import tempfile
from typing import Optional, Sequence
import pyarrow as pa
import pyarrow.compute as pc
import tiledbsoma
import tiledbsoma.io
import tiledbsoma.io.spatial
from matplotlib import patches as mplp
from matplotlib import pyplot as plt
from matplotlib.collections import PatchCollection
tiledbsoma.show_package_versions()Manage Coordinate Spaces
life sciences
single cell (soma)
spatial
tutorials
Learn how to manage spatial coordinates in TileDB-SOMA.
This tutorial will guide you through the fundamental concepts of coordinate spaces and coordinate transformations within TileDB-SOMA. These concepts are essential for working with any of the spatial SOMA objects, including MultiscaleImage, PointCloudDataFrame, and GeometryDataFrame.
By the end of this tutorial, you’ll understand how to:
- Define a coordinate space.
- Associate coordinate spaces with spatial objects.
- Create and use coordinate transformations.
Setup
First, import the necessary libraries:
Define the TileDB Cloud SaaS URI for a spatial SOMA experiment containing a 10X Visium generated from a mouse brain coronal section.
Open the experiment in read mode:
Create and Access Coordinate Spaces
A coordinate space defines the frame of reference for your spatial data. Think of it as the “grid” or “axes” upon which your data points, images, or shapes are positioned. Each coordinate space has a set of named axes, and each axis has a defined unit of measurement. This information is stored as metadata and is distinct from any coordinates for data located on the coordinate system.
This section demonstrates how to create coordinate spaces in TileDB-SOMA.
The most common scenario is a 2D space, often representing the X and Y dimensions of an image or tissue section. A 2D space with axes named “x” and “y”, using “pixels” as the unit, can be created as follows:
The coordinate space defines the meaning of the coordinates, but it doesn’t store the coordinate values themselves. The actual values are stored within the spatial objects like PointCloudDataFrame, GeometryDataFrame, or DenseNDArray within a MultiscaleImage.
The coordinate spaces are stored as metadata on the underlying TileDB groups and arrays. They are accessible via the coordinate_space attribute of any SOMA spatial object. The coordinate space of the scene in the experiment can be accessed as follows:
Create Spatial Objects with Coordinate Spaces
Now that you know how to define coordinate spaces, this section shows how to associate them with the actual spatial data objects in TileDB-SOMA. You will primarily use the PointCloudDataFrame for these examples, as it’s the most straightforward to visualize, but the same principles apply to GeometryDataFrame and MultiscaleImage.
A small PointCloudDataFrame can be created to represent a few points in a 2D space. The coords2d object defined earlier (with “x” and “y” axes in pixels) will be used.
Now open the PointCloudDataFrame and access the coordinate space information:
The output confirms that the PointCloudDataFrame is associated with the 2D coordinate space defined earlier.
Apply Coordinate Transforms
Coordinate transforms are essential for relating data that exists in different coordinate spaces. A coordinate transform defines a mapping from one coordinate space to another. In TileDB-SOMA, transforms are applied to data when you read it. They are not stored as part of the data itself. This allows the data to be written on a native coordinate system but read in other coordinate systems.
To prove this, you will project both the Visium spots and images to a common coordinate space. First, retrieve the coordinate space of from the SOMAScene accessed earlier:
Retrieve the coordinate transform from the scene’s coordinate space to the PointCloudDataFrame’s coordinate space.
This returns an IdentityTransform, because the PointCloudDataFrame’s coordinate space is the same as the scene’s coordinate space.
Next retrieve the coordinate transform from the scene’s coordinate space to the MultiscaleImage’s coordinate space.
Here, TileDB-SOMA returns a ScaleTransform, because the MultiscaleImage’s coordinate space was downsampled relative to the full resolution image used to map the Visium spots.
You can use these transforms to project the Visium spots onto a region of interest in the high-resolution image. This will require you to do the following:
- Read the region from the high-resolution level of the
MultiScaleImage. - Read the same region from the
PointCloudDataFramestoring the spot locations. - Use the transformation from the
MultiscaleImageto scale align the spot locations with the image.
First, specify the region of interest that encompasses the hippocampus.
Use the bounding box to perform a spatial query on the loc dataframe to get the spots within the region of interest.
Now, use the read_spatial_region() method to load only the part of the image that has the hippocampus. When you pass the ScaleTransform object to the region_transform argument it automatically scales the region selected to the downsampled resolution.
This returns a SpatialRead object that includes both the image data and the coordinate transform that scales and translates the returned data to the original coordinate space you queried. You can use the inverse of this transformation to convert the spot data into the coordinate space of the image data. Underneath the hood, the transforms are accessible directly as matrices:
You can use this matrix to manually project the data from the spot dataframe to the hires image’s resolution.
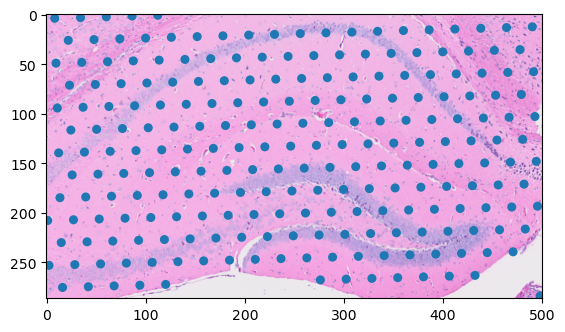
And now, you can plot the spots and image data together.
radius = scene.obsl["loc"].metadata["soma_geometry"]
spot_patches = PatchCollection(
[
mplp.Ellipse(
(scale_x * row["x"] + offset_x, scale_y * row["y"] + offset_y),
width=radius * scale_x,
height=radius * scale_y,
fill=False,
alpha=0.8,
)
for _, row in region_spots.iterrows()
]
)
fig, ax = plt.subplots()
ax.imshow(hires_read.data)
ax.add_collection(spot_patches)
plt.show()