to perform a spatial query and retrieve the spots within a defined bounding box:
Finally, visualize the tissue spots with matplotlib.
radius = scene.obsl["loc"].metadata["soma_geometry"]
spot_patches = PatchCollection(
[
mplp.Circle((row["x"], row["y"]), radius=radius, color="b")
for _, row in spots.iterrows()
]
)
fig, ax = plt.subplots()
ax.set_xlim((0, spots["x"].max()))
ax.set_ylim((0, spots["y"].max()))
ax.invert_yaxis()
ax.add_collection(spot_patches)
plt.show()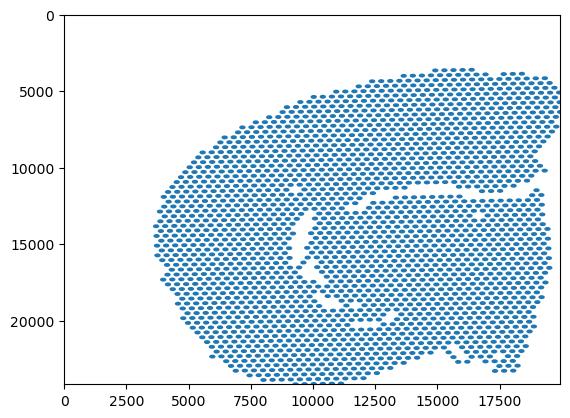
Summary
This tutorial covered basic methods for accessing spatial data within a SOMA experiment. This should give a solid foundation for building more complex spatial access patterns with TileDB-SOMA.