Tiling and Data Layout
It’s strongly recommended to read the following sections before you learn about the data layout.
The following sections include performance tips on choosing the tiling and the data layout in dense and sparse arrays.
Dense arrays
In dense arrays, space tiles have a one-to-one correspondence to data tiles (for each attribute), and the data tile is the atomic unit of I/O and compression. TileDB will fetch all data tiles corresponding to every space tile that overlaps with the query subarray. Thus, you must set the tile extents along each dimension in a way that the resulting space tiles roughly follow the shape of the most typical subarray queries.
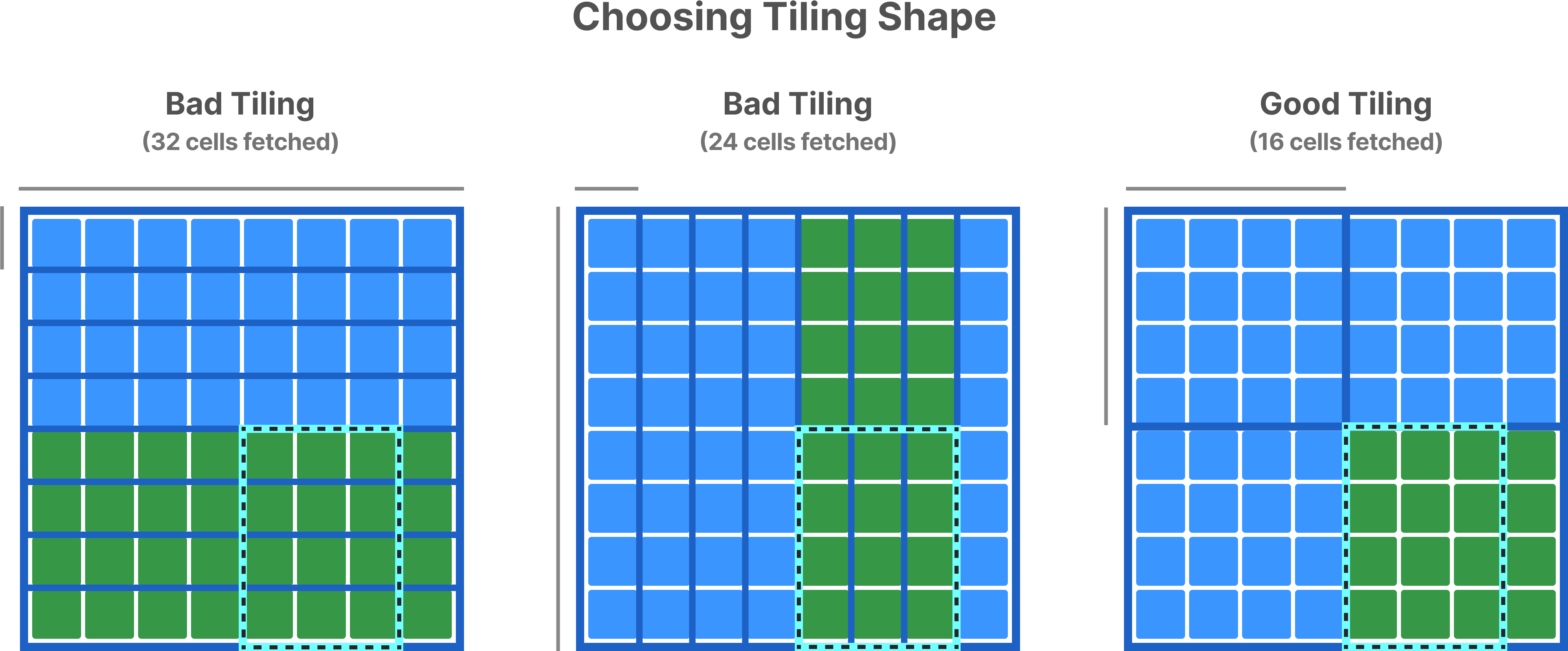
Furthermore, the size of the space tile affects performance. A larger tile may lead to fetching a lot of irrelevant to the query data, but it can also result in better compression ratio and parallelism (for both filtering and I/O). You should define the space tile in a way that the corresponding data tiles along each attribute are at least 64KB (a typical size for the L1 cache).
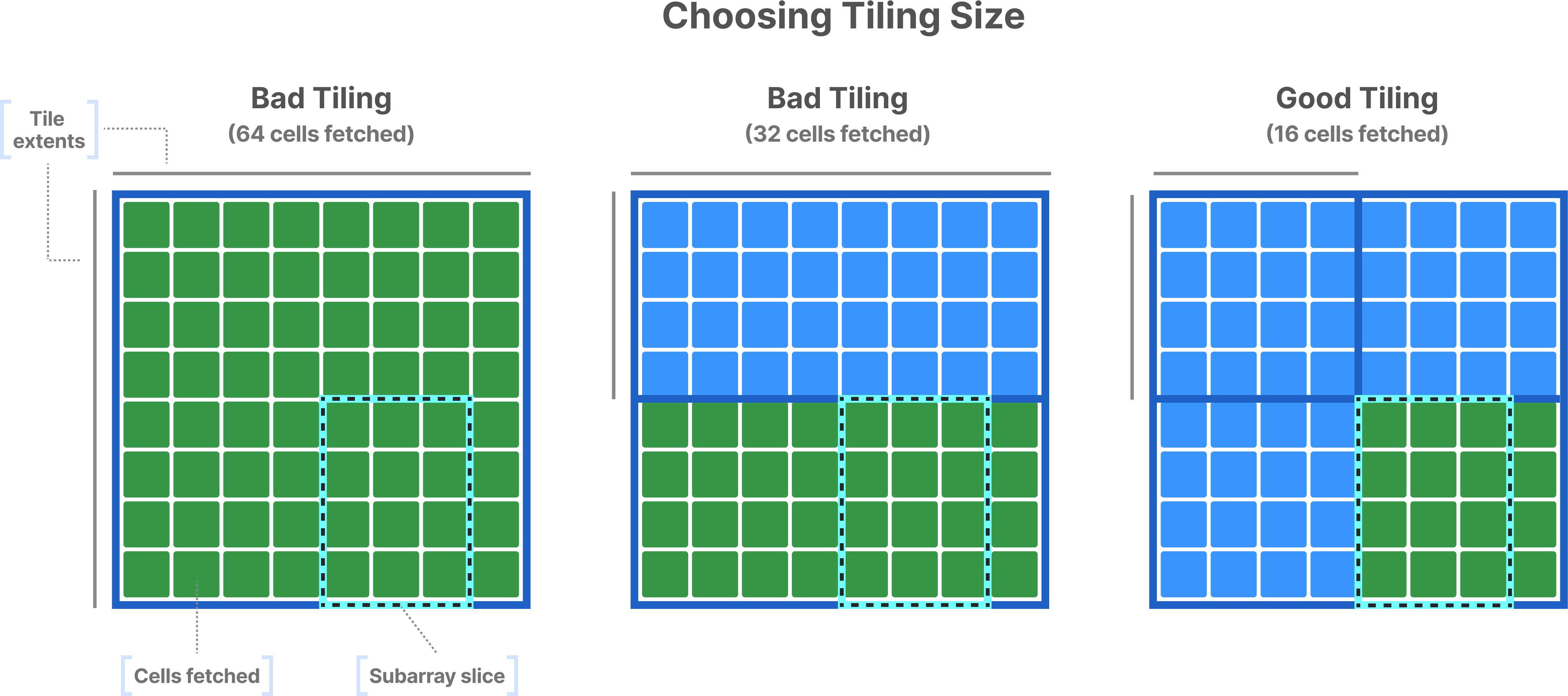
Along with the space tile, the tile and cell order influences the global cell order (that is, the way TileDB arranges the data tile values in physical storage). In general, both the tile and cell order should follow the layout in which you are expecting the read results. This maximizes your chances of higher concentrations of relevant data in smaller byte regions in the physical files, which TileDB can exploit to fetch the data faster.
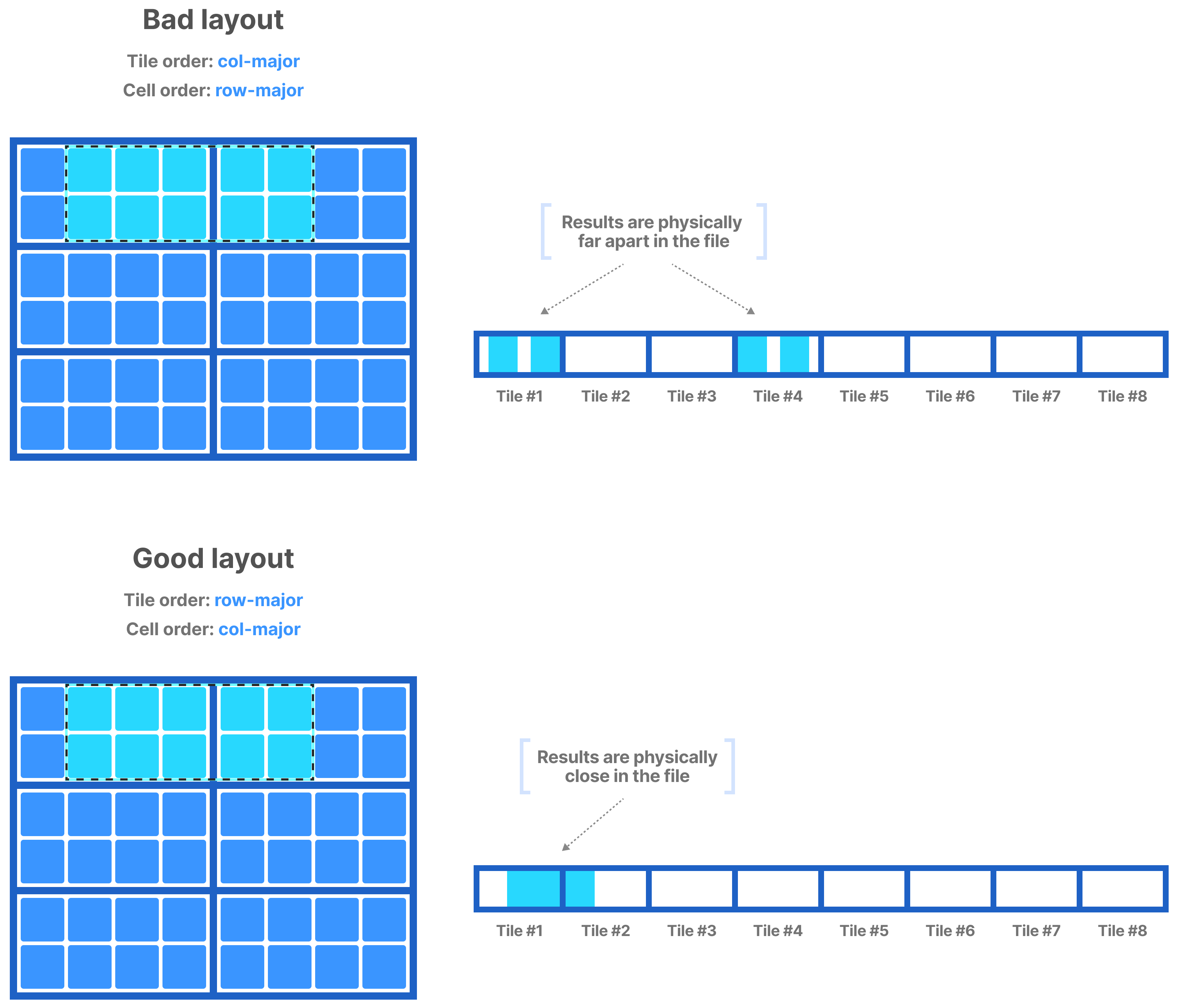
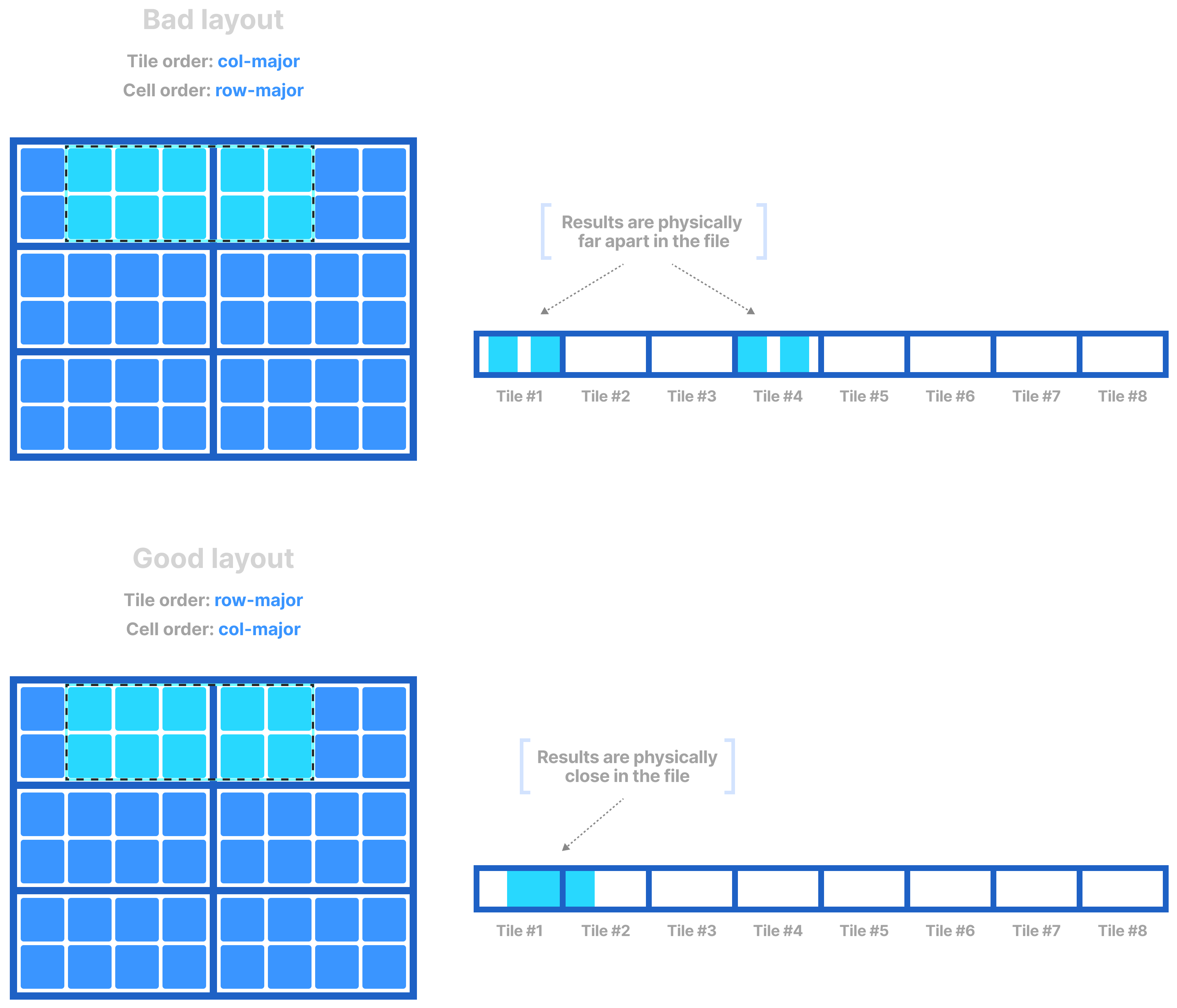
Sparse arrays
In sparse arrays, cells may be empty. Thus, space tiles don’t have the same one-to-one correspondence to data tiles. In contrast, the space tiles decide the global cell order and, thus, can preserve the spatial locality of the values in physical storage. By setting the global cell order, space tiles calculate the shape of the minimum bounding rectangle (MBR) of each data tile. Recall that TileDB fetches only the data tiles whose MBR intersects with the subarray query. Thus, you must set the tile extents in a way that the resulting space tiles have a similar shape to the subarray query.
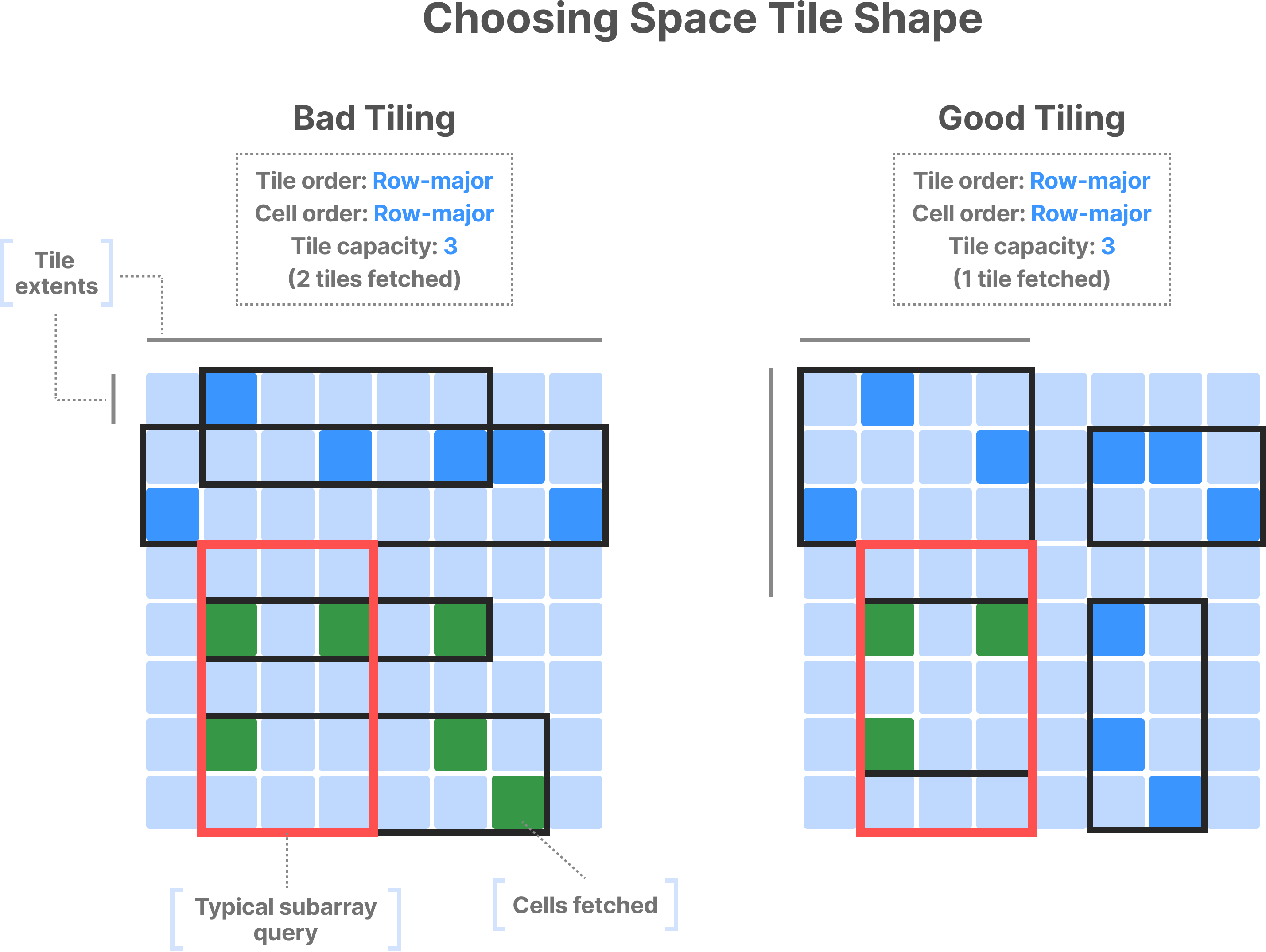
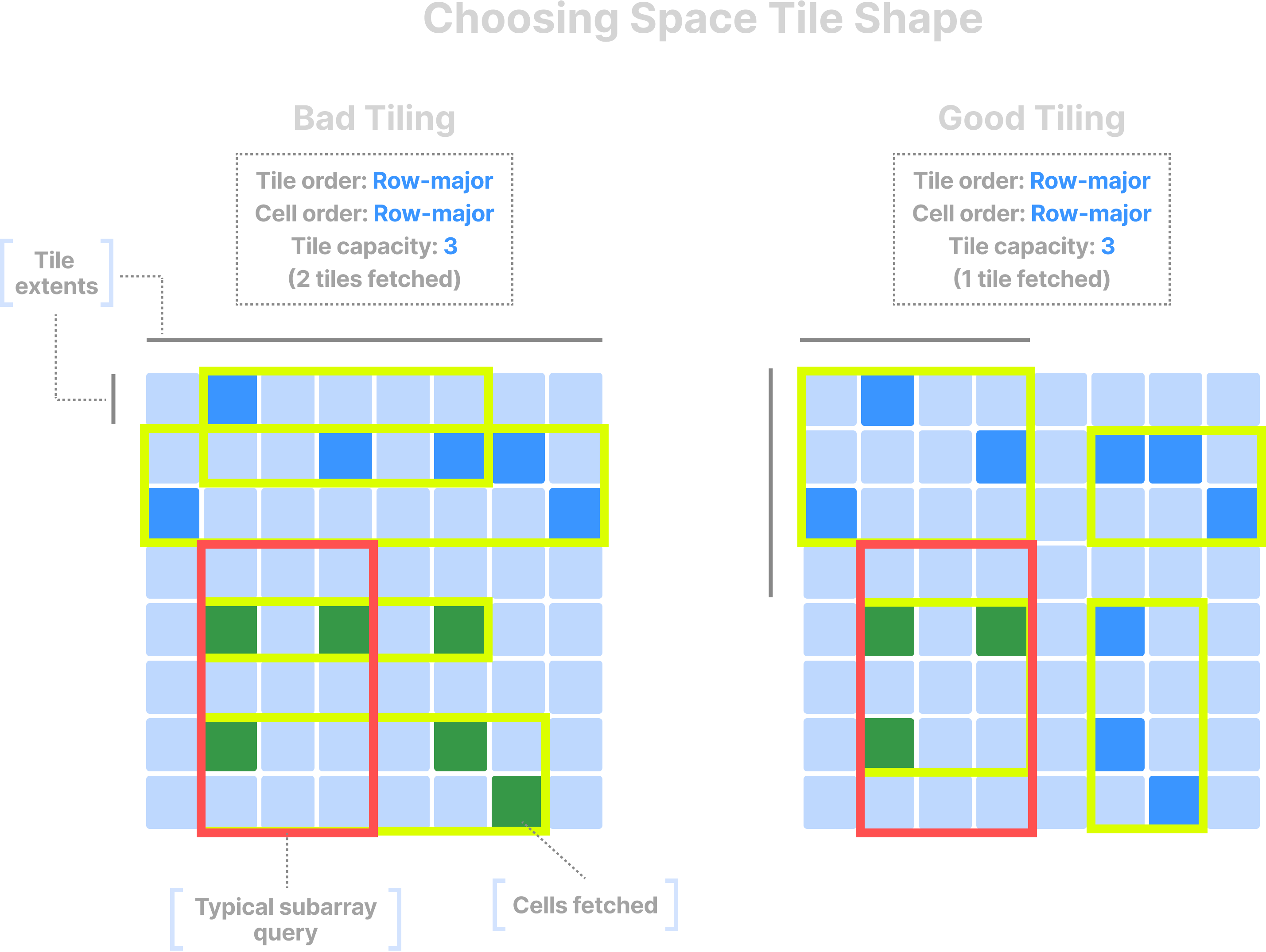
Recall also that the tile capacity—not the tile extents—decides the size of the data tile in sparse arrays. Similar to the case of dense arrays, you must set the tile capacity appropriately to balance fetching irrelevant data and maximizing compression ratio and parallelism.
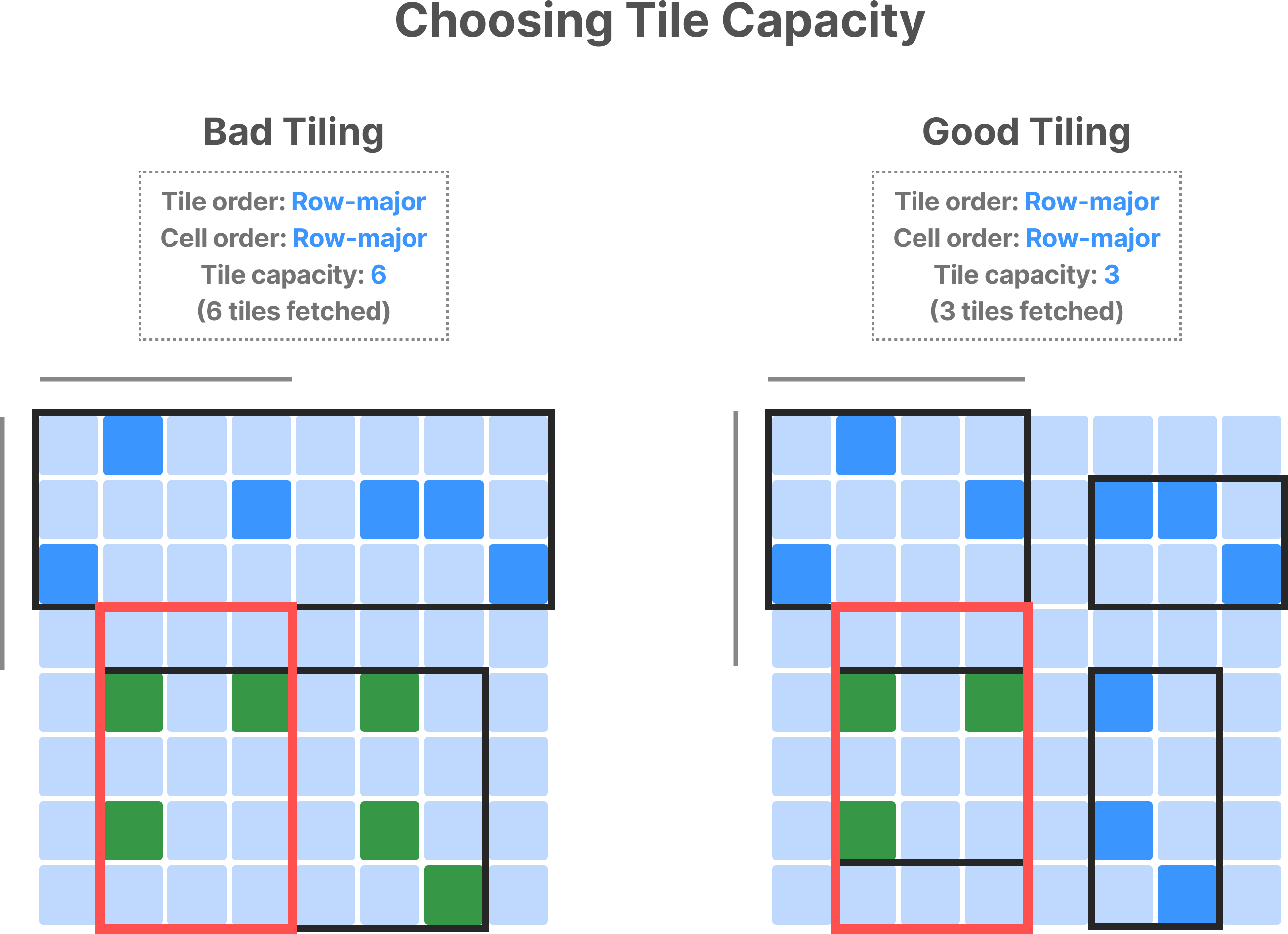
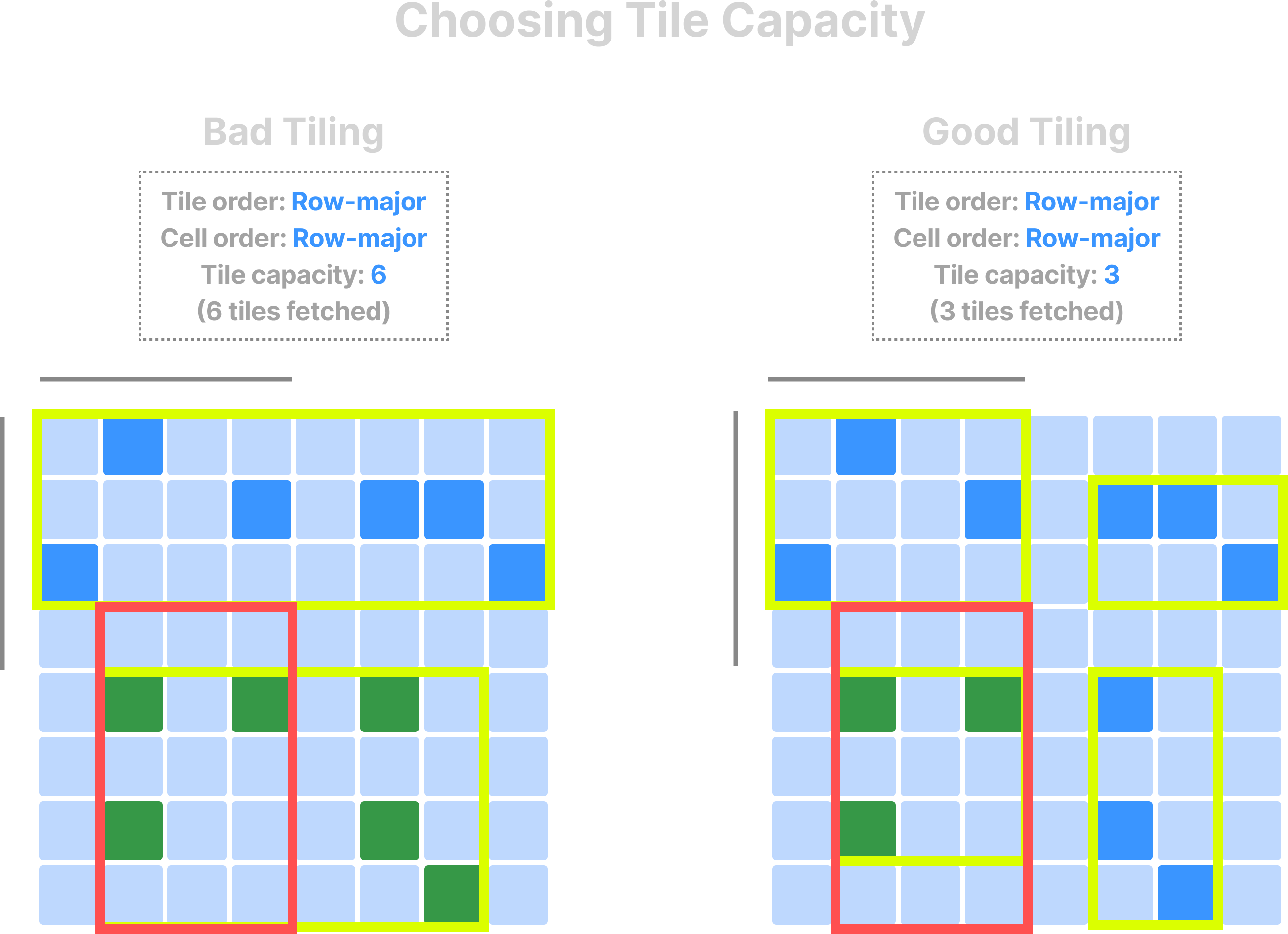
Finally, for similar reasons to the dense case, you should choose the tile and cell order according to the typical result layout.