import os
import shutil
import numpy
import PIL
import tiledb
import torch
from tiledb.bioimg.converters.ome_tiff import OMETiffConverter
from tiledb.ml.readers.pytorch import PyTorchTileDBDataLoader
from tiledb.ml.readers.types import ArrayParams
root_dir = os.path.expanduser("~/tiledb-bioimg-chunked-ingestion")
if os.path.exists(root_dir):
shutil.rmtree(root_dir)
os.makedirs(root_dir)Analyze Biomedical Images with PyTorch
biomedical imaging
life sciences
tutorials
machine learning
pytorch
Learn how to use TileDB-BioImaging with PyTorch.
In this tutorial, you will delve into the practical application of deep learning techniques, specifically edge detection, to analyze biomedical images. Using the versatile PyTorch framework, you will construct and train a model capable of identifying crucial edges within these images.
Note
To get the most out of this tutorial, some familiarity with machine learning concepts is recommended. If you’d like a refresher or deeper dive into how TileDB supports ML workflows, check out the Machine Learning section of Academy. It covers topics like storing, querying, and managing ML models efficiently, and how to integrate with other TileDB functionalities.
Warning
This tutorial requires you to run it locally and needs TileDB-Py version 0.33.5 or later and TileDB-ML version 0.9.7 or later.
Start by importing the modules you’ll need in this tutorial and creating a directory to hold the data.
Next, retrieve the image you’ll use for edge detection.
Ingest the image into TileDB.
Now inspect the image to ensure it was ingested correctly.
import matplotlib.pylab as pylab
img_grp = tiledb.Group(data_dest, "r")
with tiledb.open(img_grp[0].uri) as A:
# Transpose from C,X,Y to X,Y,C
image_numpy = A[:]["intensity"].transpose((1, 2, 0))
pylab.imshow(image_numpy)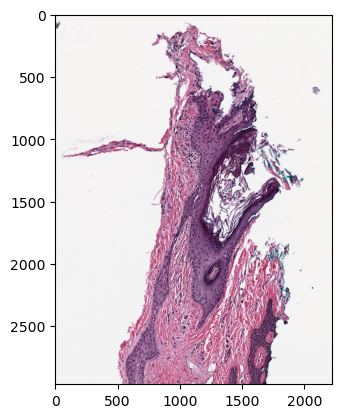
After that, configure PyTorch and define some variables you’ll use for the ML model.
You can design your own edge detection model, but for this example, you will use the following open source PyTorch edge detection model.
Note
You can store your ML models alongside your biomedical images in TileDB. Check out the Machine Learning tutorials to get started.
Using TileDB’s dataloaders, you can fetch your images into the framework’s compatible input format.
The estimation function will forward the input data into the model.
After the model finishes running on the data, you can render the output and visualize the results of the edge detection model:
PIL.Image.fromarray(
(edge_detection.clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, 0] * 255.0).astype(
numpy.uint8
)
).resize((250, 300), PIL.Image.LANCZOS)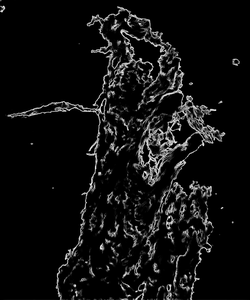
Clean up in the end by removing the data directory.